 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations
Feb 27, 2024



Large-scale recommendation systems are characterized by their reliance on high cardinality, heterogeneous features and the need to handle tens of billions of user actions on a daily basis. Despite being trained on huge volume of data with thousands of features, most Deep Learning Recommendation Models (DLRMs) in industry fail to scale with compute. Inspired by success achieved by Transformers in language and vision domains, we revisit fundamental design choices in recommendation systems. We reformulate recommendation problems as sequential transduction tasks within a generative modeling framework (``Generative Recommenders''), and propose a new architecture, HSTU, designed for high cardinality, non-stationary streaming recommendation data. HSTU outperforms baselines over synthetic and public datasets by up to 65.8\% in NDCG, and is 5.3x to 15.2x faster than FlashAttention2-based Transformers on 8192 length sequences. HSTU-based Generative Recommenders, with 1.5 trillion parameters, improve metrics in online A/B tests by 12.4\% and have been deployed on multiple surfaces of a large internet platform with billions of users. More importantly, the model quality of Generative Recommenders empirically scales as a power-law of training compute across three orders of magnitude, up to GPT-3/LLaMa-2 scale, which reduces carbon footprint needed for future model developments, and further paves the way for the first foundational models in recommendations.
Synthesis of Stabilizing Recurrent Equilibrium Network Controllers
Mar 31, 2022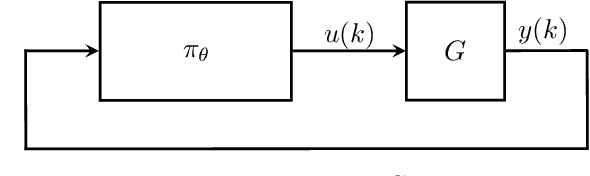
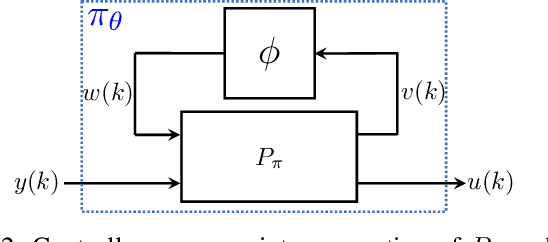
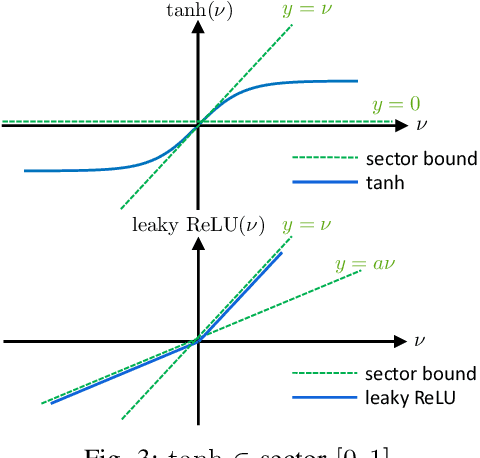
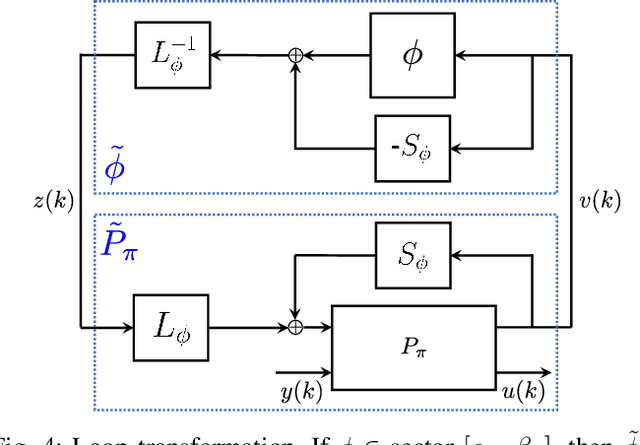
We propose a parameterization of a nonlinear dynamic controller based on the recurrent equilibrium network, a generalization of the recurrent neural network. We derive constraints on the parameterization under which the controller guarantees exponential stability of a partially observed dynamical system with sector-bounded nonlinearities. Finally, we present a method to synthesize this controller using projected policy gradient methods to maximize a reward function with arbitrary structure. The projection step involves the solution of convex optimization problems. We demonstrate the proposed method with simulated examples of controlling nonlinear plants, including plants modeled with neural networks.
Recurrent Neural Network Controllers Synthesis with Stability Guarantees for Partially Observed Systems
Sep 08, 2021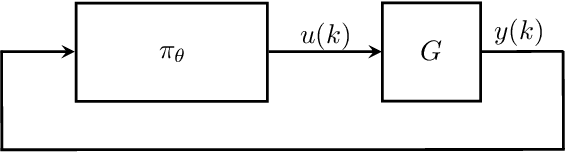
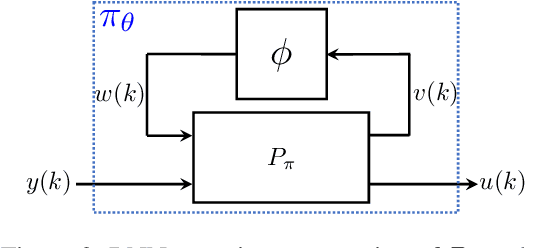
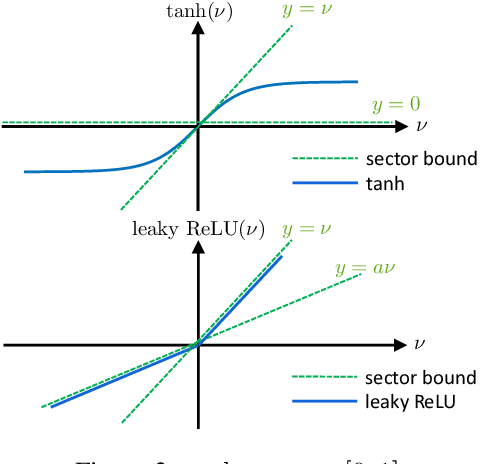
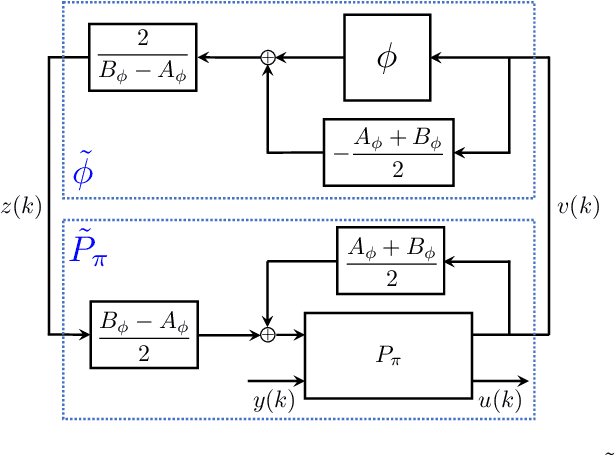
Neural network controllers have become popular in control tasks thanks to their flexibility and expressivity. Stability is a crucial property for safety-critical dynamical systems, while stabilization of partially observed systems, in many cases, requires controllers to retain and process long-term memories of the past. We consider the important class of recurrent neural networks (RNN) as dynamic controllers for nonlinear uncertain partially-observed systems, and derive convex stability conditions based on integral quadratic constraints, S-lemma and sequential convexification. To ensure stability during the learning and control process, we propose a projected policy gradient method that iteratively enforces the stability conditions in the reparametrized space taking advantage of mild additional information on system dynamics. Numerical experiments show that our method learns stabilizing controllers while using fewer samples and achieving higher final performance compared with policy gradient.
Implicit Graph Neural Networks
Sep 14, 2020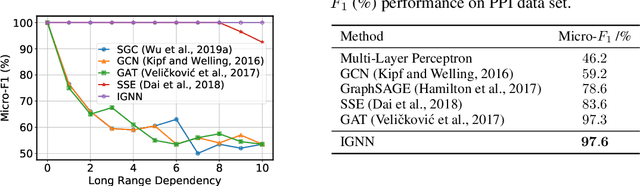
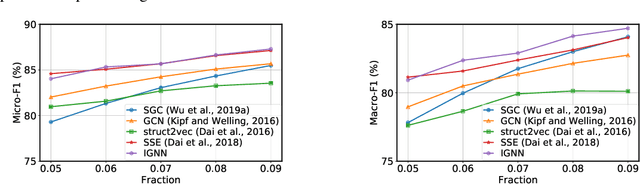
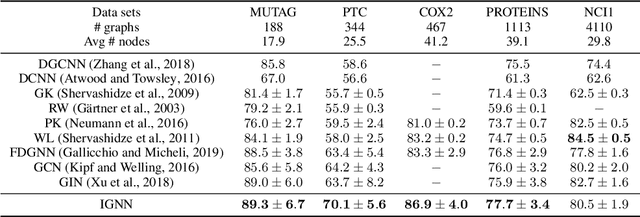
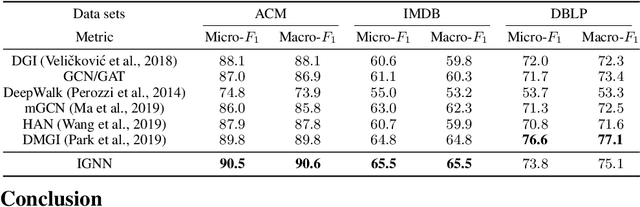
Graph Neural Networks (GNNs) are widely used deep learning models that learn meaningful representations from graph-structured data. Due to the finite nature of the underlying recurrent structure, current GNN methods may struggle to capture long-range dependencies in underlying graphs. To overcome this difficulty, we propose a graph learning framework, called Implicit Graph Neural Networks (IGNN), where predictions are based on the solution of a fixed-point equilibrium equation involving implicitly defined "state" vectors. We use the Perron-Frobenius theory to derive sufficient conditions that ensure well-posedness of the framework. Leveraging implicit differentiation, we derive a tractable projected gradient descent method to train the framework. Experiments on a comprehensive range of tasks show that IGNNs consistently capture long-range dependencies and outperform the state-of-the-art GNN models.
Implicit Deep Learning
Aug 22, 2019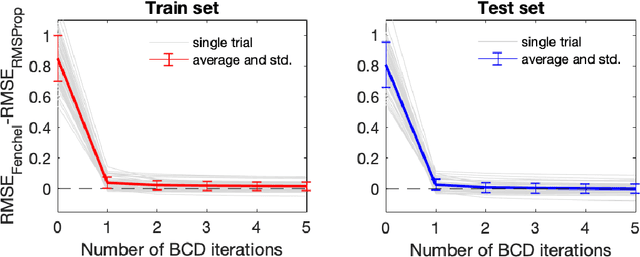
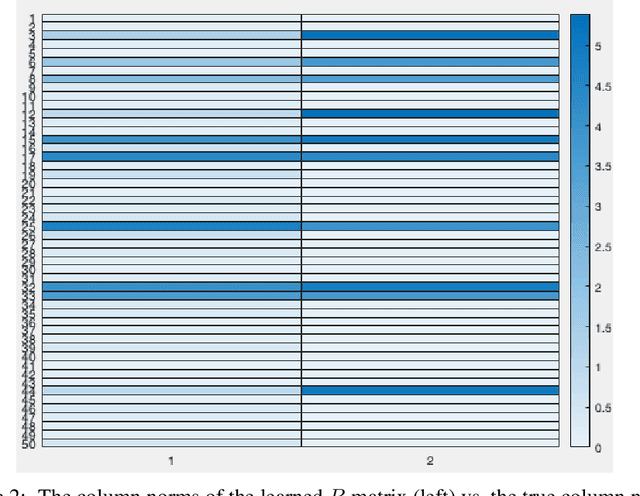
We define a new class of "implicit" deep learning prediction rules that generalize the recursive rules of feedforward neural networks. These models are based on the solution of a fixed-point equation involving a single a vector of hidden features, which is thus only implicitly defined. The new framework greatly simplifies the notation of deep learning, and opens up new possibilities, in terms of novel architectures and algorithms, robustness analysis and design, interpretability, sparsity, and network architecture optimization.
Fenchel Lifted Networks: A Lagrange Relaxation of Neural Network Training
Nov 20, 2018
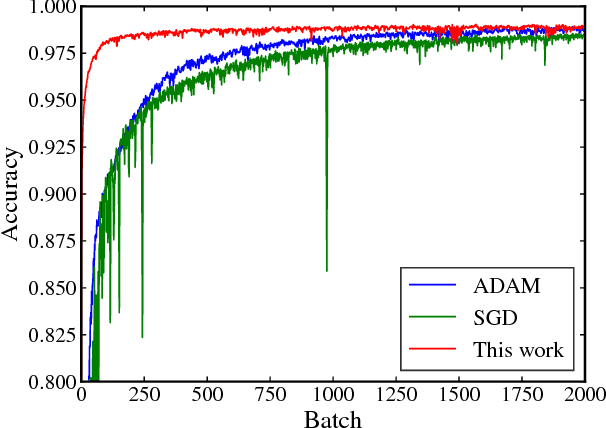

Despite the recent successes of deep neural networks, the corresponding training problem remains highly non-convex and difficult to optimize. Classes of models have been proposed that introduce greater structure to the objective function at the cost of lifting the dimension of the problem. However, these lifted methods sometimes perform poorly compared to traditional neural networks. In this paper, we introduce a new class of lifted models, Fenchel lifted networks, that enjoy the same benefits as previous lifted models, without suffering a degradation in performance over classical networks. Our model represents activation functions as equivalent biconvex constraints and uses Lagrange Multipliers to arrive at a rigorous lower bound of the traditional neural network training problem. This model is efficiently trained using block-coordinate descent and is parallelizable across data points and/or layers. We compare our model against standard fully connected and convolutional networks and show that we are able to match or beat their performance.
Context-Aware Policy Reuse
Jun 28, 2018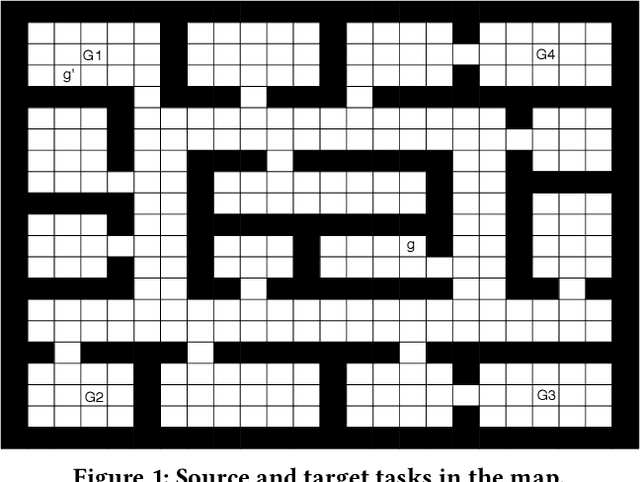
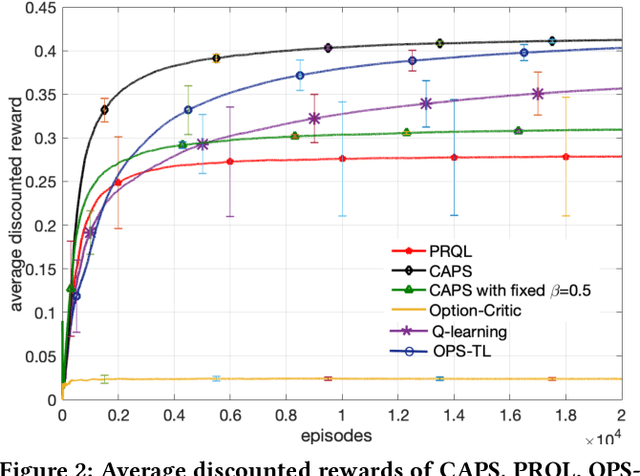

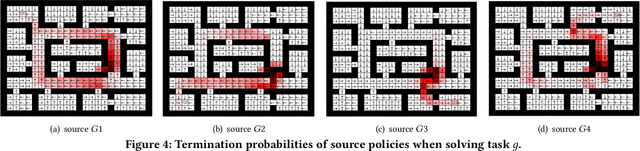
Transfer learning can greatly speed up reinforcement learning for a new task by leveraging policies of relevant tasks. Existing works of policy reuse either focus on only selecting a single best source policy for transfer without considering contexts, or cannot guarantee to learn an optimal policy for a target task. To improve transfer efficiency and guarantee optimality, we develop a novel policy reuse method, called Context-Aware Policy reuSe (CAPS), that enables multi-policy transfer. Our method learns when and which source policy is best for reuse, as well as when to terminate its reuse. CAPS provides theoretical guarantees in convergence and optimality for both source policy selection and target task learning. Empirical results on a grid-based navigation domain and the Pygame Learning Environment demonstrate that CAPS significantly outperforms other state-of-the-art policy reuse methods.