 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFenchel Lifted Networks: A Lagrange Relaxation of Neural Network Training
Paper and Code
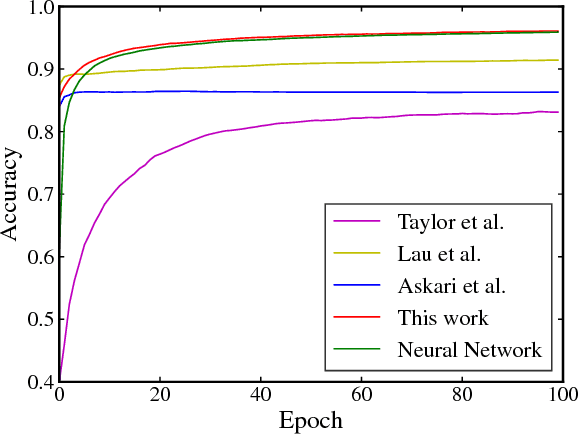
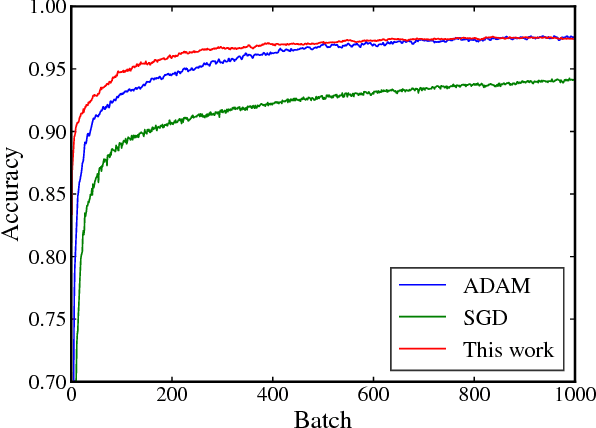
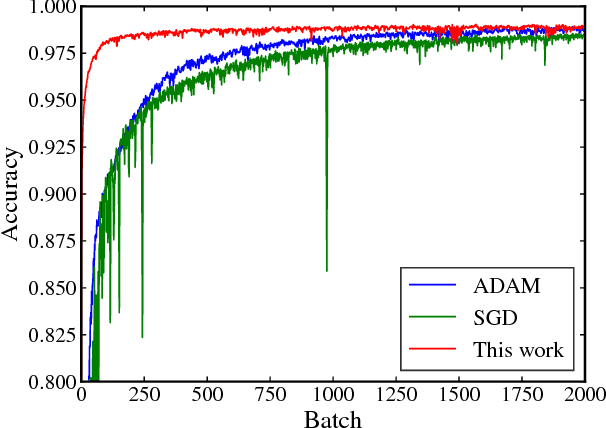

Despite the recent successes of deep neural networks, the corresponding training problem remains highly non-convex and difficult to optimize. Classes of models have been proposed that introduce greater structure to the objective function at the cost of lifting the dimension of the problem. However, these lifted methods sometimes perform poorly compared to traditional neural networks. In this paper, we introduce a new class of lifted models, Fenchel lifted networks, that enjoy the same benefits as previous lifted models, without suffering a degradation in performance over classical networks. Our model represents activation functions as equivalent biconvex constraints and uses Lagrange Multipliers to arrive at a rigorous lower bound of the traditional neural network training problem. This model is efficiently trained using block-coordinate descent and is parallelizable across data points and/or layers. We compare our model against standard fully connected and convolutional networks and show that we are able to match or beat their performance.