Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Deep Learning
Paper and Code
Aug 22, 2019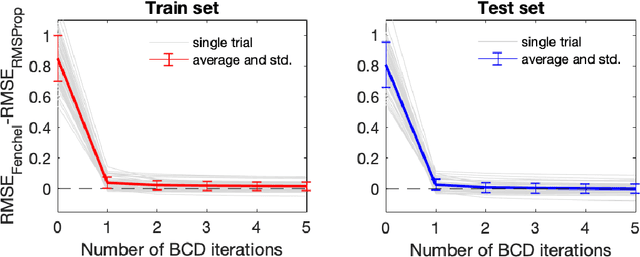
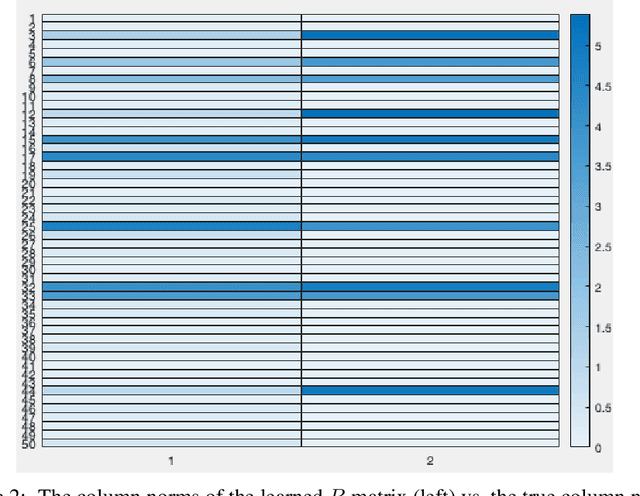
We define a new class of "implicit" deep learning prediction rules that generalize the recursive rules of feedforward neural networks. These models are based on the solution of a fixed-point equation involving a single a vector of hidden features, which is thus only implicitly defined. The new framework greatly simplifies the notation of deep learning, and opens up new possibilities, in terms of novel architectures and algorithms, robustness analysis and design, interpretability, sparsity, and network architecture optimization.
View paper on