 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Stable Multi-Agent Routing with Bounded-Delay Adversaries in the Decision Loop
Apr 01, 2025In this work, we are interested in studying multi-agent routing settings, where adversarial agents are part of the assignment and decision loop, degrading the performance of the fleet by incurring bounded delays while servicing pickup-and-delivery requests. Specifically, we are interested in characterizing conditions on the fleet size and the proportion of adversarial agents for which a routing policy remains stable, where stability for a routing policy is achieved if the number of outstanding requests is uniformly bounded over time. To obtain this characterization, we first establish a threshold on the proportion of adversarial agents above which previously stable routing policies for fully cooperative fleets are provably unstable. We then derive a sufficient condition on the fleet size to recover stability given a maximum proportion of adversarial agents. We empirically validate our theoretical results on a case study on autonomous taxi routing, where we consider transportation requests from real San Francisco taxicab data.
Pro-Routing: Proactive Routing of Autonomous Multi-Capacity Robots for Pickup-and-Delivery Tasks
Mar 31, 2025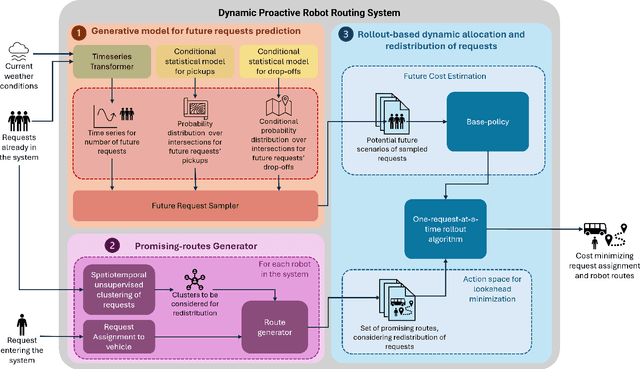
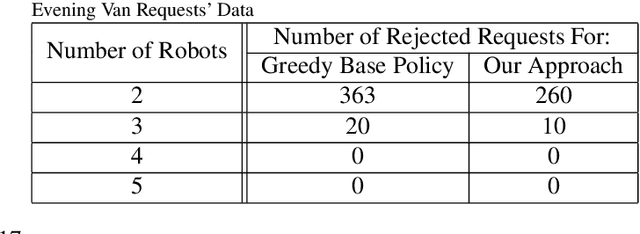
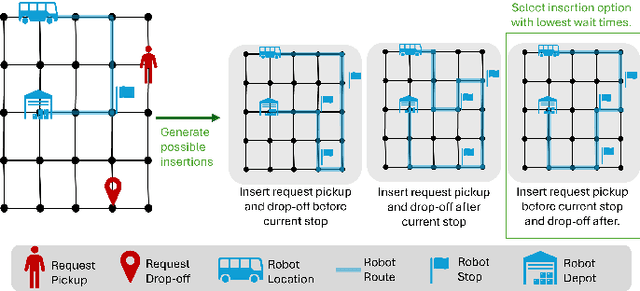
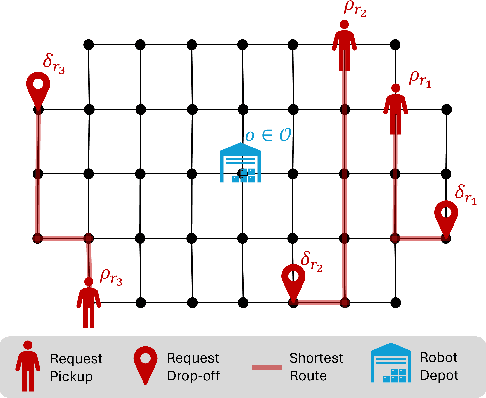
We consider a multi-robot setting, where we have a fleet of multi-capacity autonomous robots that must service spatially distributed pickup-and-delivery requests with fixed maximum wait times. Requests can be either scheduled ahead of time or they can enter the system in real-time. In this setting, stability for a routing policy is defined as the cost of the policy being uniformly bounded over time. Most previous work either solve the problem offline to theoretically maintain stability or they consider dynamically arriving requests at the expense of the theoretical guarantees on stability. In this paper, we aim to bridge this gap by proposing a novel proactive rollout-based routing framework that adapts to real-time demand while still provably maintaining the stability of the learned routing policy. We derive provable stability guarantees for our method by proposing a fleet sizing algorithm that obtains a sufficiently large fleet that ensures stability by construction. To validate our theoretical results, we consider a case study on real ride requests for Harvard's evening Van System. We also evaluate the performance of our framework using the currently deployed smaller fleet size. In this smaller setup, we compare against the currently deployed routing algorithm, greedy heuristics, and Monte-Carlo-Tree-Search-based algorithms. Our empirical results show that our framework maintains stability when we use the sufficiently large fleet size found in our theoretical results. For the smaller currently deployed fleet size, our method services 6% more requests than the closest baseline while reducing median passenger wait times by 33%.
Data-Efficient Multi-Agent Spatial Planning with LLMs
Feb 26, 2025
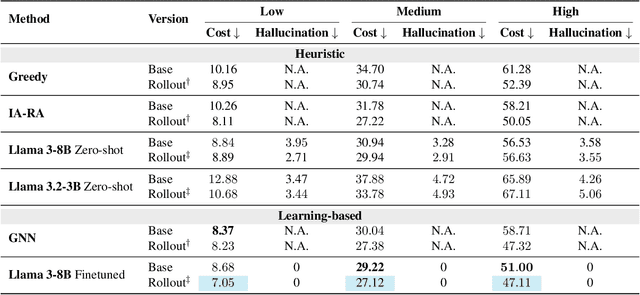
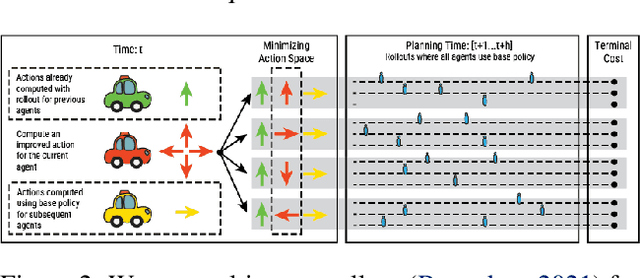
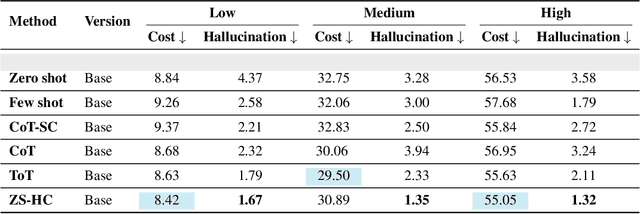
In this project, our goal is to determine how to leverage the world-knowledge of pretrained large language models for efficient and robust learning in multiagent decision making. We examine this in a taxi routing and assignment problem where agents must decide how to best pick up passengers in order to minimize overall waiting time. While this problem is situated on a graphical road network, we show that with the proper prompting zero-shot performance is quite strong on this task. Furthermore, with limited fine-tuning along with the one-at-a-time rollout algorithm for look ahead, LLMs can out-compete existing approaches with 50 times fewer environmental interactions. We also explore the benefits of various linguistic prompting approaches and show that including certain easy-to-compute information in the prompt significantly improves performance. Finally, we highlight the LLM's built-in semantic understanding, showing its ability to adapt to environmental factors through simple prompts.
Tiny Reinforcement Learning for Quadruped Locomotion using Decision Transformers
Feb 20, 2024Resource-constrained robotic platforms are particularly useful for tasks that require low-cost hardware alternatives due to the risk of losing the robot, like in search-and-rescue applications, or the need for a large number of devices, like in swarm robotics. For this reason, it is crucial to find mechanisms for adapting reinforcement learning techniques to the constraints imposed by lower computational power and smaller memory capacities of these ultra low-cost robotic platforms. We try to address this need by proposing a method for making imitation learning deployable onto resource-constrained robotic platforms. Here we cast the imitation learning problem as a conditional sequence modeling task and we train a decision transformer using expert demonstrations augmented with a custom reward. Then, we compress the resulting generative model using software optimization schemes, including quantization and pruning. We test our method in simulation using Isaac Gym, a realistic physics simulation environment designed for reinforcement learning. We empirically demonstrate that our method achieves natural looking gaits for Bittle, a resource-constrained quadruped robot. We also run multiple simulations to show the effects of pruning and quantization on the performance of the model. Our results show that quantization (down to 4 bits) and pruning reduce model size by around 30\% while maintaining a competitive reward, making the model deployable in a resource-constrained system.
Approximate Multiagent Reinforcement Learning for On-Demand Urban Mobility Problem on a Large Map (extended version)
Nov 02, 2023
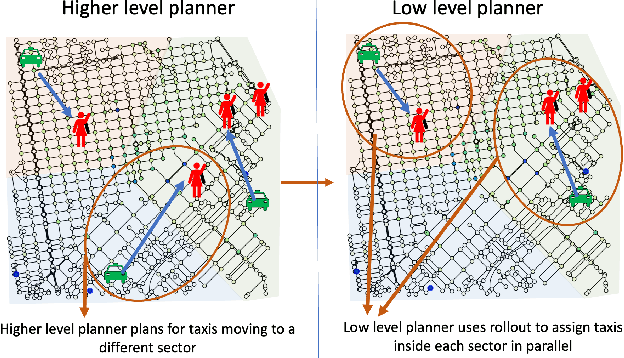
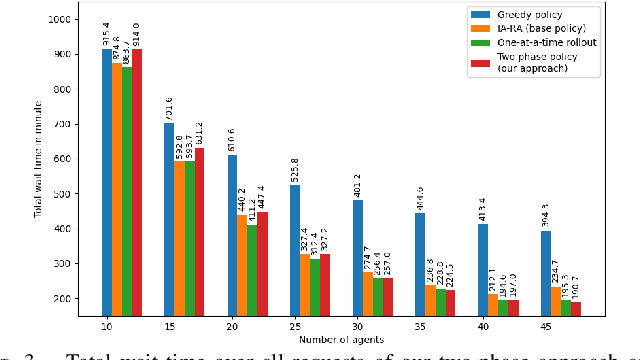
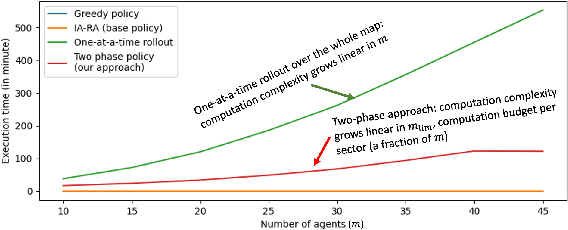
In this paper, we focus on the autonomous multiagent taxi routing problem for a large urban environment where the location and number of future ride requests are unknown a-priori, but follow an estimated empirical distribution. Recent theory has shown that if a base policy is stable then a rollout-based algorithm with such a base policy produces a near-optimal stable policy. Although, rollout-based approaches are well-suited for learning cooperative multiagent policies with considerations for future demand, applying such methods to a large urban environment can be computationally expensive. Large environments tend to have a large volume of requests, and hence require a large fleet of taxis to guarantee stability. In this paper, we aim to address the computational bottleneck of multiagent (one-at-a-time) rollout, where the computational complexity grows linearly in the number of agents. We propose an approximate one-at-a-time rollout-based two-phase algorithm that reduces the computational cost, while still achieving a stable near-optimal policy. Our approach partitions the graph into sectors based on the predicted demand and an user-defined maximum number of agents that can be planned for using the one-at-a-time rollout approach. The algorithm then applies instantaneous assignment (IA) for re-balancing taxis across sectors and a sector-wide one-at-a-time rollout algorithm that is executed in parallel for each sector. We characterize the number of taxis $m$ that is sufficient for IA base policy to be stable, and derive a necessary condition on $m$ as time goes to infinity. Our numerical results show that our approach achieves stability for an $m$ that satisfies the theoretical conditions. We also empirically demonstrate that our proposed two-phase algorithm has comparable performance to the one-at-a-time rollout over the entire map, but with significantly lower runtimes.
Surge Routing: Event-informed Multiagent Reinforcement Learning for Autonomous Rideshare
Jul 05, 2023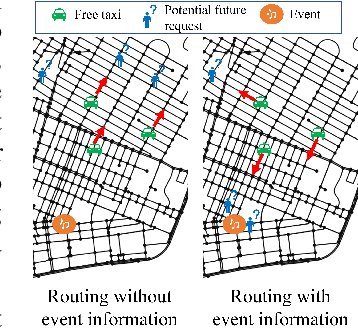

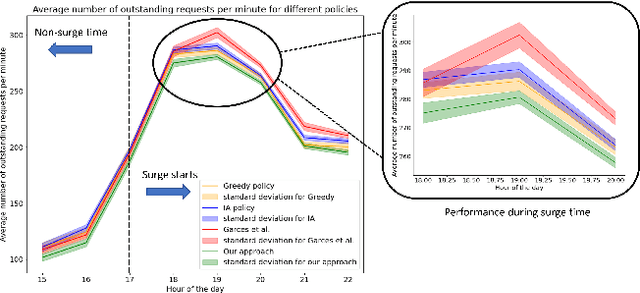
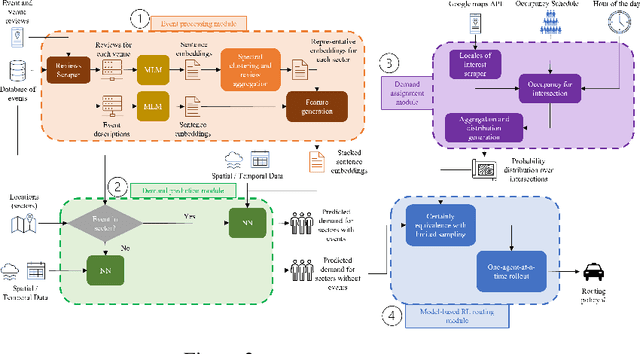
Large events such as conferences, concerts and sports games, often cause surges in demand for ride services that are not captured in average demand patterns, posing unique challenges for routing algorithms. We propose a learning framework for an autonomous fleet of taxis that scrapes event data from the internet to predict and adapt to surges in demand and generates cooperative routing and pickup policies that service a higher number of requests than other routing protocols. We achieve this through a combination of (i) an event processing framework that scrapes the internet for event information and generates dense vector representations that can be used as input features for a neural network that predicts demand; (ii) a two neural network system that predicts hourly demand over the entire map, using these dense vector representations; (iii) a probabilistic approach that leverages locale occupancy schedules to map publicly available demand data over sectors to discretized street intersections; and finally, (iv) a scalable model-based reinforcement learning framework that uses the predicted demand over intersections to anticipate surges and route taxis using one-agent-at-a-time rollout with limited sampling certainty equivalence. We learn routing and pickup policies using real NYC ride share data for 2022 and information for more than 2000 events across 300 unique venues in Manhattan. We test our approach with a fleet of 100 taxis on a map with 38 different sectors (2235 street intersections). Our experimental results demonstrate that our method obtains routing policies that service $6$ more requests on average per minute (around $360$ more requests per hour) than other model-based RL frameworks and other classical algorithms in operations research when dealing with surge demand conditions.
Multiagent Reinforcement Learning for Autonomous Routing and Pickup Problem with Adaptation to Variable Demand
Nov 28, 2022



We derive a learning framework to generate routing/pickup policies for a fleet of vehicles tasked with servicing stochastically appearing requests on a city map. We focus on policies that 1) give rise to coordination amongst the vehicles, thereby reducing wait times for servicing requests, 2) are non-myopic, considering a-priori unknown potential future requests, and 3) can adapt to changes in the underlying demand distribution. Specifically, we are interested in adapting to fluctuations of actual demand conditions in urban environments, such as on-peak vs. off-peak hours. We achieve this through a combination of (i) online play, a lookahead optimization method that improves the performance of rollout methods via an approximate policy iteration step, and (ii) an offline approximation scheme that allows for adapting to changes in the underlying demand model. In particular, we achieve adaptivity of our learned policy to different demand distributions by quantifying a region of validity using the q-valid radius of a Wasserstein Ambiguity Set. We propose a mechanism for switching the originally trained offline approximation when the current demand is outside the original validity region. In this case, we propose to use an offline architecture, trained on a historical demand model that is closer to the current demand in terms of Wasserstein distance. We learn routing and pickup policies over real taxicab requests in downtown San Francisco with high variability between on-peak and off-peak hours, demonstrating the ability of our method to adapt to real fluctuation in demand distributions. Our numerical results demonstrate that our method outperforms rollout-based reinforcement learning, as well as several benchmarks based on classical methods from the field of operations research.