 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Recognition in the Wild
May 30, 2025To enable egocentric contextual AI in always-on smart glasses, it is crucial to be able to keep a record of the user's interactions with the world, including during reading. In this paper, we introduce a new task of reading recognition to determine when the user is reading. We first introduce the first-of-its-kind large-scale multimodal Reading in the Wild dataset, containing 100 hours of reading and non-reading videos in diverse and realistic scenarios. We then identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task, and present a flexible transformer model that performs the task using these modalities, either individually or combined. We show that these modalities are relevant and complementary to the task, and investigate how to efficiently and effectively encode each modality. Additionally, we show the usefulness of this dataset towards classifying types of reading, extending current reading understanding studies conducted in constrained settings to larger scale, diversity and realism. Code, model, and data will be public.
Ocular Authentication: Fusion of Gaze and Periocular Modalities
May 26, 2025
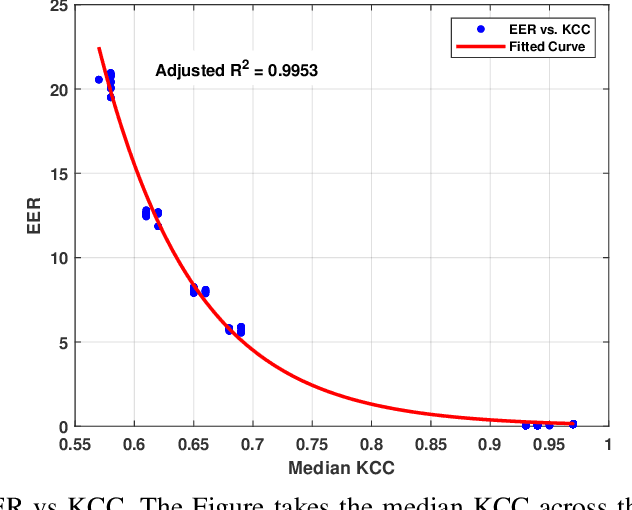


This paper investigates the feasibility of fusing two eye-centric authentication modalities-eye movements and periocular images-within a calibration-free authentication system. While each modality has independently shown promise for user authentication, their combination within a unified gaze-estimation pipeline has not been thoroughly explored at scale. In this report, we propose a multimodal authentication system and evaluate it using a large-scale in-house dataset comprising 9202 subjects with an eye tracking (ET) signal quality equivalent to a consumer-facing virtual reality (VR) device. Our results show that the multimodal approach consistently outperforms both unimodal systems across all scenarios, surpassing the FIDO benchmark. The integration of a state-of-the-art machine learning architecture contributed significantly to the overall authentication performance at scale, driven by the model's ability to capture authentication representations and the complementary discriminative characteristics of the fused modalities.
Eye Gaze as a Signal for Conveying User Attention in Contextual AI Systems
Jan 23, 2025Advanced multimodal AI agents can now collaborate with users to solve challenges in the world. We explore eye tracking's role in such interaction to convey a user's attention relative to the physical environment. We hypothesize that this knowledge improves contextual understanding for AI agents. By observing hours of human-object interactions, we first measure the relationship between an eye tracker's signal quality and its ability to reliably place gaze on nearby physical objects. We then conduct experiments which relay the user's scanpath history as additional context querying multimodal agents. Our results show that eye tracking provides high value as a user attention signal and can convey information about the user's current task and interests to the agent.
Establishing a Baseline for Gaze-driven Authentication Performance in VR: A Breadth-First Investigation on a Very Large Dataset
Apr 17, 2024



This paper performs the crucial work of establishing a baseline for gaze-driven authentication performance to begin answering fundamental research questions using a very large dataset of gaze recordings from 9202 people with a level of eye tracking (ET) signal quality equivalent to modern consumer-facing virtual reality (VR) platforms. The size of the employed dataset is at least an order-of-magnitude larger than any other dataset from previous related work. Binocular estimates of the optical and visual axes of the eyes and a minimum duration for enrollment and verification are required for our model to achieve a false rejection rate (FRR) of below 3% at a false acceptance rate (FAR) of 1 in 50,000. In terms of identification accuracy which decreases with gallery size, we estimate that our model would fall below chance-level accuracy for gallery sizes of 148,000 or more. Our major findings indicate that gaze authentication can be as accurate as required by the FIDO standard when driven by a state-of-the-art machine learning architecture and a sufficiently large training dataset.
Performance of data-driven inner speech decoding with same-task EEG-fMRI data fusion and bimodal models
Jun 19, 2023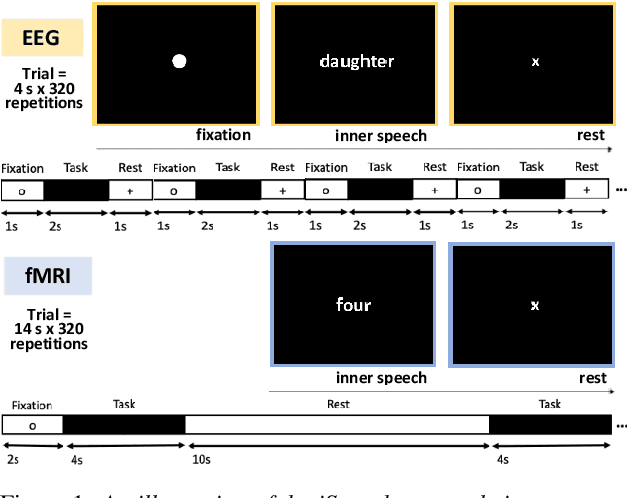
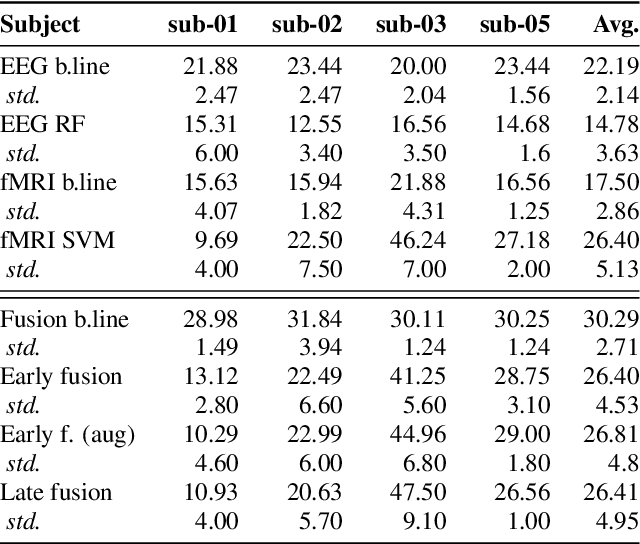
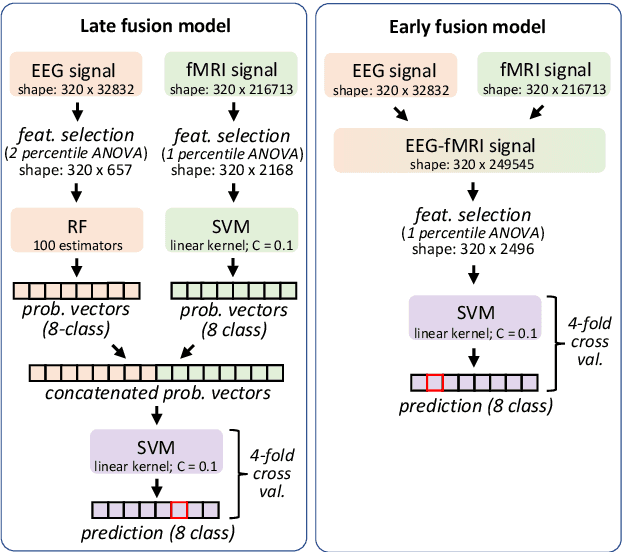
Decoding inner speech from the brain signal via hybridisation of fMRI and EEG data is explored to investigate the performance benefits over unimodal models. Two different bimodal fusion approaches are examined: concatenation of probability vectors output from unimodal fMRI and EEG machine learning models, and data fusion with feature engineering. Same task inner speech data are recorded from four participants, and different processing strategies are compared and contrasted to previously-employed hybridisation methods. Data across participants are discovered to encode different underlying structures, which results in varying decoding performances between subject-dependent fusion models. Decoding performance is demonstrated as improved when pursuing bimodal fMRI-EEG fusion strategies, if the data show underlying structure.