 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUR2KiD: Unifying Retrieval, Keypoint Detection, and Keypoint Description without Local Correspondence Supervision
Paper and Code
Jan 20, 2020
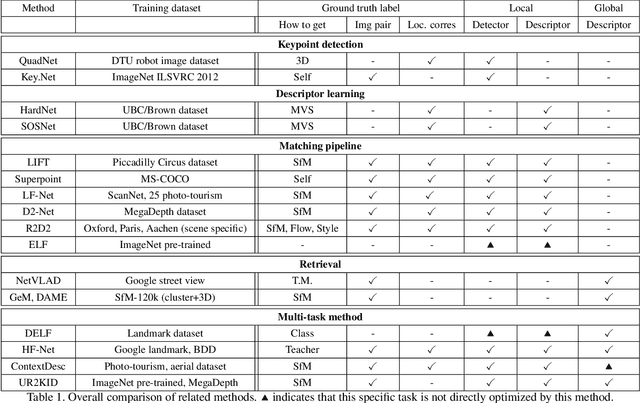

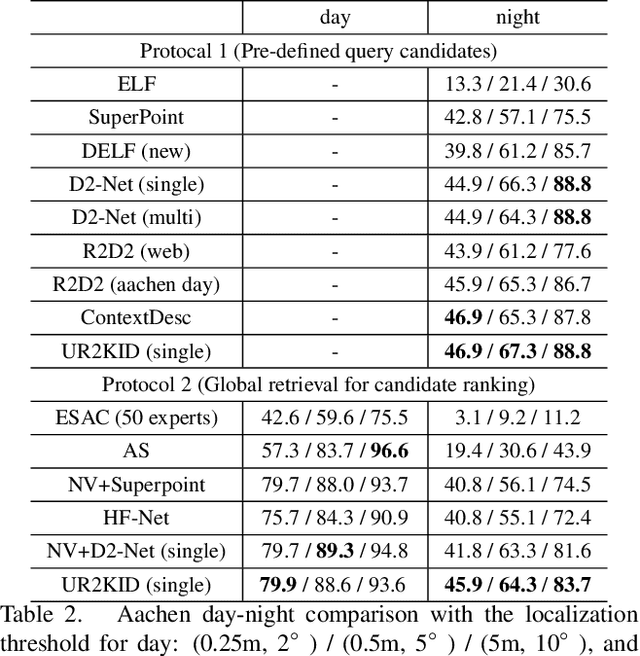
In this paper, we explore how three related tasks, namely keypoint detection, description, and image retrieval can be jointly tackled using a single unified framework, which is trained without the need of training data with point to point correspondences. By leveraging diverse information from sequential layers of a standard ResNet-based architecture, we are able to extract keypoints and descriptors that encode local information using generic techniques such as local activation norms, channel grouping and dropping, and self-distillation. Subsequently, global information for image retrieval is encoded in an end-to-end pipeline, based on pooling of the aforementioned local responses. In contrast to previous methods in local matching, our method does not depend on pointwise/pixelwise correspondences, and requires no such supervision at all i.e. no depth-maps from an SfM model nor manually created synthetic affine transformations. We illustrate that this simple and direct paradigm, is able to achieve very competitive results against the state-of-the-art methods in various challenging benchmark conditions such as viewpoint changes, scale changes, and day-night shifting localization.