 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoxeR: Box-Attention for 2D and 3D Transformers
Paper and Code

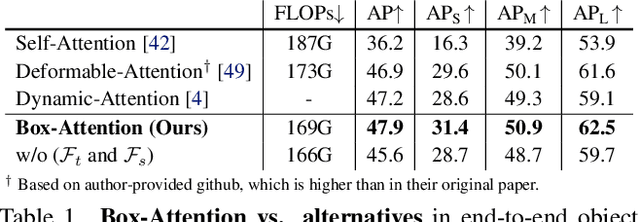
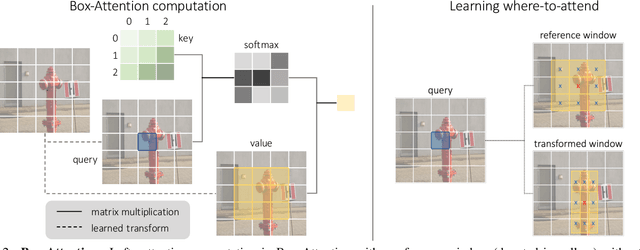

In this paper, we propose a simple attention mechanism, we call Box-Attention. It enables spatial interaction between grid features, as sampled from boxes of interest, and improves the learning capability of transformers for several vision tasks. Specifically, we present BoxeR, short for Box Transformer, which attends to a set of boxes by predicting their transformation from a reference window on an input feature map. The BoxeR computes attention weights on these boxes by considering its grid structure. Notably, BoxeR-2D naturally reasons about box information within its attention module, making it suitable for end-to-end instance detection and segmentation tasks. By learning invariance to rotation in the box-attention module, BoxeR-3D is capable of generating discriminative information from a bird-eye-view plane for 3D end-to-end object detection. Our experiments demonstrate that the proposed BoxeR-2D achieves better results on COCO detection, and reaches comparable performance with well-established and highly-optimized Mask R-CNN on COCO instance segmentation. BoxeR-3D already obtains a compelling performance for the vehicle category of Waymo Open, without any class-specific optimization. The code will be released.