 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastCAD: Real-Time CAD Retrieval and Alignment from Scans and Videos
Mar 22, 2024



Digitising the 3D world into a clean, CAD model-based representation has important applications for augmented reality and robotics. Current state-of-the-art methods are computationally intensive as they individually encode each detected object and optimise CAD alignments in a second stage. In this work, we propose FastCAD, a real-time method that simultaneously retrieves and aligns CAD models for all objects in a given scene. In contrast to previous works, we directly predict alignment parameters and shape embeddings. We achieve high-quality shape retrievals by learning CAD embeddings in a contrastive learning framework and distilling those into FastCAD. Our single-stage method accelerates the inference time by a factor of 50 compared to other methods operating on RGB-D scans while outperforming them on the challenging Scan2CAD alignment benchmark. Further, our approach collaborates seamlessly with online 3D reconstruction techniques. This enables the real-time generation of precise CAD model-based reconstructions from videos at 10 FPS. Doing so, we significantly improve the Scan2CAD alignment accuracy in the video setting from 43.0% to 48.2% and the reconstruction accuracy from 22.9% to 29.6%.
BoxeR: Box-Attention for 2D and 3D Transformers
Nov 25, 2021
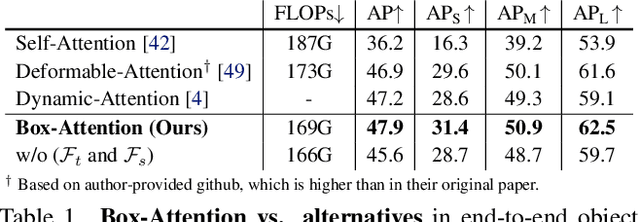
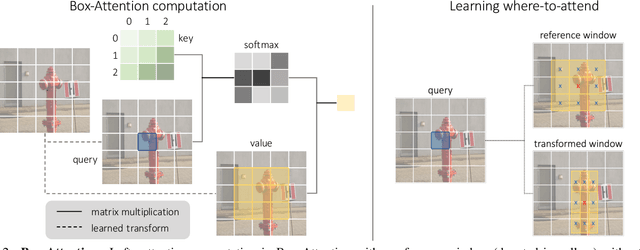

In this paper, we propose a simple attention mechanism, we call Box-Attention. It enables spatial interaction between grid features, as sampled from boxes of interest, and improves the learning capability of transformers for several vision tasks. Specifically, we present BoxeR, short for Box Transformer, which attends to a set of boxes by predicting their transformation from a reference window on an input feature map. The BoxeR computes attention weights on these boxes by considering its grid structure. Notably, BoxeR-2D naturally reasons about box information within its attention module, making it suitable for end-to-end instance detection and segmentation tasks. By learning invariance to rotation in the box-attention module, BoxeR-3D is capable of generating discriminative information from a bird-eye-view plane for 3D end-to-end object detection. Our experiments demonstrate that the proposed BoxeR-2D achieves better results on COCO detection, and reaches comparable performance with well-established and highly-optimized Mask R-CNN on COCO instance segmentation. BoxeR-3D already obtains a compelling performance for the vehicle category of Waymo Open, without any class-specific optimization. The code will be released.
Team Delft's Robot Winner of the Amazon Picking Challenge 2016
Oct 18, 2016
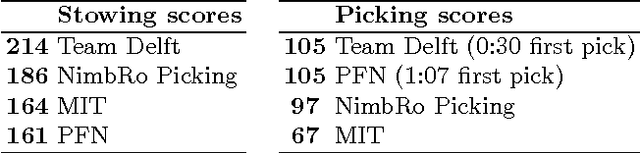

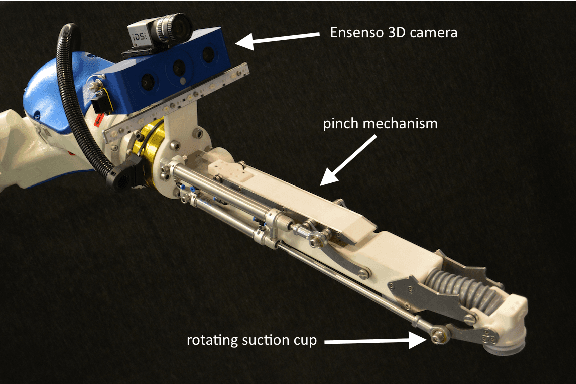
This paper describes Team Delft's robot, which won the Amazon Picking Challenge 2016, including both the Picking and the Stowing competitions. The goal of the challenge is to automate pick and place operations in unstructured environments, specifically the shelves in an Amazon warehouse. Team Delft's robot is based on an industrial robot arm, 3D cameras and a customized gripper. The robot's software uses ROS to integrate off-the-shelf components and modules developed specifically for the competition, implementing Deep Learning and other AI techniques for object recognition and pose estimation, grasp planning and motion planning. This paper describes the main components in the system, and discusses its performance and results at the Amazon Picking Challenge 2016 finals.