 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIFT+: Lightweight Fine-Tuning for Long-Tail Learning
Paper and Code
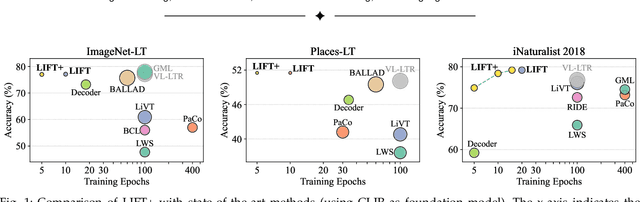
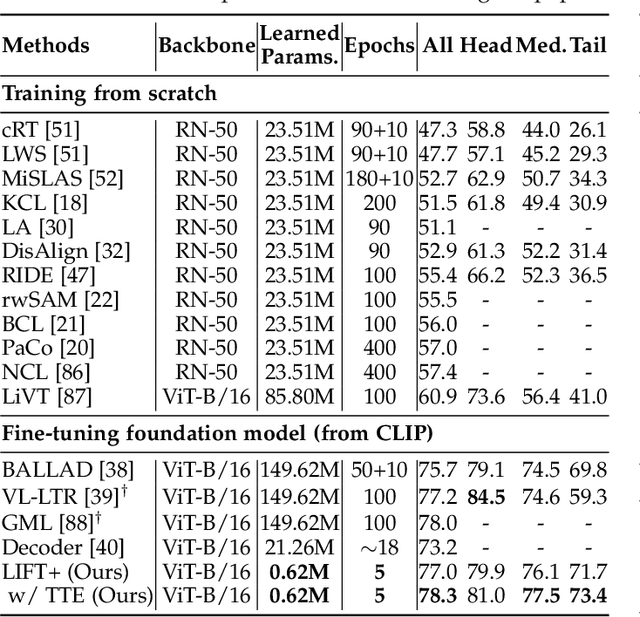
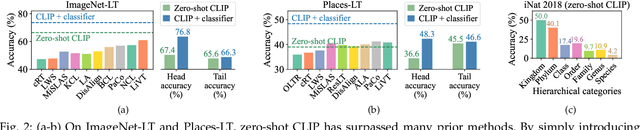
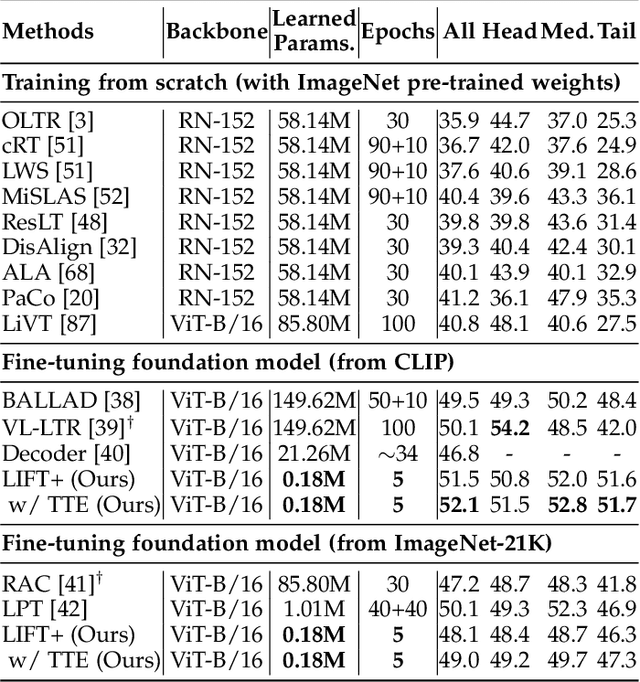
The fine-tuning paradigm has emerged as a prominent approach for addressing long-tail learning tasks in the era of foundation models. However, the impact of fine-tuning strategies on long-tail learning performance remains unexplored. In this work, we disclose that existing paradigms exhibit a profound misuse of fine-tuning methods, leaving significant room for improvement in both efficiency and accuracy. Specifically, we reveal that heavy fine-tuning (fine-tuning a large proportion of model parameters) can lead to non-negligible performance deterioration on tail classes, whereas lightweight fine-tuning demonstrates superior effectiveness. Through comprehensive theoretical and empirical validation, we identify this phenomenon as stemming from inconsistent class conditional distributions induced by heavy fine-tuning. Building on this insight, we propose LIFT+, an innovative lightweight fine-tuning framework to optimize consistent class conditions. Furthermore, LIFT+ incorporates semantic-aware initialization, minimalist data augmentation, and test-time ensembling to enhance adaptation and generalization of foundation models. Our framework provides an efficient and accurate pipeline that facilitates fast convergence and model compactness. Extensive experiments demonstrate that LIFT+ significantly reduces both training epochs (from $\sim$100 to $\leq$15) and learned parameters (less than 1%), while surpassing state-of-the-art approaches by a considerable margin. The source code is available at https://github.com/shijxcs/LIFT-plus.