 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Text-to-Table for Reasoning-Intensive Table QA: Pipeline Design and Benchmarking Insights
May 26, 2025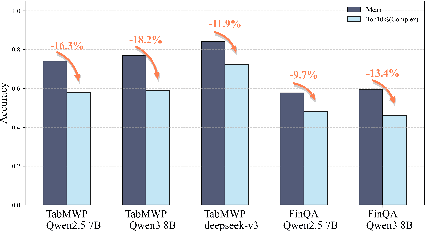
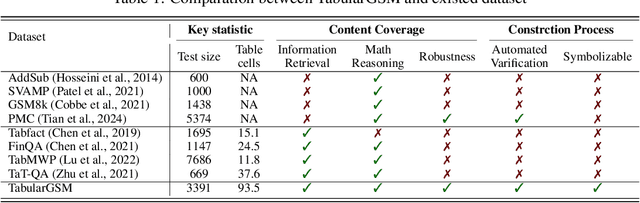
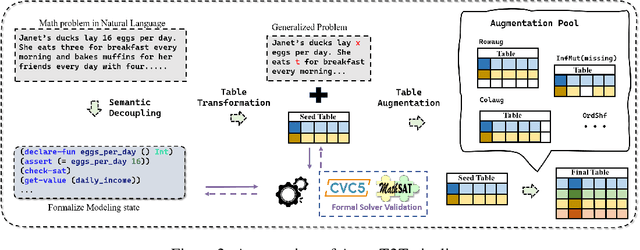

Reasoning with tabular data holds increasing importance in modern applications, yet comprehensive evaluation methodologies for reasoning-intensive Table Question Answering (QA) tasks remain nascent. Existing research is constrained by two primary bottlenecks: 1) Reliance on costly manually annotated real-world data, which is difficult to cover complex reasoning scenarios; 2) The heterogeneity of table structures hinders systematic analysis of the intrinsic mechanisms behind the underperformance of LLMs, especially in reasoning-intensive tasks. To address these issues, we propose an automated generation pipeline AutoT2T that transforms mathematical word problems into table-based reasoning tasks, eliminating the need for manual annotation. The pipeline can generate multiple variants of a table for the same reasoning problem, including noisy versions to support robustness evaluation. Based on this, we construct a new benchmark TabularGSM, which systematically spans a range of table complexities and trap problems. Experimental analyses through AutoT2T and TabularGSM reveal that the tight coupling between reasoning and retrieval or identification processes is a key factor underlying the failure of LLMs in complex Table QA tasks. This highlights the necessity for models to develop synergistic reasoning capabilities in order to perform effectively in complex Table QA tasks.
LawGPT: Knowledge-Guided Data Generation and Its Application to Legal LLM
Feb 10, 2025



Large language models (LLMs), both proprietary and open-source, have demonstrated remarkable capabilities across various natural language processing tasks. However, they face significant limitations in legal reasoning tasks. Proprietary models introduce data privacy risks and high inference costs, while open-source models underperform due to insufficient legal domain training data. To address these limitations, we study data generation for legal reasoning to improve the legal reasoning performance of open-source LLMs with the help of proprietary LLMs. This is challenging due to the lack of legal knowledge in proprietary LLMs and the difficulty in verifying the generated data. We propose KgDG, a knowledge-guided data generation framework for legal reasoning. Our framework enables leveraging legal knowledge to enhance generation diversity and introduces a refinement and verification process to ensure the quality of generated data. Moreover, we expand the generated dataset to further enhance the LLM reasoning capabilities. Using KgDG, we create a synthetic legal reasoning dataset containing 50K high-quality examples. Our trained model LawGPT outperforms existing legal-specific LLMs and achieves performance comparable to proprietary LLMs, demonstrating the effectiveness of KgDG and LawGPT. Our code and resources is publicly available at https://anonymous.4open.science/r/KgDG-45F5 .
Fully Test-time Adaptation for Tabular Data
Dec 14, 2024



Tabular data plays a vital role in various real-world scenarios and finds extensive applications. Although recent deep tabular models have shown remarkable success, they still struggle to handle data distribution shifts, leading to performance degradation when testing distributions change. To remedy this, a robust tabular model must adapt to generalize to unknown distributions during testing. In this paper, we investigate the problem of fully test-time adaptation (FTTA) for tabular data, where the model is adapted using only the testing data. We identify three key challenges: the existence of label and covariate distribution shifts, the lack of effective data augmentation, and the sensitivity of adaptation, which render existing FTTA methods ineffective for tabular data. To this end, we propose the Fully Test-time Adaptation for Tabular data, namely FTAT, which enables FTTA methods to robustly optimize the label distribution of predictions, adapt to shifted covariate distributions, and suit a variety of tasks and models effectively. We conduct comprehensive experiments on six benchmark datasets, which are evaluated using three metrics. The experimental results demonstrate that FTAT outperforms state-of-the-art methods by a margin.