 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Recurrent Dynamics for Test-Time Scalable Latent Reasoning in Looped Language Models
May 26, 2026Looped Language Models (LoopLMs) enable efficient latent reasoning through depth recurrence, yet exhibit unreliable test-time scaling behavior: performance often peaks at a certain iteration depth and then collapses with further recurrence. Through latent dynamics analysis, we find an inherent trade-off between stability and effectiveness in existing architectures and strategies. By conceptualizing reasoning as uncertainty reduction, we propose that convergence toward stable fixed points while preserving effectiveness represents a promising way. To this end, we propose STARS (STAbility-driven Recurrent Scaling), a training framework that constrains latent states to approach asymptotically stable fixed points. This is realized via efficient Jacobian Spectral Radius Regularization with random loop sampling, enabling STARS to maximize effectiveness while ensuring rigorous stability. Experiments on arithmetic tasks show that STARS achieves reliable test-time scaling, and on complex mathematical reasoning it substantially mitigates performance degradation as recurrence depth increases while also improving peak performance.
Revisiting the Travel Planning Capabilities of Large Language Models
May 05, 2026Travel planning serves as a critical task for long-horizon reasoning, exposing significant deficits in LLMs. However, existing benchmarks and evaluations primarily assess final plans in an end-to-end manner, which lacks interpretability and makes it difficult to analyze the root causes of failures. To bridge this gap, we decompose travel planning into five constituent atomic sub-capabilities, including \emph{Constraint Extraction}, \emph{Tool Use}, \emph{Plan Generation}, \emph{Error Identification}, and \emph{Error Correction}. We implement a decoupled evaluation protocol leveraging oracle intermediate contexts to rigorously isolate these components, thereby measuring the atomic performance boundary without the noise of cascading errors. Our results highlight a clear contrast in performance: while LLMs are proficient in extracting explicit constraints, they struggle to infer implicit, open-world requirements. Furthermore, they exhibit structural biases in plan generation and suffer from ineffective self-correction, characterized by excessive sensitivity and erroneous persistence. These findings offer precise directions for improving LLM reasoning and planning abilities.
When Is Prior Knowledge Helpful? Exploring the Evaluation and Selection of Unsupervised Pretext Tasks from a Neuro-Symbolic Perspective
Aug 10, 2025Neuro-symbolic (Nesy) learning improves the target task performance of models by enabling them to satisfy knowledge, while semi/self-supervised learning (SSL) improves the target task performance by designing unsupervised pretext tasks for unlabeled data to make models satisfy corresponding assumptions. We extend the Nesy theory based on reliable knowledge to the scenario of unreliable knowledge (i.e., assumptions), thereby unifying the theoretical frameworks of SSL and Nesy. Through rigorous theoretical analysis, we demonstrate that, in theory, the impact of pretext tasks on target performance hinges on three factors: knowledge learnability with respect to the model, knowledge reliability with respect to the data, and knowledge completeness with respect to the target. We further propose schemes to operationalize these theoretical metrics, and thereby develop a method that can predict the effectiveness of pretext tasks in advance. This will change the current status quo in practical applications, where the selections of unsupervised tasks are heuristic-based rather than theory-based, and it is difficult to evaluate the rationality of unsupervised pretext task selection before testing the model on the target task. In experiments, we verify a high correlation between the predicted performance-estimated using minimal data-and the actual performance achieved after large-scale semi-supervised or self-supervised learning, thus confirming the validity of the theory and the effectiveness of the evaluation method.
Verification Learning: Make Unsupervised Neuro-Symbolic System Feasible
Mar 17, 2025The current Neuro-Symbolic (NeSy) Learning paradigm suffers from an over-reliance on labeled data. If we completely disregard labels, it leads to less symbol information, a larger solution space, and more shortcuts-issues that current Nesy systems cannot resolve. This paper introduces a novel learning paradigm, Verification Learning (VL), which addresses this challenge by transforming the label-based reasoning process in Nesy into a label-free verification process. VL achieves excellent learning results solely by relying on unlabeled data and a function that verifies whether the current predictions conform to the rules. We formalize this problem as a Constraint Optimization Problem (COP) and propose a Dynamic combinatorial Sorting (DCS) algorithm that accelerates the solution by reducing verification attempts, effectively lowering computational costs to the level of a Constraint Satisfaction Problem (CSP). To further enhance performance, we introduce a prior alignment method to address potential shortcuts. Our theoretical analysis points out which tasks in Nesy systems can be completed without labels and explains why rules can replace infinite labels, such as in addition, for some tasks, while for others, like Sudoku, the rules have no effect. We validate the proposed framework through several fully unsupervised tasks including addition, sort, match, and chess, each showing significant performance and efficiency improvements.
Step Back to Leap Forward: Self-Backtracking for Boosting Reasoning of Language Models
Feb 06, 2025



The integration of slow-thinking mechanisms into large language models (LLMs) offers a promising way toward achieving Level 2 AGI Reasoners, as exemplified by systems like OpenAI's o1. However, several significant challenges remain, including inefficient overthinking and an overreliance on auxiliary reward models. We point out that these limitations stem from LLMs' inability to internalize the search process, a key component of effective reasoning. A critical step toward addressing this issue is enabling LLMs to autonomously determine when and where to backtrack, a fundamental operation in traditional search algorithms. To this end, we propose a self-backtracking mechanism that equips LLMs with the ability to backtrack during both training and inference. This mechanism not only enhances reasoning ability but also efficiency by transforming slow-thinking processes into fast-thinking through self-improvement. Empirical evaluations demonstrate that our proposal significantly enhances the reasoning capabilities of LLMs, achieving a performance gain of over 40 percent compared to the optimal-path supervised fine-tuning method. We believe this study introduces a novel and promising pathway for developing more advanced and robust Reasoners.
Robust Semi-Supervised Learning in Open Environments
Dec 24, 2024Semi-supervised learning (SSL) aims to improve performance by exploiting unlabeled data when labels are scarce. Conventional SSL studies typically assume close environments where important factors (e.g., label, feature, distribution) between labeled and unlabeled data are consistent. However, more practical tasks involve open environments where important factors between labeled and unlabeled data are inconsistent. It has been reported that exploiting inconsistent unlabeled data causes severe performance degradation, even worse than the simple supervised learning baseline. Manually verifying the quality of unlabeled data is not desirable, therefore, it is important to study robust SSL with inconsistent unlabeled data in open environments. This paper briefly introduces some advances in this line of research, focusing on techniques concerning label, feature, and data distribution inconsistency in SSL, and presents the evaluation benchmarks. Open research problems are also discussed for reference purposes.
* 12 pages, 4 figures
ChinaTravel: A Real-World Benchmark for Language Agents in Chinese Travel Planning
Dec 18, 2024



Recent advances in LLMs, particularly in language reasoning and tool integration, have rapidly sparked the real-world development of Language Agents. Among these, travel planning represents a prominent domain, combining academic challenges with practical value due to its complexity and market demand. However, existing benchmarks fail to reflect the diverse, real-world requirements crucial for deployment. To address this gap, we introduce ChinaTravel, a benchmark specifically designed for authentic Chinese travel planning scenarios. We collect the travel requirements from questionnaires and propose a compositionally generalizable domain-specific language that enables a scalable evaluation process, covering feasibility, constraint satisfaction, and preference comparison. Empirical studies reveal the potential of neuro-symbolic agents in travel planning, achieving a constraint satisfaction rate of 27.9%, significantly surpassing purely neural models at 2.6%. Moreover, we identify key challenges in real-world travel planning deployments, including open language reasoning and unseen concept composition. These findings highlight the significance of ChinaTravel as a pivotal milestone for advancing language agents in complex, real-world planning scenarios.
Learning for Long-Horizon Planning via Neuro-Symbolic Abductive Imitation
Nov 27, 2024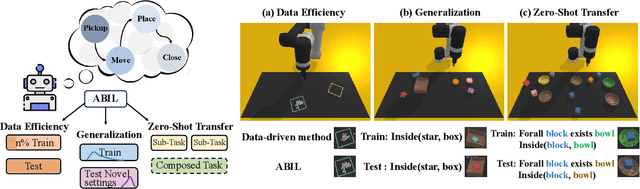
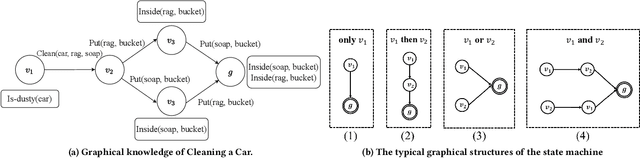
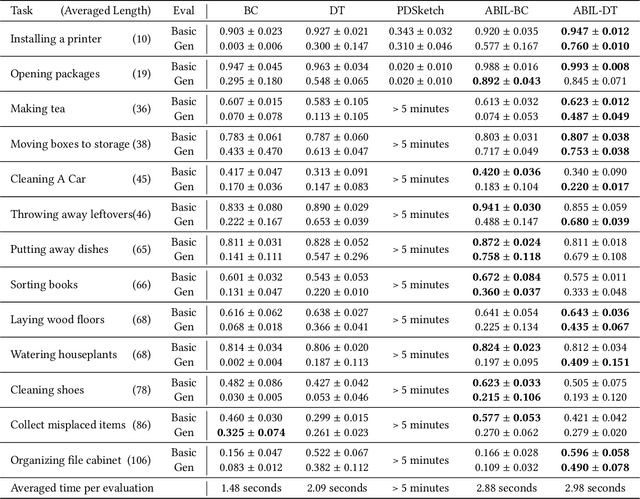
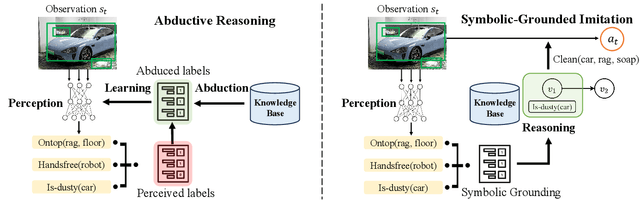
Recent learning-to-imitation methods have shown promising results in planning via imitating within the observation-action space. However, their ability in open environments remains constrained, particularly in long-horizon tasks. In contrast, traditional symbolic planning excels in long-horizon tasks through logical reasoning over human-defined symbolic spaces but struggles to handle observations beyond symbolic states, such as high-dimensional visual inputs encountered in real-world scenarios. In this work, we draw inspiration from abductive learning and introduce a novel framework \textbf{AB}ductive \textbf{I}mitation \textbf{L}earning (ABIL) that integrates the benefits of data-driven learning and symbolic-based reasoning, enabling long-horizon planning. Specifically, we employ abductive reasoning to understand the demonstrations in symbolic space and design the principles of sequential consistency to resolve the conflicts between perception and reasoning. ABIL generates predicate candidates to facilitate the perception from raw observations to symbolic space without laborious predicate annotations, providing a groundwork for symbolic planning. With the symbolic understanding, we further develop a policy ensemble whose base policies are built with different logical objectives and managed through symbolic reasoning. Experiments show that our proposal successfully understands the observations with the task-relevant symbolics to assist the imitation learning. Importantly, ABIL demonstrates significantly improved data efficiency and generalization across various long-horizon tasks, highlighting it as a promising solution for long-horizon planning. Project website: \url{https://www.lamda.nju.edu.cn/shaojj/KDD25_ABIL/}.
Offline Imitation Learning with Model-based Reverse Augmentation
Jun 18, 2024In offline Imitation Learning (IL), one of the main challenges is the \textit{covariate shift} between the expert observations and the actual distribution encountered by the agent, because it is difficult to determine what action an agent should take when outside the state distribution of the expert demonstrations. Recently, the model-free solutions introduce the supplementary data and identify the latent expert-similar samples to augment the reliable samples during learning. Model-based solutions build forward dynamic models with conservatism quantification and then generate additional trajectories in the neighborhood of expert demonstrations. However, without reward supervision, these methods are often over-conservative in the out-of-expert-support regions, because only in states close to expert-observed states can there be a preferred action enabling policy optimization. To encourage more exploration on expert-unobserved states, we propose a novel model-based framework, called offline Imitation Learning with Self-paced Reverse Augmentation (SRA). Specifically, we build a reverse dynamic model from the offline demonstrations, which can efficiently generate trajectories leading to the expert-observed states in a self-paced style. Then, we use the subsequent reinforcement learning method to learn from the augmented trajectories and transit from expert-unobserved states to expert-observed states. This framework not only explores the expert-unobserved states but also guides maximizing long-term returns on these states, ultimately enabling generalization beyond the expert data. Empirical results show that our proposal could effectively mitigate the covariate shift and achieve the state-of-the-art performance on the offline imitation learning benchmarks. Project website: \url{https://www.lamda.nju.edu.cn/shaojj/KDD24_SRA/}.
Investigating the Limitation of CLIP Models: The Worst-Performing Categories
Oct 05, 2023Contrastive Language-Image Pre-training (CLIP) provides a foundation model by integrating natural language into visual concepts, enabling zero-shot recognition on downstream tasks. It is usually expected that satisfactory overall accuracy can be achieved across numerous domains through well-designed textual prompts. However, we found that their performance in the worst categories is significantly inferior to the overall performance. For example, on ImageNet, there are a total of 10 categories with class-wise accuracy as low as 0\%, even though the overall performance has achieved 64.1\%. This phenomenon reveals the potential risks associated with using CLIP models, particularly in risk-sensitive applications where specific categories hold significant importance. To address this issue, we investigate the alignment between the two modalities in the CLIP model and propose the Class-wise Matching Margin (\cmm) to measure the inference confusion. \cmm\ can effectively identify the worst-performing categories and estimate the potential performance of the candidate prompts. We further query large language models to enrich descriptions of worst-performing categories and build a weighted ensemble to highlight the efficient prompts. Experimental results clearly verify the effectiveness of our proposal, where the accuracy on the worst-10 categories on ImageNet is boosted to 5.2\%, without manual prompt engineering, laborious optimization, or access to labeled validation data.