 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Adaptive Meta-Gradient Adversarial Examples for Visual Tracking
May 13, 2025In recent years, visual tracking methods based on convolutional neural networks and Transformers have achieved remarkable performance and have been successfully applied in fields such as autonomous driving. However, the numerous security issues exposed by deep learning models have gradually affected the reliable application of visual tracking methods in real-world scenarios. Therefore, how to reveal the security vulnerabilities of existing visual trackers through effective adversarial attacks has become a critical problem that needs to be addressed. To this end, we propose an adaptive meta-gradient adversarial attack (AMGA) method for visual tracking. This method integrates multi-model ensembles and meta-learning strategies, combining momentum mechanisms and Gaussian smoothing, which can significantly enhance the transferability and attack effectiveness of adversarial examples. AMGA randomly selects models from a large model repository, constructs diverse tracking scenarios, and iteratively performs both white- and black-box adversarial attacks in each scenario, optimizing the gradient directions of each model. This paradigm minimizes the gap between white- and black-box adversarial attacks, thus achieving excellent attack performance in black-box scenarios. Extensive experimental results on large-scale datasets such as OTB2015, LaSOT, and GOT-10k demonstrate that AMGA significantly improves the attack performance, transferability, and deception of adversarial examples. Codes and data are available at https://github.com/pgao-lab/AMGA.
Project-and-Fuse: Improving RGB-D Semantic Segmentation via Graph Convolution Networks
Jan 31, 2025



Most existing RGB-D semantic segmentation methods focus on the feature level fusion, including complex cross-modality and cross-scale fusion modules. However, these methods may cause misalignment problem in the feature fusion process and counter-intuitive patches in the segmentation results. Inspired by the popular pixel-node-pixel pipeline, we propose to 1) fuse features from two modalities in a late fusion style, during which the geometric feature injection is guided by texture feature prior; 2) employ Graph Neural Networks (GNNs) on the fused feature to alleviate the emergence of irregular patches by inferring patch relationship. At the 3D feature extraction stage, we argue that traditional CNNs are not efficient enough for depth maps. So, we encode depth map into normal map, after which CNNs can easily extract object surface tendencies.At projection matrix generation stage, we find the existence of Biased-Assignment and Ambiguous-Locality issues in the original pipeline. Therefore, we propose to 1) adopt the Kullback-Leibler Loss to ensure no missing important pixel features, which can be viewed as hard pixel mining process; 2) connect regions that are close to each other in the Euclidean space as well as in the semantic space with larger edge weights so that location informations can been considered. Extensive experiments on two public datasets, NYU-DepthV2 and SUN RGB-D, have shown that our approach can consistently boost the performance of RGB-D semantic segmentation task.
Multi-view Clustering via Unified Multi-kernel Learning and Matrix Factorization
Dec 12, 2024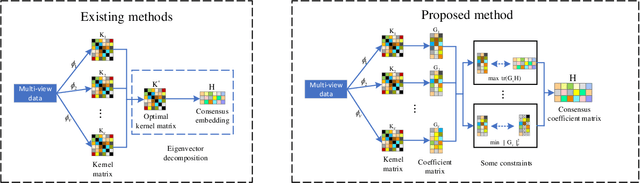

Multi-view clustering has become increasingly important due to the multi-source character of real-world data. Among existing multi-view clustering methods, multi-kernel clustering and matrix factorization-based multi-view clustering have gained widespread attention as mainstream approaches. However, multi-kernel clustering tends to learn an optimal kernel and then perform eigenvalue decomposition on it, which leads to high computational complexity. Matrix factorization-based multi-view clustering methods impose orthogonal constraints on individual views. This overly emphasizes the accuracy of clustering structures within single views and restricts the learning of individual views. Based on this analysis, we propose a multi-view clustering method that integrates multi-kernel learning with matrix factorization. This approach combines the advantages of both multi-kernel learning and matrix factorization. It removes the orthogonal constraints on individual views and imposes orthogonal constraints on the consensus matrix, resulting in an accurate final clustering structure. Ultimately, the method is unified into a simple form of multi-kernel clustering, but avoids learning an optimal kernel, thus reducing the time complexity. Furthermore, we propose an efficient three-step optimization algorithm to achieve a locally optimal solution. Experiments on widely-used real-world datasets demonstrate the effectiveness of our proposed method.
Critical Review for One-class Classification: recent advances and the reality behind them
Apr 27, 2024This paper offers a comprehensive review of one-class classification (OCC), examining the technologies and methodologies employed in its implementation. It delves into various approaches utilized for OCC across diverse data types, such as feature data, image, video, time series, and others. Through a systematic review, this paper synthesizes promi-nent strategies used in OCC from its inception to its current advance-ments, with a particular emphasis on the promising application. Moreo-ver, the article criticizes the state-of-the-art (SOTA) image anomaly de-tection (AD) algorithms dominating one-class experiments. These algo-rithms include outlier exposure (binary classification) and pretrained model (multi-class classification), conflicting with the fundamental con-cept of learning from one class. Our investigation reveals that the top nine algorithms for one-class CIFAR10 benchmark are not OCC. We ar-gue that binary/multi-class classification algorithms should not be com-pared with OCC.
In Defense and Revival of Bayesian Filtering for Thermal Infrared Object Tracking
Feb 27, 2024
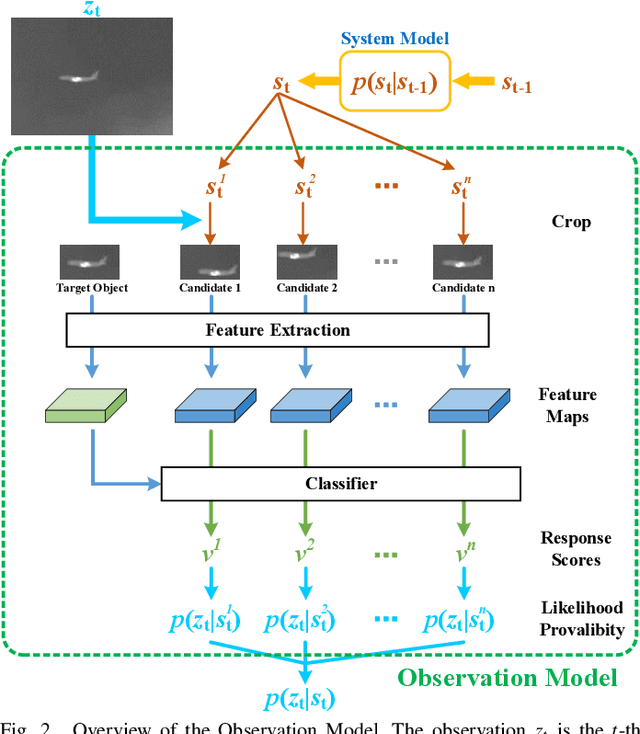


Deep learning-based methods monopolize the latest research in the field of thermal infrared (TIR) object tracking. However, relying solely on deep learning models to obtain better tracking results requires carefully selecting feature information that is beneficial to representing the target object and designing a reasonable template update strategy, which undoubtedly increases the difficulty of model design. Thus, recent TIR tracking methods face many challenges in complex scenarios. This paper introduces a novel Deep Bayesian Filtering (DBF) method to enhance TIR tracking in these challenging situations. DBF is distinctive in its dual-model structure: the system and observation models. The system model leverages motion data to estimate the potential positions of the target object based on two-dimensional Brownian motion, thus generating a prior probability. Following this, the observation model comes into play upon capturing the TIR image. It serves as a classifier and employs infrared information to ascertain the likelihood of these estimated positions, creating a likelihood probability. According to the guidance of the two models, the position of the target object can be determined, and the template can be dynamically updated. Experimental analysis across several benchmark datasets reveals that DBF achieves competitive performance, surpassing most existing TIR tracking methods in complex scenarios.
Heterogeneous Graph Attention Network for Multi-hop Machine Reading Comprehension
Jul 02, 2021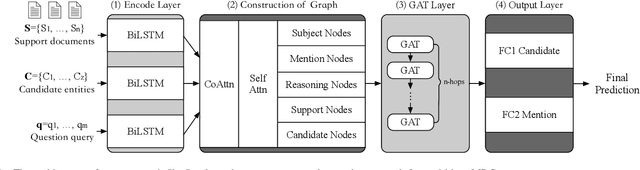



Multi-hop machine reading comprehension is a challenging task in natural language processing, which requires more reasoning ability and explainability. Spectral models based on graph convolutional networks grant the inferring abilities and lead to competitive results, however, part of them still face the challenge of analyzing the reasoning in a human-understandable way. Inspired by the concept of the Grandmother Cells in cognitive neuroscience, a spatial graph attention framework named crname, imitating the procedure was proposed. This model is designed to assemble the semantic features in multi-angle representations and automatically concentrate or alleviate the information for reasoning. The name "crname" is a metaphor for the pattern of the model: regard the subjects of queries as the start points of clues, take the reasoning entities as bridge points, and consider the latent candidate entities as the grandmother cells, and the clues end up in candidate entities. The proposed model allows us to visualize the reasoning graph and analyze the importance of edges connecting two entities and the selectivity in the mention and candidate nodes, which can be easier to be comprehended empirically. The official evaluations in open-domain multi-hop reading dataset WikiHop and Drug-drug Interactions dataset MedHop prove the validity of our approach and show the probability of the application of the model in the molecular biology domain.
Cluster-based Zero-shot learning for multivariate data
Feb 13, 2020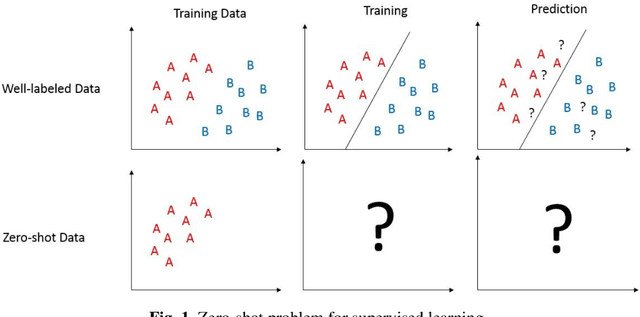

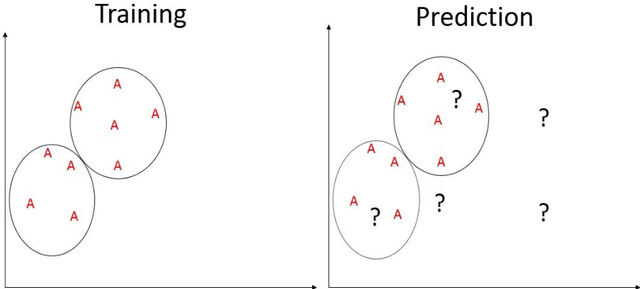
Supervised learning requires a sufficient training dataset which includes all label. However, there are cases that some class is not in the training data. Zero-Shot Learning (ZSL) is the task of predicting class that is not in the training data(target class). The existing ZSL method is done for image data. However, the zero-shot problem should happen to every data type. Hence, considering ZSL for other data types is required. In this paper, we propose the cluster-based ZSL method, which is a baseline method for multivariate binary classification problems. The proposed method is based on the assumption that if data is far from training data, the data is considered as target class. In training, clustering is done for training data. In prediction, the data is determined belonging to a cluster or not. If data does not belong to a cluster, the data is predicted as target class. The proposed method is evaluated and demonstrated using the KEEL dataset.