 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-classification of one-class classification models using ranking correlation and nearest neighbor
Jun 16, 2026Machine Learning (ML) techniques have been applied to various problems. However, applying ML to ML models is an unexplored direction. For this purpose, this paper considers a meta-classification of one-class classification (OCC) models, because all ML models could be approximated as OCC models. The proposal represents OCC models as normality rankings and classifies them using nearest-neighbor and ranking-correlation metrics. The experiment classifies OCC models, where classes correspond to training datasets, algorithms, and hyperparameters. The proposal achieves high accuracy when class labels are datasets. Moreover, it can classify algorithms when the training datasets contain the same class. In addition, the discussion highlights that the classification of OCC models is essentially the classification of datasets that treats multiple samples as a single input. The experiment demonstrates the classification of datasets using sleeping records. The proposed method can provide a unified solution for classifying OCC models, datasets, and rankings. Source code is uploaded to the public repository https://github.com/ToshiHayashi/ClassOCC.
Decomposing one-class support vector machine into an ensemble of one-data support vector machines
Jun 14, 2026One-class classification (OCC) is a classification problem in which the training data contains only one class. The one-class support vector machine (OCSVM) is one of the most competitive OCC algorithms. However, OCSVM has scalability issues with large-scale datasets. This paper proposes the acceleration strategy of OCSVM. The idea is to decompose the dataset into samples and train OCSVM models for single data points. Subsequently, ensemble learning is applied to combine all models to compute the OCSVM model for the dataset. In addition, further acceleration is achieved through a data-reduction strategy with an OCSVM model trained on the average of the training samples. The experiment compared the proposal and traditional OCSVM using the Python package. The proposed strategy is faster than traditional OCSVM, while achieving similar classification results. Moreover, the proposed strategy can create one-to-one correspondence between samples and models. Source code is uploaded at https://github.com/ToshiHayashi/ODSVM
Critical Review for One-class Classification: recent advances and the reality behind them
Apr 27, 2024This paper offers a comprehensive review of one-class classification (OCC), examining the technologies and methodologies employed in its implementation. It delves into various approaches utilized for OCC across diverse data types, such as feature data, image, video, time series, and others. Through a systematic review, this paper synthesizes promi-nent strategies used in OCC from its inception to its current advance-ments, with a particular emphasis on the promising application. Moreo-ver, the article criticizes the state-of-the-art (SOTA) image anomaly de-tection (AD) algorithms dominating one-class experiments. These algo-rithms include outlier exposure (binary classification) and pretrained model (multi-class classification), conflicting with the fundamental con-cept of learning from one class. Our investigation reveals that the top nine algorithms for one-class CIFAR10 benchmark are not OCC. We ar-gue that binary/multi-class classification algorithms should not be com-pared with OCC.
Cluster-based Zero-shot learning for multivariate data
Feb 13, 2020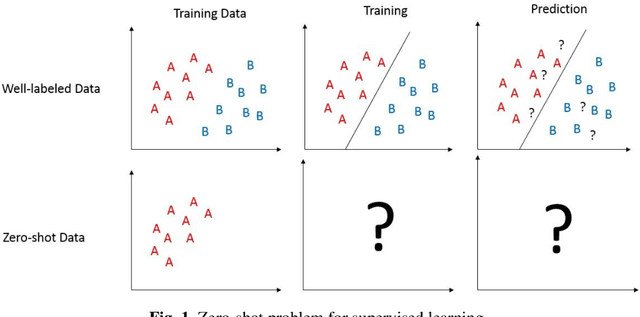

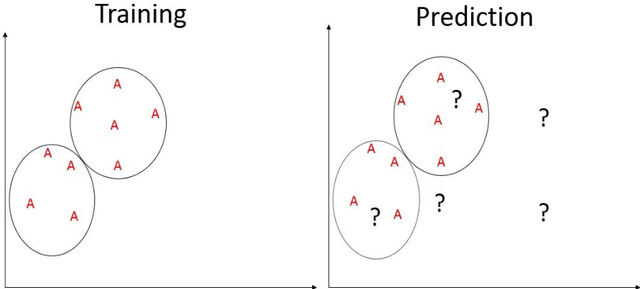
Supervised learning requires a sufficient training dataset which includes all label. However, there are cases that some class is not in the training data. Zero-Shot Learning (ZSL) is the task of predicting class that is not in the training data(target class). The existing ZSL method is done for image data. However, the zero-shot problem should happen to every data type. Hence, considering ZSL for other data types is required. In this paper, we propose the cluster-based ZSL method, which is a baseline method for multivariate binary classification problems. The proposed method is based on the assumption that if data is far from training data, the data is considered as target class. In training, clustering is done for training data. In prediction, the data is determined belonging to a cluster or not. If data does not belong to a cluster, the data is predicted as target class. The proposed method is evaluated and demonstrated using the KEEL dataset.