 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Overlapping Placement of Macro Cells based on Reinforcement Learning in Chip Design
Jul 26, 2024Due to the increasing complexity of chip design, existing placement methods still have many shortcomings in dealing with macro cells coverage and optimization efficiency. Aiming at the problems of layout overlap, inferior performance, and low optimization efficiency in existing chip design methods, this paper proposes an end-to-end placement method, SRLPlacer, based on reinforcement learning. First, the placement problem is transformed into a Markov decision process by establishing the coupling relationship graph model between macro cells to learn the strategy for optimizing layouts. Secondly, the whole placement process is optimized after integrating the standard cell layout. By assessing on the public benchmark ISPD2005, the proposed SRLPlacer can effectively solve the overlap problem between macro cells while considering routing congestion and shortening the total wire length to ensure routability.
CSWin-UNet: Transformer UNet with Cross-Shaped Windows for Medical Image Segmentation
Jul 25, 2024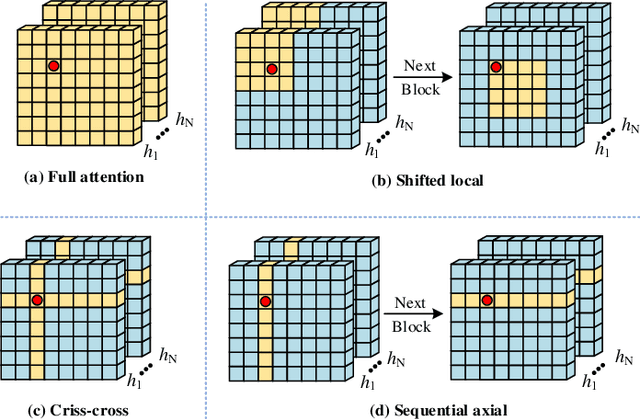
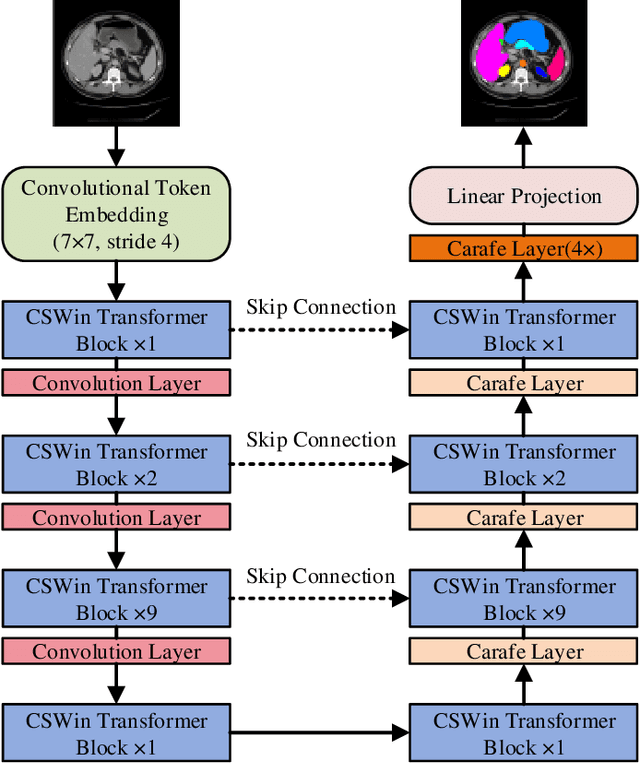
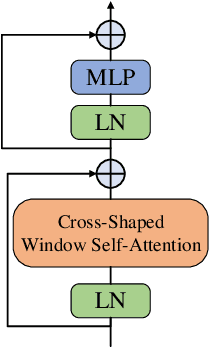
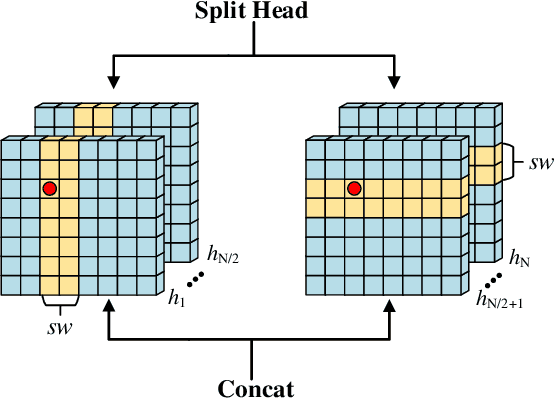
Deep learning, especially convolutional neural networks (CNNs) and Transformer architectures, have become the focus of extensive research in medical image segmentation, achieving impressive results. However, CNNs come with inductive biases that limit their effectiveness in more complex, varied segmentation scenarios. Conversely, while Transformer-based methods excel at capturing global and long-range semantic details, they suffer from high computational demands. In this study, we propose CSWin-UNet, a novel U-shaped segmentation method that incorporates the CSWin self-attention mechanism into the UNet to facilitate horizontal and vertical stripes self-attention. This method significantly enhances both computational efficiency and receptive field interactions. Additionally, our innovative decoder utilizes a content-aware reassembly operator that strategically reassembles features, guided by predicted kernels, for precise image resolution restoration. Our extensive empirical evaluations on diverse datasets, including synapse multi-organ CT, cardiac MRI, and skin lesions, demonstrate that CSWin-UNet maintains low model complexity while delivering high segmentation accuracy.
In Defense and Revival of Bayesian Filtering for Thermal Infrared Object Tracking
Feb 27, 2024Deep learning-based methods monopolize the latest research in the field of thermal infrared (TIR) object tracking. However, relying solely on deep learning models to obtain better tracking results requires carefully selecting feature information that is beneficial to representing the target object and designing a reasonable template update strategy, which undoubtedly increases the difficulty of model design. Thus, recent TIR tracking methods face many challenges in complex scenarios. This paper introduces a novel Deep Bayesian Filtering (DBF) method to enhance TIR tracking in these challenging situations. DBF is distinctive in its dual-model structure: the system and observation models. The system model leverages motion data to estimate the potential positions of the target object based on two-dimensional Brownian motion, thus generating a prior probability. Following this, the observation model comes into play upon capturing the TIR image. It serves as a classifier and employs infrared information to ascertain the likelihood of these estimated positions, creating a likelihood probability. According to the guidance of the two models, the position of the target object can be determined, and the template can be dynamically updated. Experimental analysis across several benchmark datasets reveals that DBF achieves competitive performance, surpassing most existing TIR tracking methods in complex scenarios.
Searching a Lightweight Network Architecture for Thermal Infrared Pedestrian Tracking
Feb 26, 2024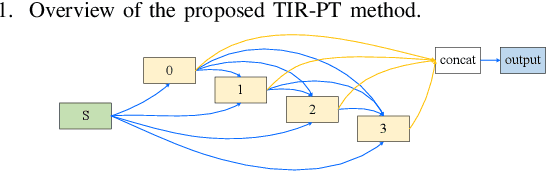
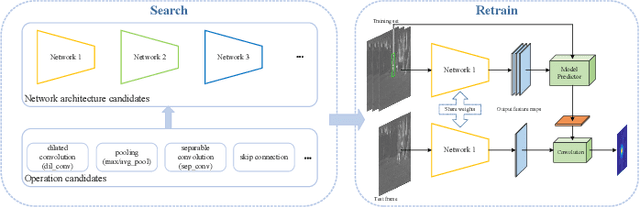
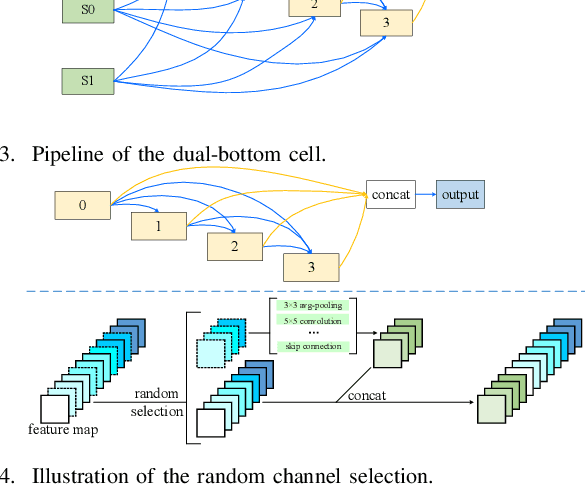
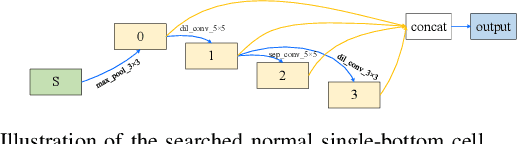
Manually-designed network architectures for thermal infrared pedestrian tracking (TIR-PT) require substantial effort from human experts. Neural networks with ResNet backbones are popular for TIR-PT. However, TIR-PT is a tracking task and more challenging than classification and detection. This paper makes an early attempt to search an optimal network architecture for TIR-PT automatically, employing single-bottom and dual-bottom cells as basic search units and incorporating eight operation candidates within the search space. To expedite the search process, a random channel selection strategy is employed prior to assessing operation candidates. Classification, batch hard triplet, and center loss are jointly used to retrain the searched architecture. The outcome is a high-performance network architecture that is both parameter- and computation-efficient. Extensive experiments proved the effectiveness of the automated method.
Automated Design and Optimization of Distributed Filtering Circuits via Reinforcement Learning
Feb 22, 2024



Designing distributed filtering circuits (DFCs) is complex and time-consuming, with the circuit performance relying heavily on the expertise and experience of electronics engineers. However, manual design methods tend to have exceedingly low-efficiency. This study proposes a novel end-to-end automated method for fabricating circuits to improve the design of DFCs. The proposed method harnesses reinforcement learning (RL) algorithms, eliminating the dependence on the design experience of engineers. Thus, it significantly reduces the subjectivity and constraints associated with circuit design. The experimental findings demonstrate clear improvements in both design efficiency and quality when comparing the proposed method with traditional engineer-driven methods. In particular, the proposed method achieves superior performance when designing complex or rapidly evolving DFCs. Furthermore, compared to existing circuit automation design techniques, the proposed method demonstrates superior design efficiency, highlighting the substantial potential of RL in circuit design automation.
YOLO-TLA: An Efficient and Lightweight Small Object Detection Model based on YOLOv5
Feb 22, 2024Object detection, a crucial aspect of computer vision, has seen significant advancements in accuracy and robustness. Despite these advancements, practical applications still face notable challenges, primarily the inaccurate detection or missed detection of small objects. In this paper, we propose YOLO-TLA, an advanced object detection model building on YOLOv5. We first introduce an additional detection layer for small objects in the neck network pyramid architecture, thereby producing a feature map of a larger scale to discern finer features of small objects. Further, we integrate the C3CrossCovn module into the backbone network. This module uses sliding window feature extraction, which effectively minimizes both computational demand and the number of parameters, rendering the model more compact. Additionally, we have incorporated a global attention mechanism into the backbone network. This mechanism combines the channel information with global information to create a weighted feature map. This feature map is tailored to highlight the attributes of the object of interest, while effectively ignoring irrelevant details. In comparison to the baseline YOLOv5s model, our newly developed YOLO-TLA model has shown considerable improvements on the MS COCO validation dataset, with increases of 4.6% in mAP@0.5 and 4% in mAP@0.5:0.95, all while keeping the model size compact at 9.49M parameters. Further extending these improvements to the YOLOv5m model, the enhanced version exhibited a 1.7% and 1.9% increase in mAP@0.5 and mAP@0.5:0.95, respectively, with a total of 27.53M parameters. These results validate the YOLO-TLA model's efficient and effective performance in small object detection, achieving high accuracy with fewer parameters and computational demands.