 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlocOff: Data Heterogeneity Resilient Federated Learning with Communication-Efficient Edge Offloading
Paper and Code
May 29, 2024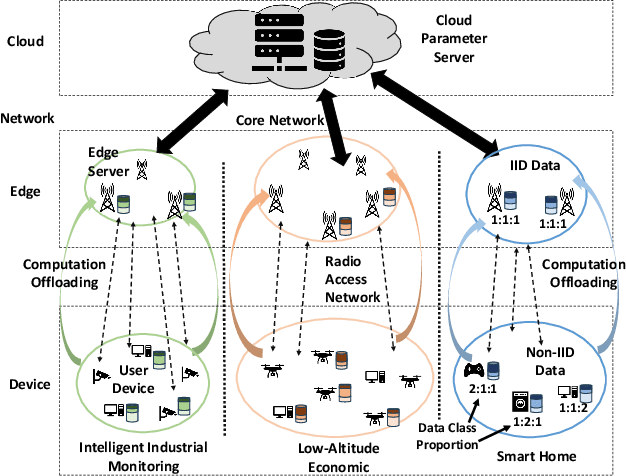
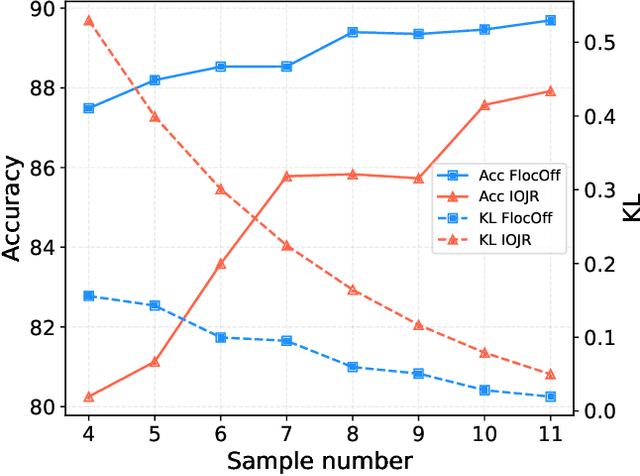
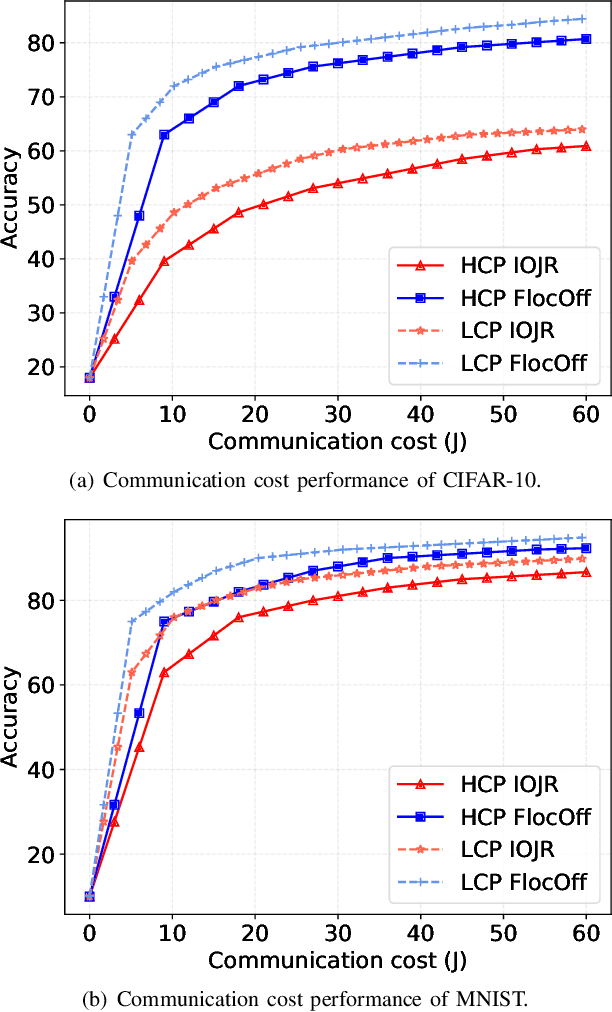
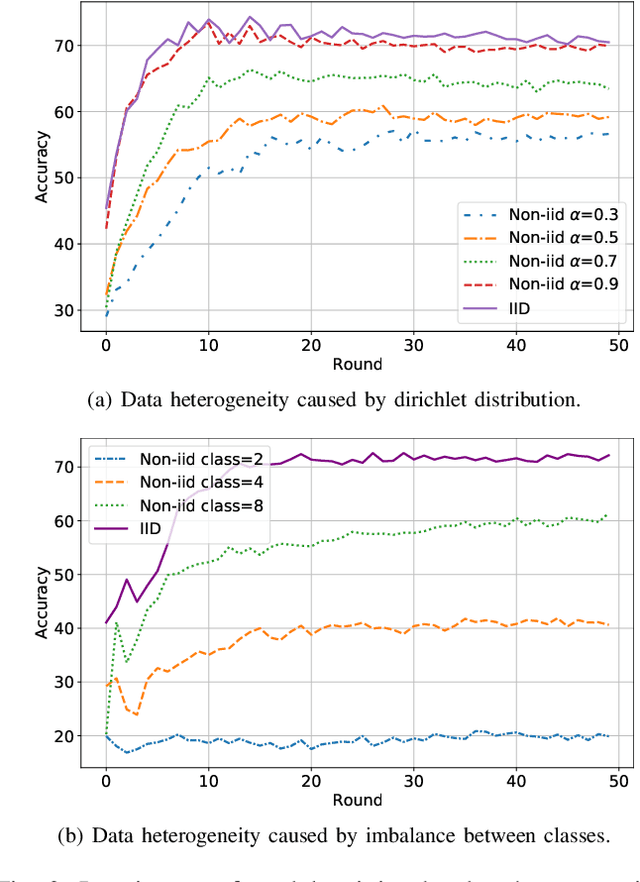
Federated Learning (FL) has emerged as a fundamental learning paradigm to harness massive data scattered at geo-distributed edge devices in a privacy-preserving way. Given the heterogeneous deployment of edge devices, however, their data are usually Non-IID, introducing significant challenges to FL including degraded training accuracy, intensive communication costs, and high computing complexity. Towards that, traditional approaches typically utilize adaptive mechanisms, which may suffer from scalability issues, increased computational overhead, and limited adaptability to diverse edge environments. To address that, this paper instead leverages the observation that the computation offloading involves inherent functionalities such as node matching and service correlation to achieve data reshaping and proposes Federated learning based on computing Offloading (FlocOff) framework, to address data heterogeneity and resource-constrained challenges. Specifically, FlocOff formulates the FL process with Non-IID data in edge scenarios and derives rigorous analysis on the impact of imbalanced data distribution. Based on this, FlocOff decouples the optimization in two steps, namely : (1) Minimizes the Kullback-Leibler (KL) divergence via Computation Offloading scheduling (MKL-CO); (2) Minimizes the Communication Cost through Resource Allocation (MCC-RA). Extensive experimental results demonstrate that the proposed FlocOff effectively improves model convergence and accuracy by 14.3\%-32.7\% while reducing data heterogeneity under various data distributions.