 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Federated Label Distribution Learning under Annotation Quality Disparity
May 06, 2026Label Distribution Learning (LDL) models supervision as an instance-wise probability distribution, enabling fine-grained learning under inherent ambiguity, but its success relies on high-fidelity label distributions that are costly to obtain and thus often noisy. Motivated by privacy-sensitive applications, we study Federated Label Distribution Learning (Fed-LDL), where data isolation further induces heterogeneous annotation quality across clients, making local updates unevenly reliable and breaking sample-size-based aggregation (e.g., FedAvg). To address this trust dilemma, we propose FedQual, a quality-aware Fed-LDL framework with two coupled mechanisms: (i) quality-adaptive client training guided by a global semantic anchor that calibrates low-quality clients while preserving high-quality autonomy, and (ii) reliability-aware server aggregation that reweights client contributions by effective reliable information rather than raw sample size. To enable rigorous evaluation, we construct four new Fed-LDL benchmarks (FER-LDL, FI-LDL, PIPAL-LDL, and KADID-LDL) with controlled annotation quality disparity. We further provide a theoretical guarantee showing that under heterogeneous supervision quality, client-specific calibration is strictly better than any uniform calibration. Extensive experiments on the proposed benchmarks demonstrate the effectiveness of FedQual.
FinToolBench: Evaluating LLM Agents for Real-World Financial Tool Use
Mar 09, 2026The integration of Large Language Models (LLMs) into the financial domain is driving a paradigm shift from passive information retrieval to dynamic, agentic interaction. While general-purpose tool learning has witnessed a surge in benchmarks, the financial sector, characterized by high stakes, strict compliance, and rapid data volatility, remains critically underserved. Existing financial evaluations predominantly focus on static textual analysis or document-based QA, ignoring the complex reality of tool execution. Conversely, general tool benchmarks lack the domain-specific rigor required for finance, often relying on toy environments or a negligible number of financial APIs. To bridge this gap, we introduce FinToolBench, the first real-world, runnable benchmark dedicated to evaluating financial tool learning agents. Unlike prior works limited to a handful of mock tools, FinToolBench establishes a realistic ecosystem coupling 760 executable financial tools with 295 rigorous, tool-required queries. We propose a novel evaluation framework that goes beyond binary execution success, assessing agents on finance-critical dimensions: timeliness, intent type, and regulatory domain alignment. Furthermore, we present FATR, a finance-aware tool retrieval and reasoning baseline that enhances stability and compliance. By providing the first testbed for auditable, agentic financial execution, FinToolBench sets a new standard for trustworthy AI in finance. The tool manifest, execution environment, and evaluation code will be open-sourced to facilitate future research.
ASA: Training-Free Representation Engineering for Tool-Calling Agents
Feb 08, 2026Adapting LLM agents to domain-specific tool calling remains notably brittle under evolving interfaces. Prompt and schema engineering is easy to deploy but often fragile under distribution shift and strict parsers, while continual parameter-efficient fine-tuning improves reliability at the cost of training, maintenance, and potential forgetting. We identify a critical Lazy Agent failure mode where tool necessity is nearly perfectly decodable from mid-layer activations, yet the model remains conservative in entering tool mode, revealing a representation-behavior gap. We propose Activation Steering Adapter (ASA), a training-free, inference-time controller that performs a single-shot mid-layer intervention and targets tool domains via a router-conditioned mixture of steering vectors with a probe-guided signed gate to amplify true intent while suppressing spurious triggers. On MTU-Bench with Qwen2.5-1.5B, ASA improves strict tool-use F1 from 0.18 to 0.50 while reducing the false positive rate from 0.15 to 0.05, using only about 20KB of portable assets and no weight updates.
ASA: Activation Steering for Tool-Calling Domain Adaptation
Feb 04, 2026For real-world deployment of general-purpose LLM agents, the core challenge is often not tool use itself, but efficient domain adaptation under rapidly evolving toolsets, APIs, and protocols. Repeated LoRA or SFT across domains incurs exponentially growing training and maintenance costs, while prompt or schema methods are brittle under distribution shift and complex interfaces. We propose \textbf{Activation Steering Adapter (ASA}), a lightweight, inference-time, training-free mechanism that reads routing signals from intermediate activations and uses an ultra-light router to produce adaptive control strengths for precise domain alignment. Across multiple model scales and domains, ASA achieves LoRA-comparable adaptation with substantially lower overhead and strong cross-model transferability, making it ideally practical for robust, scalable, and efficient multi-domain tool ecosystems with frequent interface churn dynamics.
Knowledge forest: a novel model to organize knowledge fragments
Dec 14, 2019
With the rapid growth of knowledge, it shows a steady trend of knowledge fragmentization. Knowledge fragmentization manifests as that the knowledge related to a specific topic in a course is scattered in isolated and autonomous knowledge sources. We term the knowledge of a facet in a specific topic as a knowledge fragment. The problem of knowledge fragmentization brings two challenges: First, knowledge is scattered in various knowledge sources, which exerts users' considerable efforts to search for the knowledge of their interested topics, thereby leading to information overload. Second, learning dependencies which refer to the precedence relationships between topics in the learning process are concealed by the isolation and autonomy of knowledge sources, thus causing learning disorientation. To solve the knowledge fragmentization problem, we propose a novel knowledge organization model, knowledge forest, which consists of facet trees and learning dependencies. Facet trees can organize knowledge fragments with facet hyponymy to alleviate information overload. Learning dependencies can organize disordered topics to cope with learning disorientation. We conduct extensive experiments on three manually constructed datasets from the Data Structure, Data Mining, and Computer Network courses, and the experimental results show that knowledge forest can effectively organize knowledge fragments, and alleviate information overload and learning disorientation.
Extended Answer and Uncertainty Aware Neural Question Generation
Nov 19, 2019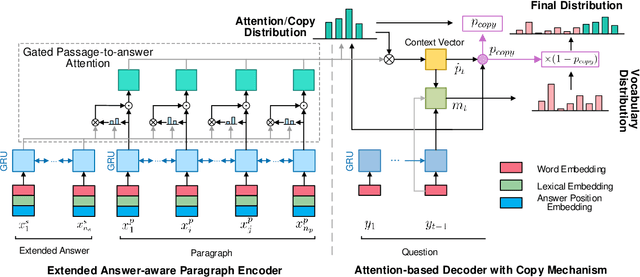
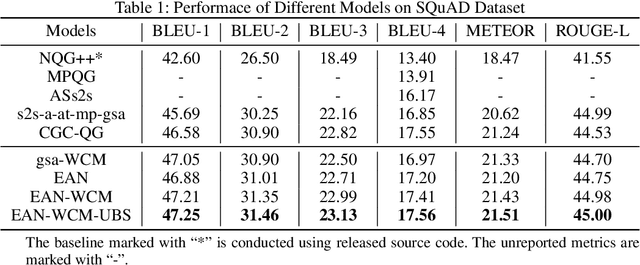
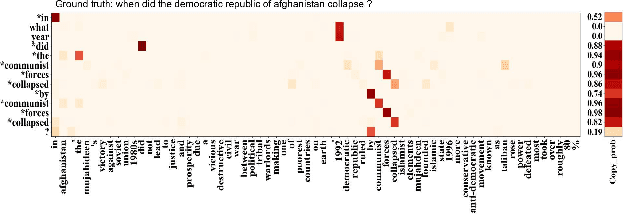

In this paper, we study automatic question generation, the task of creating questions from corresponding text passages where some certain spans of the text can serve as the answers. We propose an Extended Answer-aware Network (EAN) which is trained with Word-based Coverage Mechanism (WCM) and decodes with Uncertainty-aware Beam Search (UBS). The EAN represents the target answer by its surrounding sentence with an encoder, and incorporates the information of the extended answer into paragraph representation with gated paragraph-to-answer attention to tackle the problem of the inadequate representation of the target answer. To reduce undesirable repetition, the WCM penalizes repeatedly attending to the same words at different time-steps in the training stage. The UBS aims to seek a better balance between the model confidence in copying words from an input text paragraph and the confidence in generating words from a vocabulary. We conduct experiments on the SQuAD dataset, and the results show our approach achieves significant performance improvement.