 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Video Reasoning in Physical Signals
Apr 23, 2026Physical video understanding requires more than naming an event correctly. A model can answer a question about pouring, sliding, or collision from textual regularities while still failing to localize the event in time or space. We introduce a grounded benchmark for physical video understanding that extends the what--when--where evaluation structure of V-STaR to four video sources, six physics domains, three prompt families (physics, vstar_like, and neutral_rstr), and four input conditions (original, shuffled, ablated, and frame-masked). The benchmark contains 1,560 base video clips from SSV2, YouCook2, HoloAssist, and Roundabout-TAU. Each clip is first converted into a shared grounded event record, and the three query families are derived from that record. Temporal and spatial targets are shared across prompt families, while the non-physics families use deterministic family-appropriate semantic a_what targets derived from the same record. Across models and prompt families, physics remains the strongest regime overall, vstar_like is the clearest non-physics semantic comparison, and neutral_rstr behaves as a harder templated control. Prompt-family robustness is selective rather than universal, perturbation gains cluster in weak original cases, and spatial grounding is the weakest across settings. These results suggest that video Q&A reasoning benchmarks shall report physically grounded, prompt-aware, and perturbation-aware diagnostics alongside aggregate accuracy.
GraphThinker: Reinforcing Video Reasoning with Event Graph Thinking
Feb 19, 2026Video reasoning requires understanding the causal relationships between events in a video. However, such relationships are often implicit and costly to annotate manually. While existing multimodal large language models (MLLMs) often infer event relations through dense captions or video summaries for video reasoning, such modeling still lacks causal understanding. Without explicit causal structure modeling within and across video events, these models suffer from hallucinations during the video reasoning. In this work, we propose GraphThinker, a reinforcement finetuning-based method that constructs structural event-level scene graphs and enhances visual grounding to jointly reduce hallucinations in video reasoning. Specifically, we first employ an MLLM to construct an event-based video scene graph (EVSG) that explicitly models both intra- and inter-event relations, and incorporate these formed scene graphs into the MLLM as an intermediate thinking process. We also introduce a visual attention reward during reinforcement finetuning, which strengthens video grounding and further mitigates hallucinations. We evaluate GraphThinker on two datasets, RexTime and VidHalluc, where it shows superior ability to capture object and event relations with more precise event localization, reducing hallucinations in video reasoning compared to prior methods.
Uncertainty-quantified Rollout Policy Adaptation for Unlabelled Cross-domain Temporal Grounding
Aug 08, 2025Video Temporal Grounding (TG) aims to temporally locate video segments matching a natural language description (a query) in a long video. While Vision-Language Models (VLMs) are effective at holistic semantic matching, they often struggle with fine-grained temporal localisation. Recently, Group Relative Policy Optimisation (GRPO) reformulates the inference process as a reinforcement learning task, enabling fine-grained grounding and achieving strong in-domain performance. However, GRPO relies on labelled data, making it unsuitable in unlabelled domains. Moreover, because videos are large and expensive to store and process, performing full-scale adaptation introduces prohibitive latency and computational overhead, making it impractical for real-time deployment. To overcome both problems, we introduce a Data-Efficient Unlabelled Cross-domain Temporal Grounding method, from which a model is first trained on a labelled source domain, then adapted to a target domain using only a small number of unlabelled videos from the target domain. This approach eliminates the need for target annotation and keeps both computational and storage overhead low enough to run in real time. Specifically, we introduce. Uncertainty-quantified Rollout Policy Adaptation (URPA) for cross-domain knowledge transfer in learning video temporal grounding without target labels. URPA generates multiple candidate predictions using GRPO rollouts, averages them to form a pseudo label, and estimates confidence from the variance across these rollouts. This confidence then weights the training rewards, guiding the model to focus on reliable supervision. Experiments on three datasets across six cross-domain settings show that URPA generalises well using only a few unlabelled target videos. Codes will be released once published.
V-STaR: Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning
Mar 14, 2025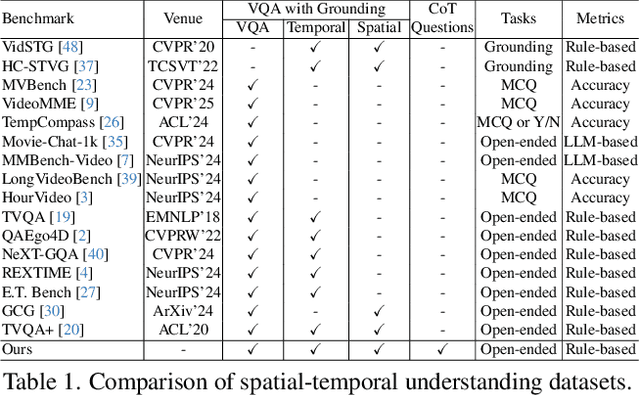
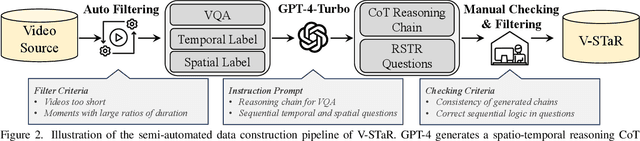

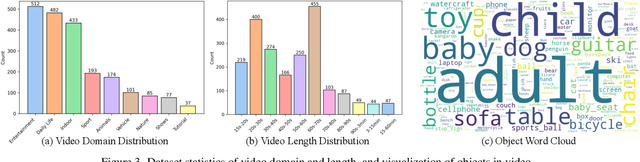
Human processes video reasoning in a sequential spatio-temporal reasoning logic, we first identify the relevant frames ("when") and then analyse the spatial relationships ("where") between key objects, and finally leverage these relationships to draw inferences ("what"). However, can Video Large Language Models (Video-LLMs) also "reason through a sequential spatio-temporal logic" in videos? Existing Video-LLM benchmarks primarily focus on assessing object presence, neglecting relational reasoning. Consequently, it is difficult to measure whether a model truly comprehends object interactions (actions/events) in videos or merely relies on pre-trained "memory" of co-occurrences as biases in generating answers. In this work, we introduce a Video Spatio-Temporal Reasoning (V-STaR) benchmark to address these shortcomings. The key idea is to decompose video understanding into a Reverse Spatio-Temporal Reasoning (RSTR) task that simultaneously evaluates what objects are present, when events occur, and where they are located while capturing the underlying Chain-of-thought (CoT) logic. To support this evaluation, we construct a dataset to elicit the spatial-temporal reasoning process of Video-LLMs. It contains coarse-to-fine CoT questions generated by a semi-automated GPT-4-powered pipeline, embedding explicit reasoning chains to mimic human cognition. Experiments from 14 Video-LLMs on our V-STaR reveal significant gaps between current Video-LLMs and the needs for robust and consistent spatio-temporal reasoning.
CoS: Chain-of-Shot Prompting for Long Video Understanding
Feb 10, 2025



Multi-modal Large Language Models (MLLMs) struggle with long videos due to the need for excessive visual tokens. These tokens exceed massively the context length of MLLMs, resulting in filled by redundant task-irrelevant shots. How to select shots is an unsolved critical problem: sparse sampling risks missing key details, while exhaustive sampling overwhelms the model with irrelevant content, leading to video misunderstanding. To solve this problem, we propose Chain-of-Shot prompting (CoS). The key idea is to frame shot selection as test-time visual prompt optimisation, choosing shots adaptive to video understanding semantic task by optimising shots-task alignment. CoS has two key parts: (1) a binary video summary mechanism that performs pseudo temporal grounding, discovering a binary coding to identify task-relevant shots, and (2) a video co-reasoning module that deploys the binary coding to pair (learning to align) task-relevant positive shots with irrelevant negative shots. It embeds the optimised shot selections into the original video, facilitating a focus on relevant context to optimize long video understanding. Experiments across three baselines and five datasets demonstrate the effectiveness and adaptability of CoS. Code given in https://lwpyh.github.io/CoS.
INT: Instance-Specific Negative Mining for Task-Generic Promptable Segmentation
Jan 30, 2025



Task-generic promptable image segmentation aims to achieve segmentation of diverse samples under a single task description by utilizing only one task-generic prompt. Current methods leverage the generalization capabilities of Vision-Language Models (VLMs) to infer instance-specific prompts from these task-generic prompts in order to guide the segmentation process. However, when VLMs struggle to generalise to some image instances, predicting instance-specific prompts becomes poor. To solve this problem, we introduce \textbf{I}nstance-specific \textbf{N}egative Mining for \textbf{T}ask-Generic Promptable Segmentation (\textbf{INT}). The key idea of INT is to adaptively reduce the influence of irrelevant (negative) prior knowledge whilst to increase the use the most plausible prior knowledge, selected by negative mining with higher contrast, in order to optimise instance-specific prompts generation. Specifically, INT consists of two components: (1) instance-specific prompt generation, which progressively fliters out incorrect information in prompt generation; (2) semantic mask generation, which ensures each image instance segmentation matches correctly the semantics of the instance-specific prompts. INT is validated on six datasets, including camouflaged objects and medical images, demonstrating its effectiveness, robustness and scalability.
SHINE: Saliency-aware HIerarchical NEgative Ranking for Compositional Temporal Grounding
Jul 06, 2024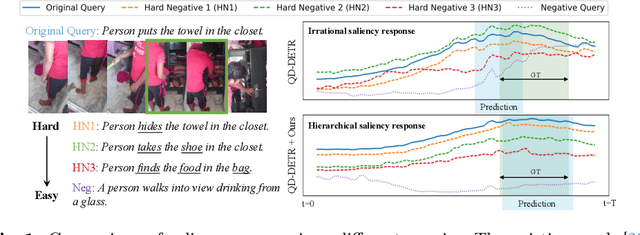
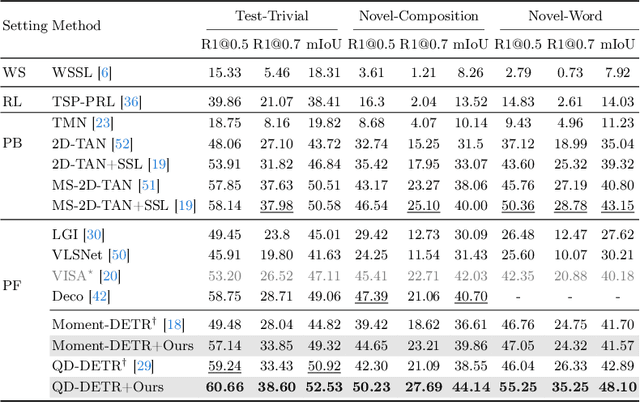
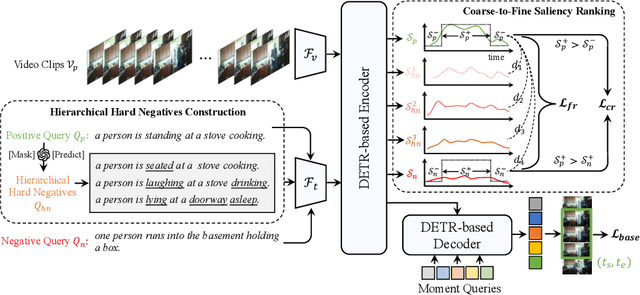
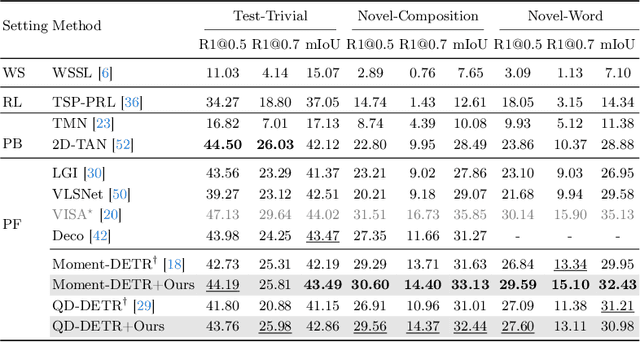
Temporal grounding, a.k.a video moment retrieval, aims at locating video segments corresponding to a given query sentence. The compositional nature of natural language enables the localization beyond predefined events, posing a certain challenge to the compositional generalizability of existing methods. Recent studies establish the correspondence between videos and queries through a decompose-reconstruct manner to achieve compositional generalization. However, they only consider dominant primitives and build negative queries through random sampling and recombination, resulting in semantically implausible negatives that hinder the models from learning rational compositions. In addition, recent DETR-based methods still underperform in compositional temporal grounding, showing irrational saliency responses when given negative queries that have subtle differences from positive queries. To address these limitations, we first propose a large language model-driven method for negative query construction, utilizing GPT-3.5-Turbo to generate semantically plausible hard negative queries. Subsequently, we introduce a coarse-to-fine saliency ranking strategy, which encourages the model to learn the multi-granularity semantic relationships between videos and hierarchical negative queries to boost compositional generalization. Extensive experiments on two challenging benchmarks validate the effectiveness and generalizability of our proposed method. Our code is available at https://github.com/zxccade/SHINE.