 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Hallucination in Large Vision-Language Models
Feb 01, 2024
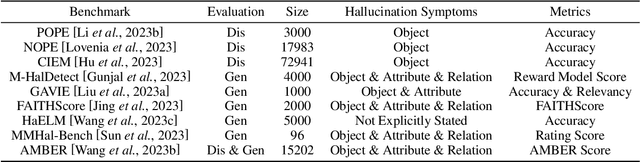
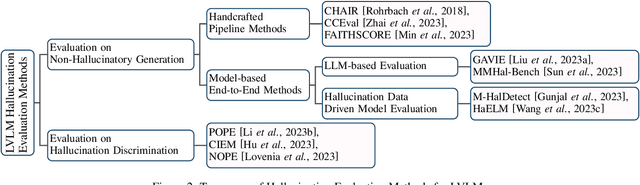
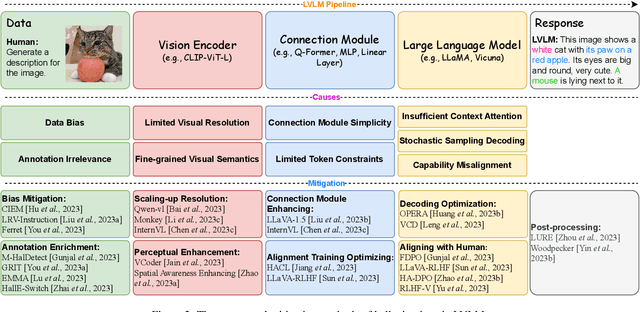
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
Align before Adapt: Leveraging Entity-to-Region Alignments for Generalizable Video Action Recognition
Nov 27, 2023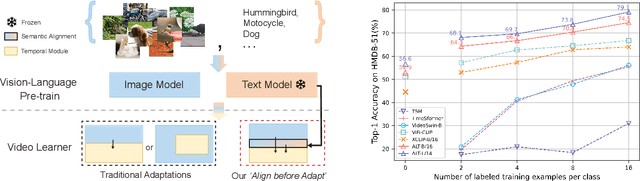
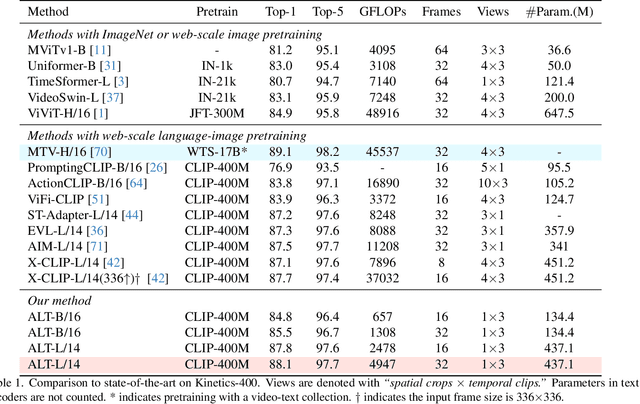
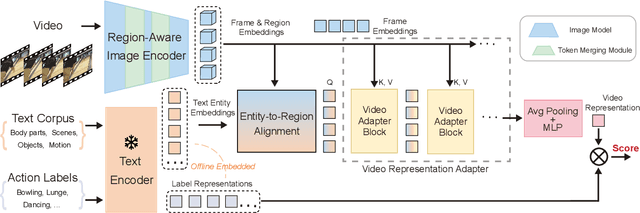
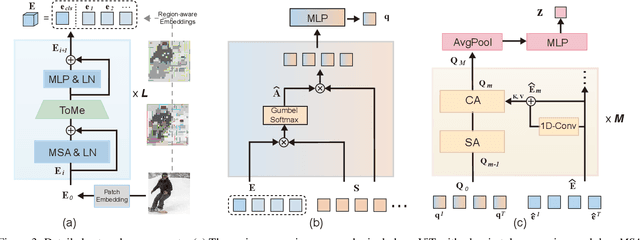
Large-scale visual-language pre-trained models have achieved significant success in various video tasks. However, most existing methods follow an "adapt then align" paradigm, which adapts pre-trained image encoders to model video-level representations and utilizes one-hot or text embedding of the action labels for supervision. This paradigm overlooks the challenge of mapping from static images to complicated activity concepts. In this paper, we propose a novel "Align before Adapt" (ALT) paradigm. Prior to adapting to video representation learning, we exploit the entity-to-region alignments for each frame. The alignments are fulfilled by matching the region-aware image embeddings to an offline-constructed text corpus. With the aligned entities, we feed their text embeddings to a transformer-based video adapter as the queries, which can help extract the semantics of the most important entities from a video to a vector. This paradigm reuses the visual-language alignment of VLP during adaptation and tries to explain an action by the underlying entities. This helps understand actions by bridging the gap with complex activity semantics, particularly when facing unfamiliar or unseen categories. ALT achieves competitive performance and superior generalizability while requiring significantly low computational costs. In fully supervised scenarios, it achieves 88.1% top-1 accuracy on Kinetics-400 with only 4947 GFLOPs. In 2-shot experiments, ALT outperforms the previous state-of-the-art by 7.1% and 9.2% on HMDB-51 and UCF-101, respectively.
ChartDETR: A Multi-shape Detection Network for Visual Chart Recognition
Aug 15, 2023Visual chart recognition systems are gaining increasing attention due to the growing demand for automatically identifying table headers and values from chart images. Current methods rely on keypoint detection to estimate data element shapes in charts but suffer from grouping errors in post-processing. To address this issue, we propose ChartDETR, a transformer-based multi-shape detector that localizes keypoints at the corners of regular shapes to reconstruct multiple data elements in a single chart image. Our method predicts all data element shapes at once by introducing query groups in set prediction, eliminating the need for further postprocessing. This property allows ChartDETR to serve as a unified framework capable of representing various chart types without altering the network architecture, effectively detecting data elements of diverse shapes. We evaluated ChartDETR on three datasets, achieving competitive results across all chart types without any additional enhancements. For example, ChartDETR achieved an F1 score of 0.98 on Adobe Synthetic, significantly outperforming the previous best model with a 0.71 F1 score. Additionally, we obtained a new state-of-the-art result of 0.97 on ExcelChart400k. The code will be made publicly available.
TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition
Jun 28, 2021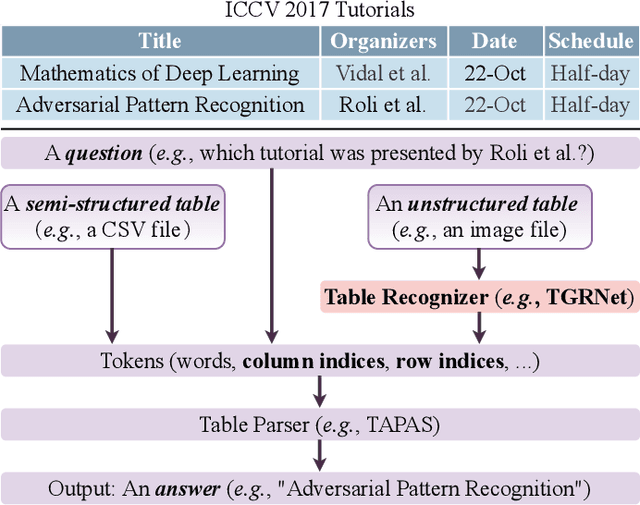
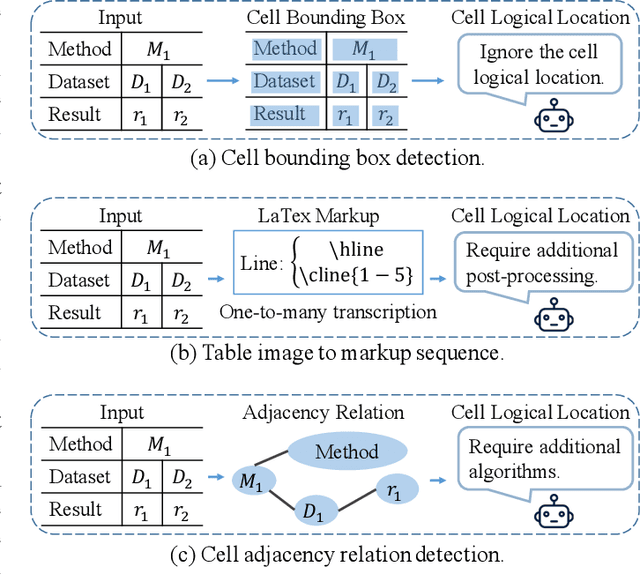
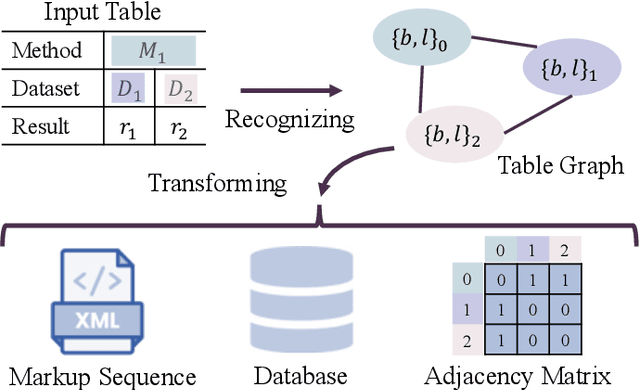
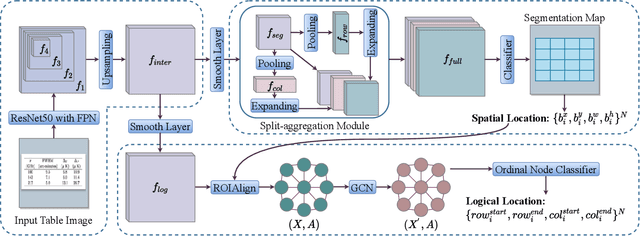
A table arranging data in rows and columns is a very effective data structure, which has been widely used in business and scientific research. Considering large-scale tabular data in online and offline documents, automatic table recognition has attracted increasing attention from the document analysis community. Though human can easily understand the structure of tables, it remains a challenge for machines to understand that, especially due to a variety of different table layouts and styles. Existing methods usually model a table as either the markup sequence or the adjacency matrix between different table cells, failing to address the importance of the logical location of table cells, e.g., a cell is located in the first row and the second column of the table. In this paper, we reformulate the problem of table structure recognition as the table graph reconstruction, and propose an end-to-end trainable table graph reconstruction network (TGRNet) for table structure recognition. Specifically, the proposed method has two main branches, a cell detection branch and a cell logical location branch, to jointly predict the spatial location and the logical location of different cells. Experimental results on three popular table recognition datasets and a new dataset with table graph annotations (TableGraph-350K) demonstrate the effectiveness of the proposed TGRNet for table structure recognition. Code and annotations will be made publicly available.