 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2RBox-v2: Boosting HBox-supervised Oriented Object Detection via Symmetric Learning
Apr 11, 2023With the increasing demand for oriented object detection e.g. in autonomous driving and remote sensing, the oriented annotation has become a labor-intensive work. To make full use of existing horizontally annotated datasets and reduce the annotation cost, a weakly-supervised detector H2RBox for learning the rotated box (RBox) from the horizontal box (HBox) has been proposed and received great attention. This paper presents a new version, H2RBox-v2, to further bridge the gap between HBox-supervised and RBox-supervised oriented object detection. While exploiting axisymmetry via flipping and rotating consistencies is available through our theoretical analysis, H2RBox-v2, using a weakly-supervised branch similar to H2RBox, is embedded with a novel self-supervised branch that learns orientations from the symmetry inherent in the image of objects. Complemented by modules to cope with peripheral issues, e.g. angular periodicity, a stable and effective solution is achieved. To our knowledge, H2RBox-v2 is the first symmetry-supervised paradigm for oriented object detection. Compared to H2RBox, our method is less susceptible to low annotation quality and insufficient training data, which in such cases is expected to give a competitive performance much closer to fully-supervised oriented object detectors. Specifically, the performance comparison between H2RBox-v2 and Rotated FCOS on DOTA-v1.0/1.5/2.0 is 72.31%/64.76%/50.33% vs. 72.44%/64.53%/51.77%, 89.66% vs. 88.99% on HRSC, and 42.27% vs. 41.25% on FAIR1M.
H2RBox: Horizonal Box Annotation is All You Need for Oriented Object Detection
Oct 13, 2022
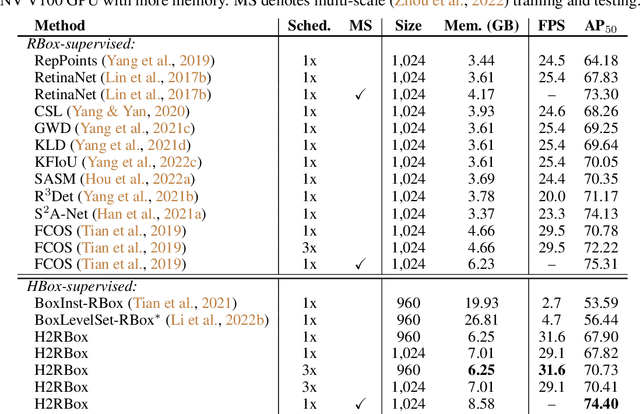
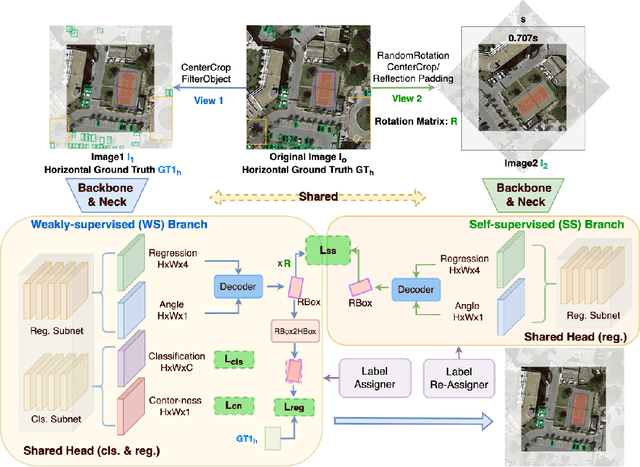
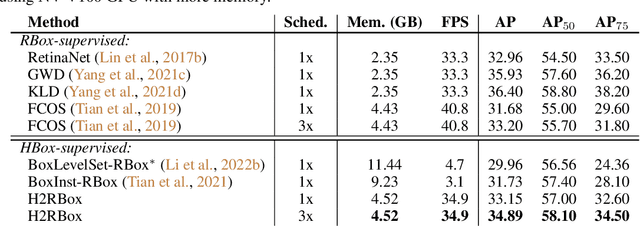
Oriented object detection emerges in many applications from aerial images to autonomous driving, while many existing detection benchmarks are annotated with horizontal bounding box only which is also less costive than fine-grained rotated box, leading to a gap between the readily available training corpus and the rising demand for oriented object detection. This paper proposes a simple yet effective oriented object detection approach called H2RBox merely using horizontal box annotation for weakly-supervised training, which closes the above gap and shows competitive performance even against those trained with rotated boxes. The cores of our method are weakly- and self-supervised learning, which predicts the angle of the object by learning the consistency of two different views. To our best knowledge, H2RBox is the first horizontal box annotation-based oriented object detector. Compared to an alternative i.e. horizontal box-supervised instance segmentation with our post adaption to oriented object detection, our approach is not susceptible to the prediction quality of mask and can perform more robustly in complex scenes containing a large number of dense objects and outliers. Experimental results show that H2RBox has significant performance and speed advantages over horizontal box-supervised instance segmentation methods, as well as lower memory requirements. While compared to rotated box-supervised oriented object detectors, our method shows very close performance and speed, and even surpasses them in some cases. The source code is available at https://github.com/yangxue0827/h2rbox-mmrotate.
Detecting Rotated Objects as Gaussian Distributions and Its 3-D Generalization
Sep 22, 2022

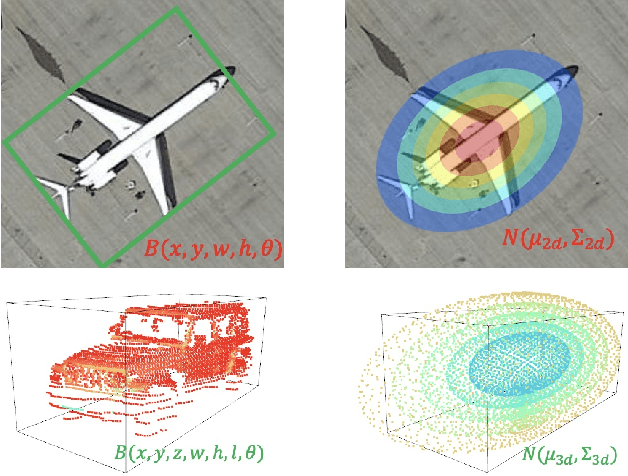

Existing detection methods commonly use a parameterized bounding box (BBox) to model and detect (horizontal) objects and an additional rotation angle parameter is used for rotated objects. We argue that such a mechanism has fundamental limitations in building an effective regression loss for rotation detection, especially for high-precision detection with high IoU (e.g. 0.75). Instead, we propose to model the rotated objects as Gaussian distributions. A direct advantage is that our new regression loss regarding the distance between two Gaussians e.g. Kullback-Leibler Divergence (KLD), can well align the actual detection performance metric, which is not well addressed in existing methods. Moreover, the two bottlenecks i.e. boundary discontinuity and square-like problem also disappear. We also propose an efficient Gaussian metric-based label assignment strategy to further boost the performance. Interestingly, by analyzing the BBox parameters' gradients under our Gaussian-based KLD loss, we show that these parameters are dynamically updated with interpretable physical meaning, which help explain the effectiveness of our approach, especially for high-precision detection. We extend our approach from 2-D to 3-D with a tailored algorithm design to handle the heading estimation, and experimental results on twelve public datasets (2-D/3-D, aerial/text/face images) with various base detectors show its superiority.
MMRotate: A Rotated Object Detection Benchmark using Pytorch
Apr 28, 2022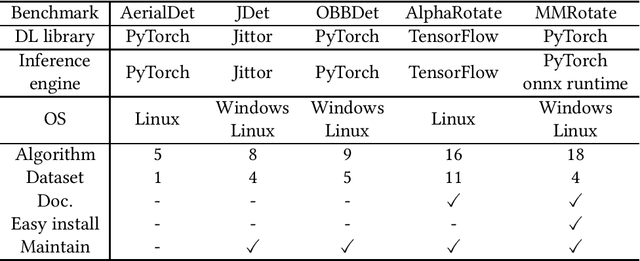
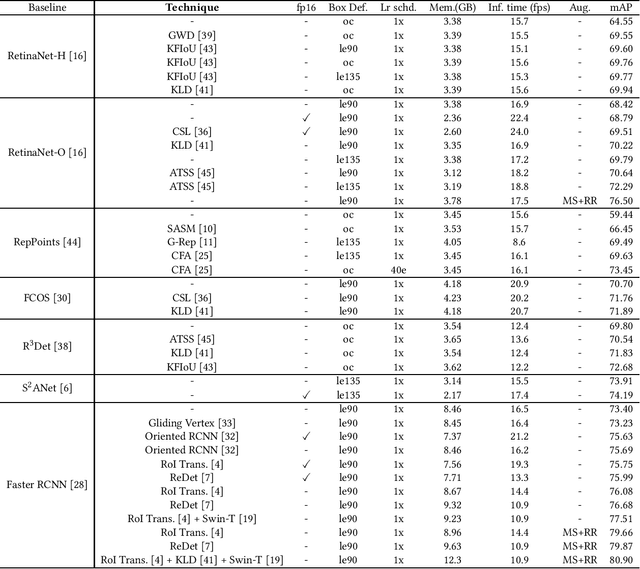
We present an open-source toolbox, named MMRotate, which provides a coherent algorithm framework of training, inferring, and evaluation for the popular rotated object detection algorithm based on deep learning. MMRotate implements 18 state-of-the-art algorithms and supports the three most frequently used angle definition methods. To facilitate future research and industrial applications of rotated object detection-related problems, we also provide a large number of trained models and detailed benchmarks to give insights into the performance of rotated object detection. MMRotate is publicly released at https://github.com/open-mmlab/mmrotate.
The KFIoU Loss for Rotated Object Detection
Feb 01, 2022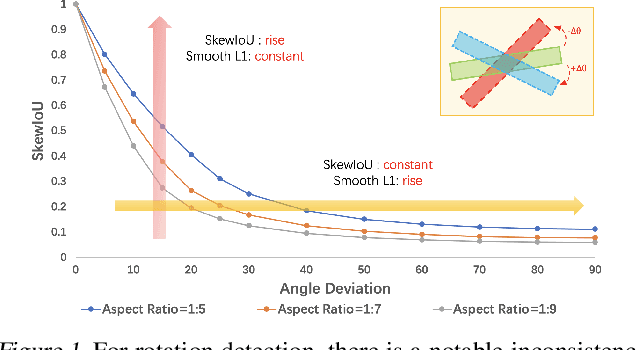
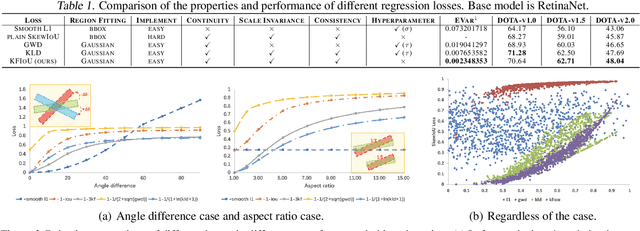
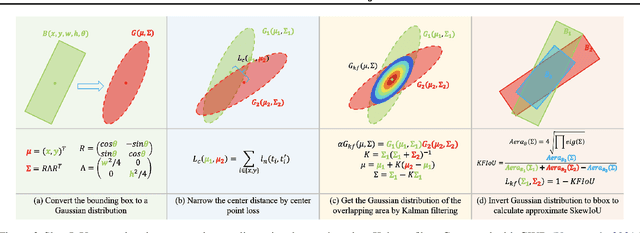

Differing from the well-developed horizontal object detection area whereby the computing-friendly IoU based loss is readily adopted and well fits with the detection metrics. In contrast, rotation detectors often involve a more complicated loss based on SkewIoU which is unfriendly to gradient-based training. In this paper, we argue that one effective alternative is to devise an approximate loss who can achieve trend-level alignment with SkewIoU loss instead of the strict value-level identity. Specifically, we model the objects as Gaussian distribution and adopt Kalman filter to inherently mimic the mechanism of SkewIoU by its definition, and show its alignment with the SkewIoU at trend-level. This is in contrast to recent Gaussian modeling based rotation detectors e.g. GWD, KLD that involves a human-specified distribution distance metric which requires additional hyperparameter tuning. The resulting new loss called KFIoU is easier to implement and works better compared with exact SkewIoU, thanks to its full differentiability and ability to handle the non-overlapping cases. We further extend our technique to the 3-D case which also suffers from the same issues as 2-D detection. Extensive results on various public datasets (2-D/3-D, aerial/text/face images) with different base detectors show the effectiveness of our approach.