 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Don't Tell: Morphing Latent Reasoning into Image Generation
Feb 02, 2026Text-to-image (T2I) generation has achieved remarkable progress, yet existing methods often lack the ability to dynamically reason and refine during generation--a hallmark of human creativity. Current reasoning-augmented paradigms most rely on explicit thought processes, where intermediate reasoning is decoded into discrete text at fixed steps with frequent image decoding and re-encoding, leading to inefficiencies, information loss, and cognitive mismatches. To bridge this gap, we introduce LatentMorph, a novel framework that seamlessly integrates implicit latent reasoning into the T2I generation process. At its core, LatentMorph introduces four lightweight components: (i) a condenser for summarizing intermediate generation states into compact visual memory, (ii) a translator for converting latent thoughts into actionable guidance, (iii) a shaper for dynamically steering next image token predictions, and (iv) an RL-trained invoker for adaptively determining when to invoke reasoning. By performing reasoning entirely in continuous latent spaces, LatentMorph avoids the bottlenecks of explicit reasoning and enables more adaptive self-refinement. Extensive experiments demonstrate that LatentMorph (I) enhances the base model Janus-Pro by $16\%$ on GenEval and $25\%$ on T2I-CompBench; (II) outperforms explicit paradigms (e.g., TwiG) by $15\%$ and $11\%$ on abstract reasoning tasks like WISE and IPV-Txt, (III) while reducing inference time by $44\%$ and token consumption by $51\%$; and (IV) exhibits $71\%$ cognitive alignment with human intuition on reasoning invocation.
A4-Agent: An Agentic Framework for Zero-Shot Affordance Reasoning
Dec 16, 2025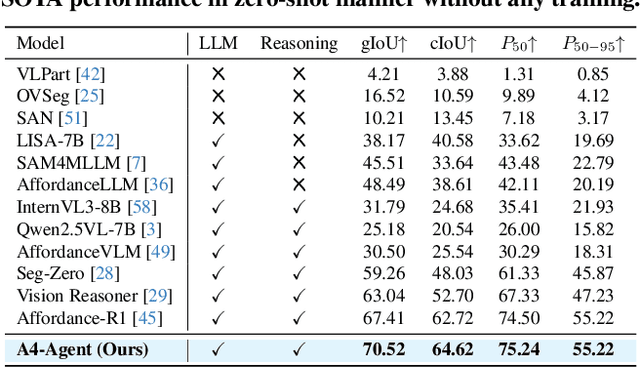
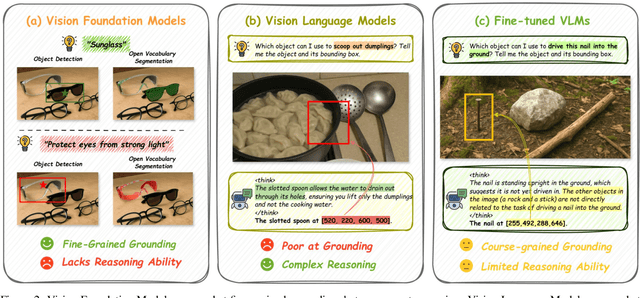
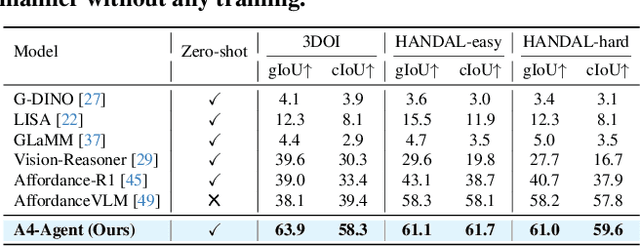
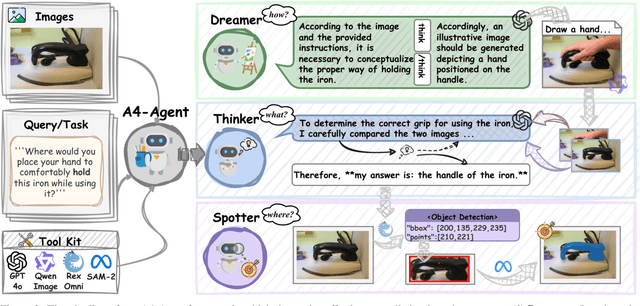
Affordance prediction, which identifies interaction regions on objects based on language instructions, is critical for embodied AI. Prevailing end-to-end models couple high-level reasoning and low-level grounding into a single monolithic pipeline and rely on training over annotated datasets, which leads to poor generalization on novel objects and unseen environments. In this paper, we move beyond this paradigm by proposing A4-Agent, a training-free agentic framework that decouples affordance prediction into a three-stage pipeline. Our framework coordinates specialized foundation models at test time: (1) a $\textbf{Dreamer}$ that employs generative models to visualize $\textit{how}$ an interaction would look; (2) a $\textbf{Thinker}$ that utilizes large vision-language models to decide $\textit{what}$ object part to interact with; and (3) a $\textbf{Spotter}$ that orchestrates vision foundation models to precisely locate $\textit{where}$ the interaction area is. By leveraging the complementary strengths of pre-trained models without any task-specific fine-tuning, our zero-shot framework significantly outperforms state-of-the-art supervised methods across multiple benchmarks and demonstrates robust generalization to real-world settings.
TiViBench: Benchmarking Think-in-Video Reasoning for Video Generative Models
Nov 17, 2025The rapid evolution of video generative models has shifted their focus from producing visually plausible outputs to tackling tasks requiring physical plausibility and logical consistency. However, despite recent breakthroughs such as Veo 3's chain-of-frames reasoning, it remains unclear whether these models can exhibit reasoning capabilities similar to large language models (LLMs). Existing benchmarks predominantly evaluate visual fidelity and temporal coherence, failing to capture higher-order reasoning abilities. To bridge this gap, we propose TiViBench, a hierarchical benchmark specifically designed to evaluate the reasoning capabilities of image-to-video (I2V) generation models. TiViBench systematically assesses reasoning across four dimensions: i) Structural Reasoning & Search, ii) Spatial & Visual Pattern Reasoning, iii) Symbolic & Logical Reasoning, and iv) Action Planning & Task Execution, spanning 24 diverse task scenarios across 3 difficulty levels. Through extensive evaluations, we show that commercial models (e.g., Sora 2, Veo 3.1) demonstrate stronger reasoning potential, while open-source models reveal untapped potential that remains hindered by limited training scale and data diversity. To further unlock this potential, we introduce VideoTPO, a simple yet effective test-time strategy inspired by preference optimization. By performing LLM self-analysis on generated candidates to identify strengths and weaknesses, VideoTPO significantly enhances reasoning performance without requiring additional training, data, or reward models. Together, TiViBench and VideoTPO pave the way for evaluating and advancing reasoning in video generation models, setting a foundation for future research in this emerging field.
Can Large Pretrained Depth Estimation Models Help With Image Dehazing?
Aug 01, 2025Image dehazing remains a challenging problem due to the spatially varying nature of haze in real-world scenes. While existing methods have demonstrated the promise of large-scale pretrained models for image dehazing, their architecture-specific designs hinder adaptability across diverse scenarios with different accuracy and efficiency requirements. In this work, we systematically investigate the generalization capability of pretrained depth representations-learned from millions of diverse images-for image dehazing. Our empirical analysis reveals that the learned deep depth features maintain remarkable consistency across varying haze levels. Building on this insight, we propose a plug-and-play RGB-D fusion module that seamlessly integrates with diverse dehazing architectures. Extensive experiments across multiple benchmarks validate both the effectiveness and broad applicability of our approach.
Generic Intent Representation in Web Search
Jul 24, 2019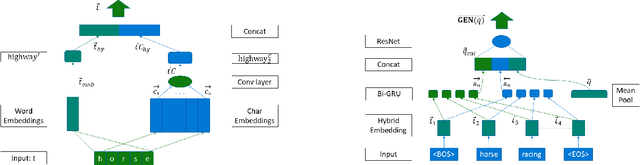


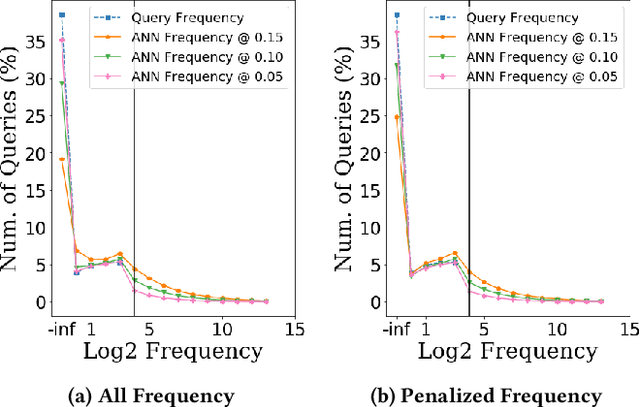
This paper presents GEneric iNtent Encoder (GEN Encoder) which learns a distributed representation space for user intent in search. Leveraging large scale user clicks from Bing search logs as weak supervision of user intent, GEN Encoder learns to map queries with shared clicks into similar embeddings end-to-end and then finetunes on multiple paraphrase tasks. Experimental results on an intrinsic evaluation task - query intent similarity modeling - demonstrate GEN Encoder's robust and significant advantages over previous representation methods. Ablation studies reveal the crucial role of learning from implicit user feedback in representing user intent and the contributions of multi-task learning in representation generality. We also demonstrate that GEN Encoder alleviates the sparsity of tail search traffic and cuts down half of the unseen queries by using an efficient approximate nearest neighbor search to effectively identify previous queries with the same search intent. Finally, we demonstrate distances between GEN encodings reflect certain information seeking behaviors in search sessions.