 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaMoCo: Instruction Tuning of Large Language Models for Optimization Code Generation
Paper and Code

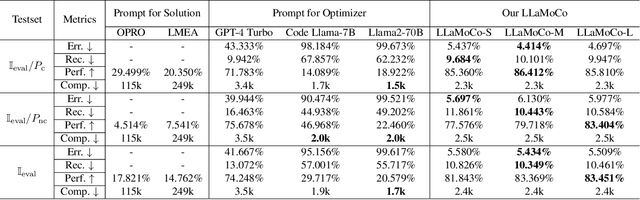
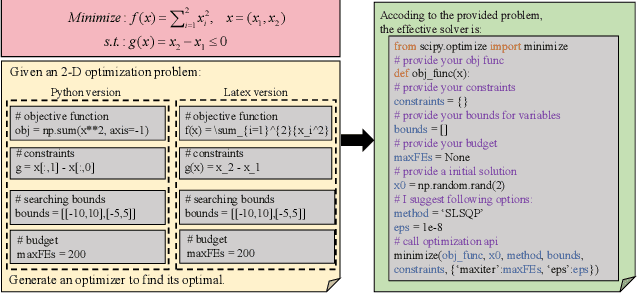
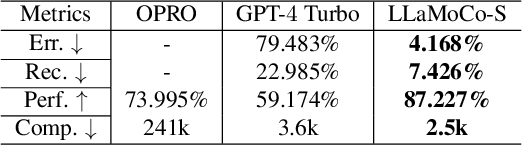
Recent research explores optimization using large language models (LLMs) by either iteratively seeking next-step solutions from LLMs or directly prompting LLMs for an optimizer. However, these approaches exhibit inherent limitations, including low operational efficiency, high sensitivity to prompt design, and a lack of domain-specific knowledge. We introduce LLaMoCo, the first instruction-tuning framework designed to adapt LLMs for solving optimization problems in a code-to-code manner. Specifically, we establish a comprehensive instruction set containing well-described problem prompts and effective optimization codes. We then develop a novel two-phase learning strategy that incorporates a contrastive learning-based warm-up procedure before the instruction-tuning phase to enhance the convergence behavior during model fine-tuning. The experiment results demonstrate that a CodeGen (350M) model fine-tuned by our LLaMoCo achieves superior optimization performance compared to GPT-4 Turbo and the other competitors across both synthetic and realistic problem sets. The fine-tuned model and the usage instructions are available at https://anonymous.4open.science/r/LLaMoCo-722A.