 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqAfford: Sequential 3D Affordance Reasoning via Multimodal Large Language Model
Dec 02, 2024

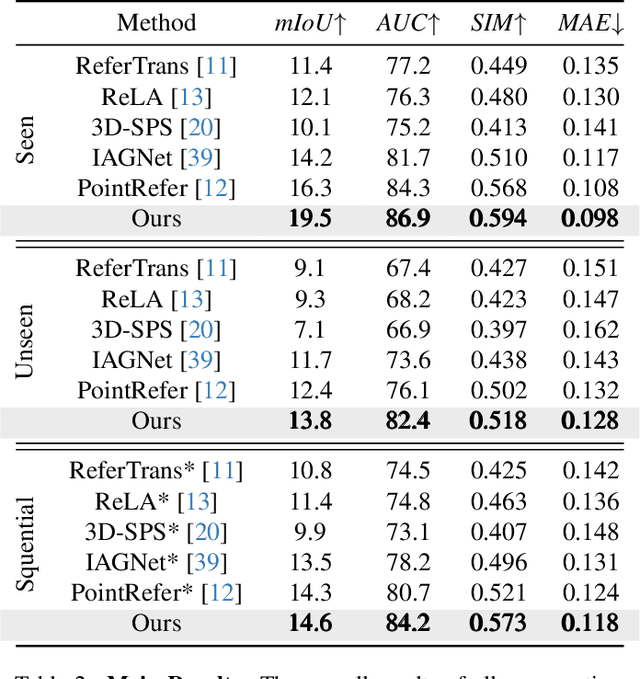
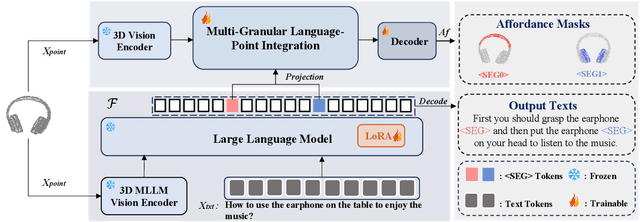
3D affordance segmentation aims to link human instructions to touchable regions of 3D objects for embodied manipulations. Existing efforts typically adhere to single-object, single-affordance paradigms, where each affordance type or explicit instruction strictly corresponds to a specific affordance region and are unable to handle long-horizon tasks. Such a paradigm cannot actively reason about complex user intentions that often imply sequential affordances. In this paper, we introduce the Sequential 3D Affordance Reasoning task, which extends the traditional paradigm by reasoning from cumbersome user intentions and then decomposing them into a series of segmentation maps. Toward this, we construct the first instruction-based affordance segmentation benchmark that includes reasoning over both single and sequential affordances, comprising 180K instruction-point cloud pairs. Based on the benchmark, we propose our model, SeqAfford, to unlock the 3D multi-modal large language model with additional affordance segmentation abilities, which ensures reasoning with world knowledge and fine-grained affordance grounding in a cohesive framework. We further introduce a multi-granular language-point integration module to endow 3D dense prediction. Extensive experimental evaluations show that our model excels over well-established methods and exhibits open-world generalization with sequential reasoning abilities.
HybridGait: A Benchmark for Spatial-Temporal Cloth-Changing Gait Recognition with Hybrid Explorations
Dec 30, 2023Existing gait recognition benchmarks mostly include minor clothing variations in the laboratory environments, but lack persistent changes in appearance over time and space. In this paper, we propose the first in-the-wild benchmark CCGait for cloth-changing gait recognition, which incorporates diverse clothing changes, indoor and outdoor scenes, and multi-modal statistics over 92 days. To further address the coupling effect of clothing and viewpoint variations, we propose a hybrid approach HybridGait that exploits both temporal dynamics and the projected 2D information of 3D human meshes. Specifically, we introduce a Canonical Alignment Spatial-Temporal Transformer (CA-STT) module to encode human joint position-aware features, and fully exploit 3D dense priors via a Silhouette-guided Deformation with 3D-2D Appearance Projection (SilD) strategy. Our contributions are twofold: we provide a challenging benchmark CCGait that captures realistic appearance changes across an expanded and space, and we propose a hybrid framework HybridGait that outperforms prior works on CCGait and Gait3D benchmarks. Our project page is available at https://github.com/HCVLab/HybridGait.
Contextually Affinitive Neighborhood Refinery for Deep Clustering
Dec 12, 2023
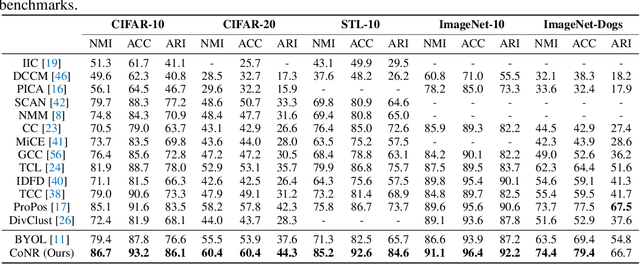


Previous endeavors in self-supervised learning have enlightened the research of deep clustering from an instance discrimination perspective. Built upon this foundation, recent studies further highlight the importance of grouping semantically similar instances. One effective method to achieve this is by promoting the semantic structure preserved by neighborhood consistency. However, the samples in the local neighborhood may be limited due to their close proximity to each other, which may not provide substantial and diverse supervision signals. Inspired by the versatile re-ranking methods in the context of image retrieval, we propose to employ an efficient online re-ranking process to mine more informative neighbors in a Contextually Affinitive (ConAff) Neighborhood, and then encourage the cross-view neighborhood consistency. To further mitigate the intrinsic neighborhood noises near cluster boundaries, we propose a progressively relaxed boundary filtering strategy to circumvent the issues brought by noisy neighbors. Our method can be easily integrated into the generic self-supervised frameworks and outperforms the state-of-the-art methods on several popular benchmarks.
Lifelong Person Re-Identification via Knowledge Refreshing and Consolidation
Nov 29, 2022



Lifelong person re-identification (LReID) is in significant demand for real-world development as a large amount of ReID data is captured from diverse locations over time and cannot be accessed at once inherently. However, a key challenge for LReID is how to incrementally preserve old knowledge and gradually add new capabilities to the system. Unlike most existing LReID methods, which mainly focus on dealing with catastrophic forgetting, our focus is on a more challenging problem, which is, not only trying to reduce the forgetting on old tasks but also aiming to improve the model performance on both new and old tasks during the lifelong learning process. Inspired by the biological process of human cognition where the somatosensory neocortex and the hippocampus work together in memory consolidation, we formulated a model called Knowledge Refreshing and Consolidation (KRC) that achieves both positive forward and backward transfer. More specifically, a knowledge refreshing scheme is incorporated with the knowledge rehearsal mechanism to enable bi-directional knowledge transfer by introducing a dynamic memory model and an adaptive working model. Moreover, a knowledge consolidation scheme operating on the dual space further improves model stability over the long term. Extensive evaluations show KRC's superiority over the state-of-the-art LReID methods on challenging pedestrian benchmarks.