 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMark: Artificial Intelligence Generated Content Identification Toolkit
Dec 13, 2025The rapid proliferation of Artificial Intelligence Generated Content has precipitated a crisis of trust and urgent regulatory demands. However, existing identification tools suffer from fragmentation and a lack of support for visible compliance marking. To address these gaps, we introduce the \textbf{UniMark}, an open-source, unified framework for multimodal content governance. Our system features a modular unified engine that abstracts complexities across text, image, audio, and video modalities. Crucially, we propose a novel dual-operation strategy, natively supporting both \emph{Hidden Watermarking} for copyright protection and \emph{Visible Marking} for regulatory compliance. Furthermore, we establish a standardized evaluation framework with three specialized benchmarks (Image/Video/Audio-Bench) to ensure rigorous performance assessment. This toolkit bridges the gap between advanced algorithms and engineering implementation, fostering a more transparent and secure digital ecosystem.
LLM Meets the Sky: Heuristic Multi-Agent Reinforcement Learning for Secure Heterogeneous UAV Networks
Jul 23, 2025



This work tackles the physical layer security (PLS) problem of maximizing the secrecy rate in heterogeneous UAV networks (HetUAVNs) under propulsion energy constraints. Unlike prior studies that assume uniform UAV capabilities or overlook energy-security trade-offs, we consider a realistic scenario where UAVs with diverse payloads and computation resources collaborate to serve ground terminals in the presence of eavesdroppers. To manage the complex coupling between UAV motion and communication, we propose a hierarchical optimization framework. The inner layer uses a semidefinite relaxation (SDR)-based S2DC algorithm combining penalty functions and difference-of-convex (d.c.) programming to solve the secrecy precoding problem with fixed UAV positions. The outer layer introduces a Large Language Model (LLM)-guided heuristic multi-agent reinforcement learning approach (LLM-HeMARL) for trajectory optimization. LLM-HeMARL efficiently incorporates expert heuristics policy generated by the LLM, enabling UAVs to learn energy-aware, security-driven trajectories without the inference overhead of real-time LLM calls. The simulation results show that our method outperforms existing baselines in secrecy rate and energy efficiency, with consistent robustness across varying UAV swarm sizes and random seeds.
SS-CTML: Self-Supervised Cross-Task Mutual Learning for CT Image Reconstruction
Dec 31, 2024



Supervised deep-learning (SDL) techniques with paired training datasets have been widely studied for X-ray computed tomography (CT) image reconstruction. However, due to the difficulties of obtaining paired training datasets in clinical routine, the SDL methods are still away from common uses in clinical practices. In recent years, self-supervised deep-learning (SSDL) techniques have shown great potential for the studies of CT image reconstruction. In this work, we propose a self-supervised cross-task mutual learning (SS-CTML) framework for CT image reconstruction. Specifically, a sparse-view scanned and a limited-view scanned sinogram data are first extracted from a full-view scanned sinogram data, which results in three individual reconstruction tasks, i.e., the full-view CT (FVCT) reconstruction, the sparse-view CT (SVCT) reconstruction, and limited-view CT (LVCT) reconstruction. Then, three neural networks are constructed for the three reconstruction tasks. Considering that the ultimate goals of the three tasks are all to reconstruct high-quality CT images, we therefore construct a set of cross-task mutual learning objectives for the three tasks, in which way, the three neural networks can be self-supervised optimized by learning from each other. Clinical datasets are adopted to evaluate the effectiveness of the proposed framework. Experimental results demonstrate that the SS-CTML framework can obtain promising CT image reconstruction performance in terms of both quantitative and qualitative measurements.
Crack-EdgeSAM Self-Prompting Crack Segmentation System for Edge Devices
Dec 10, 2024Structural health monitoring (SHM) is essential for the early detection of infrastructure defects, such as cracks in concrete bridge pier. but often faces challenges in efficiency and accuracy in complex environments. Although the Segment Anything Model (SAM) achieves excellent segmentation performance, its computational demands limit its suitability for real-time applications on edge devices. To address these challenges, this paper proposes Crack-EdgeSAM, a self-prompting crack segmentation system that integrates YOLOv8 for generating prompt boxes and a fine-tuned EdgeSAM model for crack segmentation. To ensure computational efficiency, the method employs ConvLoRA, a Parameter-Efficient Fine-Tuning (PEFT) technique, along with DiceFocalLoss to fine-tune the EdgeSAM model. Our experimental results on public datasets and the climbing robot automatic inspections demonstrate that the system achieves high segmentation accuracy and significantly enhanced inference speed compared to the most recent methods. Notably, the system processes 1024 x 1024 pixels images at 46 FPS on our PC and 8 FPS on Jetson Orin Nano.
Exploring Depth Information for Detecting Manipulated Face Videos
Nov 27, 2024
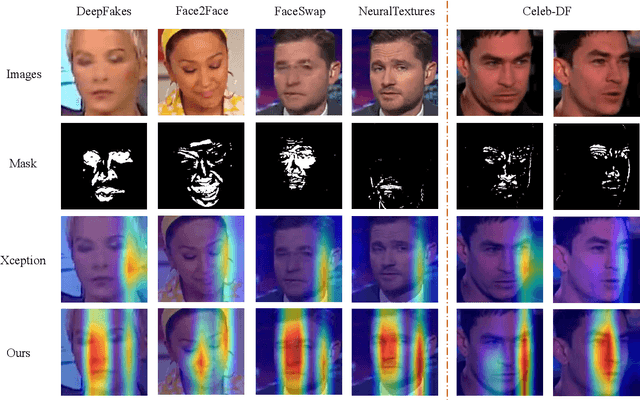


Face manipulation detection has been receiving a lot of attention for the reliability and security of the face images/videos. Recent studies focus on using auxiliary information or prior knowledge to capture robust manipulation traces, which are shown to be promising. As one of the important face features, the face depth map, which has shown to be effective in other areas such as face recognition or face detection, is unfortunately paid little attention to in literature for face manipulation detection. In this paper, we explore the possibility of incorporating the face depth map as auxiliary information for robust face manipulation detection. To this end, we first propose a Face Depth Map Transformer (FDMT) to estimate the face depth map patch by patch from an RGB face image, which is able to capture the local depth anomaly created due to manipulation. The estimated face depth map is then considered as auxiliary information to be integrated with the backbone features using a Multi-head Depth Attention (MDA) mechanism that is newly designed. We also propose an RGB-Depth Inconsistency Attention (RDIA) module to effectively capture the inter-frame inconsistency for multi-frame input. Various experiments demonstrate the advantage of our proposed method for face manipulation detection.
Covert Communication in Hybrid Microwave/mmWave A2G Systems with Transmission Mode Selection
Feb 01, 2023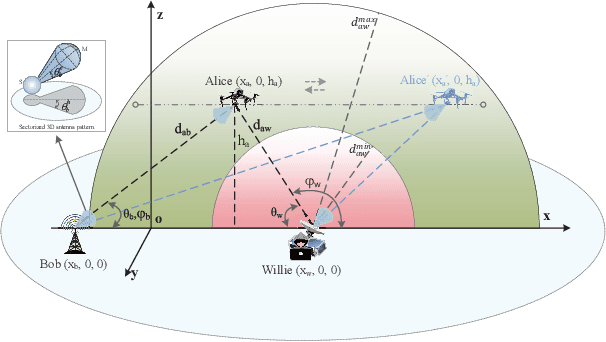
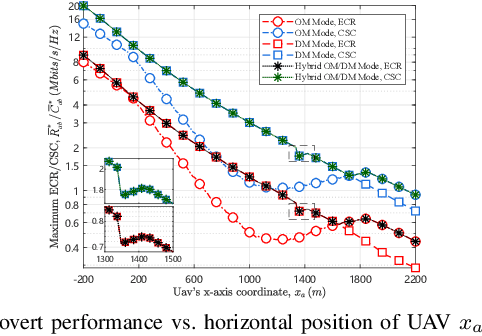
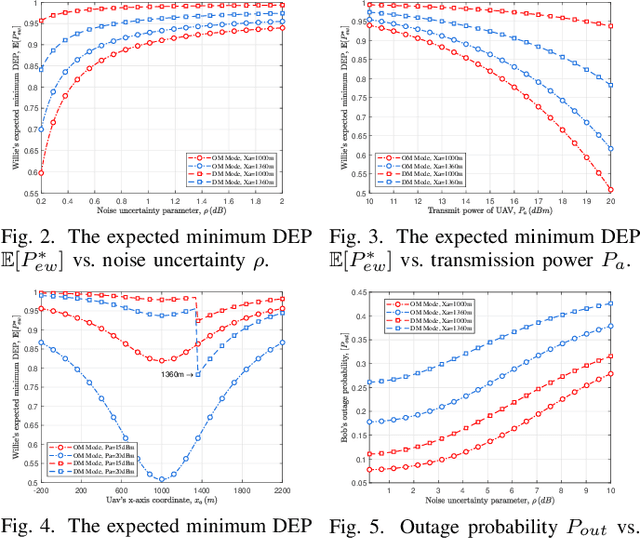
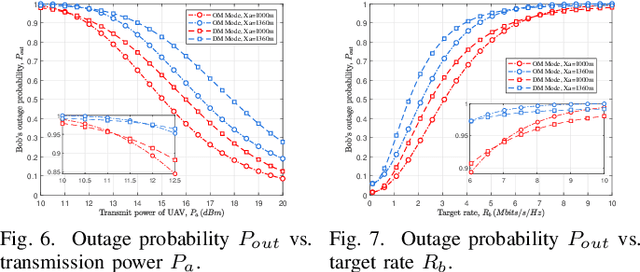
This paper investigates the covert communication in an air-to-ground (A2G) system, where a UAV (Alice) can adopt the omnidirectional microwave (OM) or directional mmWave (DM) transmission mode to transmit covert data to a ground user (Bob) while suffering from the detection of an adversary (Willie). For both the OM and DM modes, we first conduct theoretical analysis to reveal the inherent relationship between the transmit rate/transmit power and basic covert performance metrics in terms of detection error probability (DEP), effective covert rate (ECR), and covert Shannon capacity (CSC). To facilitate the transmission mode selection at Alice, we then explore the optimization of transmit rate and transmit power for ECR/CSC maximization under the OM and DM modes, and further propose a hybrid OM/DM transmission mode which allows the UAV to adaptively select between the OM and DM modes to achieve the maximum ECR and CSC at a given location of UAV. Finally, extensive numerical results are provided to illustrate the covert performances of the concerned A2G system under different transmission modes, and demonstrate that the hybrid OM/DM transmission mode outperforms the pure OM or DM mode in terms of covert performance.
Radon Inversion via Deep Learning
Aug 09, 2018Radon transform is widely used in physical and life sciences and one of its major applications is the X-ray computed tomography (X-ray CT), which is significant in modern health examination. The Radon inversion or image reconstruction is challenging due to the potentially defective radon projections. Conventionally, the reconstruction process contains several ad hoc stages to approximate the corresponding Radon inversion. Each of the stages is highly dependent on the results of the previous stage. In this paper, we propose a novel unified framework for Radon inversion via deep learning (DL). The Radon inversion can be approximated by the proposed framework with an end-to-end fashion instead of processing step-by-step with multiple stages. For simplicity, the proposed framework is short as iRadonMap (inverse Radon transform approximation). Specifically, we implement the iRadonMap as an appropriative neural network, of which the architecture can be divided into two segments. In the first segment, a learnable fully-connected filtering layer is used to filter the radon projections along the view-angle direction, which is followed by a learnable sinusoidal back-projection layer to transfer the filtered radon projections into an image. The second segment is a common neural network architecture to further improve the reconstruction performance in the image domain. The iRadonMap is overall optimized by training a large number of generic images from ImageNet database. To evaluate the performance of the iRadonMap, clinical patient data is used. Qualitative results show promising reconstruction performance of the iRadonMap.
Reinforcement Learning with External Knowledge and Two-Stage Q-functions for Predicting Popular Reddit Threads
Apr 20, 2017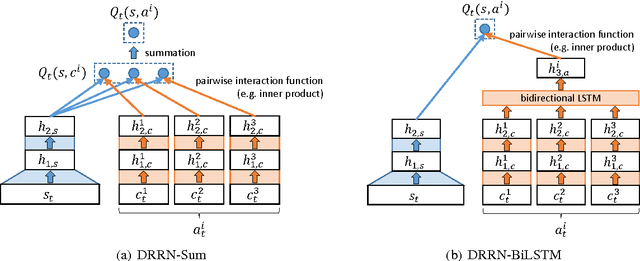
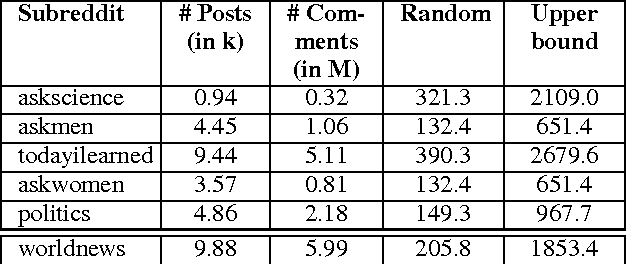
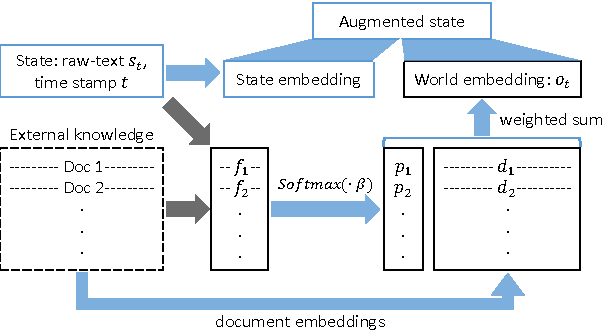
This paper addresses the problem of predicting popularity of comments in an online discussion forum using reinforcement learning, particularly addressing two challenges that arise from having natural language state and action spaces. First, the state representation, which characterizes the history of comments tracked in a discussion at a particular point, is augmented to incorporate the global context represented by discussions on world events available in an external knowledge source. Second, a two-stage Q-learning framework is introduced, making it feasible to search the combinatorial action space while also accounting for redundancy among sub-actions. We experiment with five Reddit communities, showing that the two methods improve over previous reported results on this task.
Deep Reinforcement Learning with a Combinatorial Action Space for Predicting Popular Reddit Threads
Sep 17, 2016
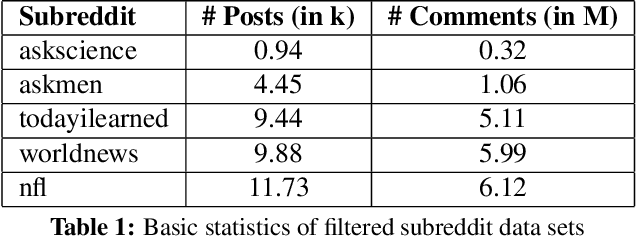
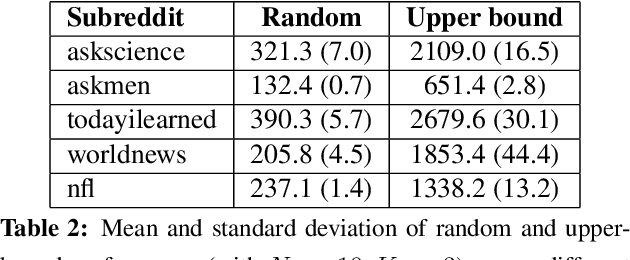
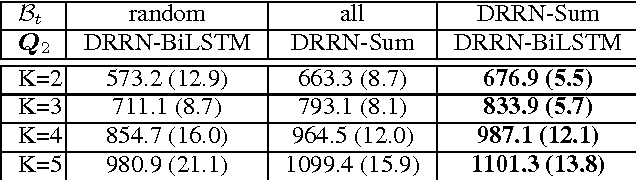
We introduce an online popularity prediction and tracking task as a benchmark task for reinforcement learning with a combinatorial, natural language action space. A specified number of discussion threads predicted to be popular are recommended, chosen from a fixed window of recent comments to track. Novel deep reinforcement learning architectures are studied for effective modeling of the value function associated with actions comprised of interdependent sub-actions. The proposed model, which represents dependence between sub-actions through a bi-directional LSTM, gives the best performance across different experimental configurations and domains, and it also generalizes well with varying numbers of recommendation requests.
Deep Reinforcement Learning with a Natural Language Action Space
Jun 08, 2016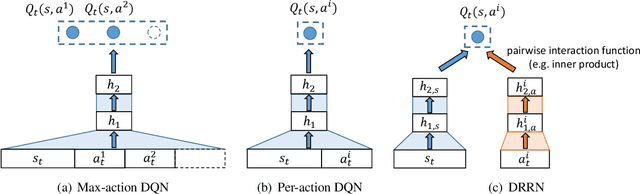
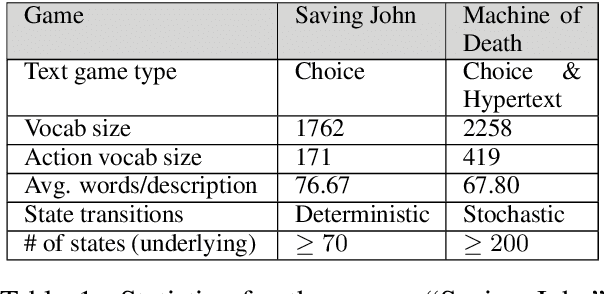
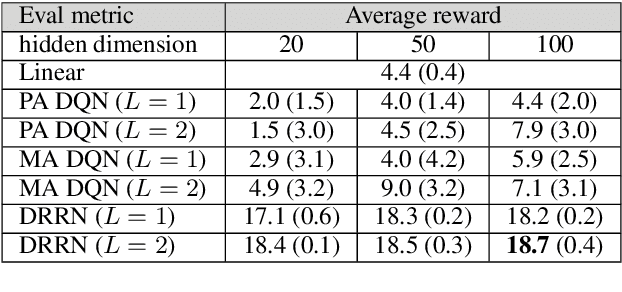
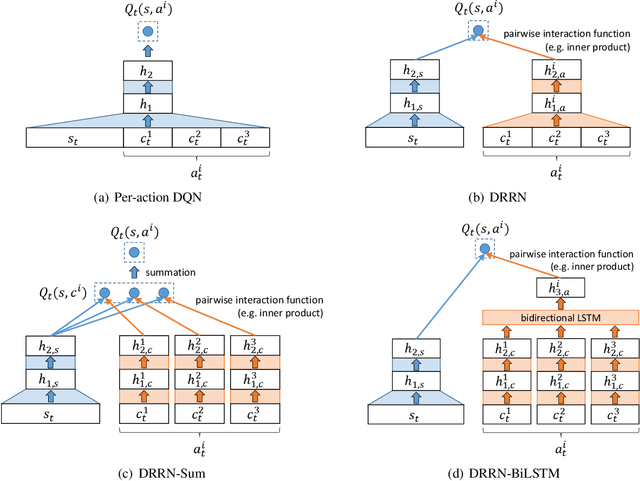
This paper introduces a novel architecture for reinforcement learning with deep neural networks designed to handle state and action spaces characterized by natural language, as found in text-based games. Termed a deep reinforcement relevance network (DRRN), the architecture represents action and state spaces with separate embedding vectors, which are combined with an interaction function to approximate the Q-function in reinforcement learning. We evaluate the DRRN on two popular text games, showing superior performance over other deep Q-learning architectures. Experiments with paraphrased action descriptions show that the model is extracting meaning rather than simply memorizing strings of text.