 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSS Mentor A framework for improving developers contributions via deep reinforcement learning
Oct 24, 2022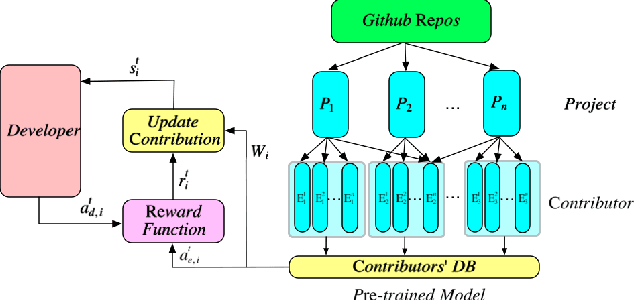
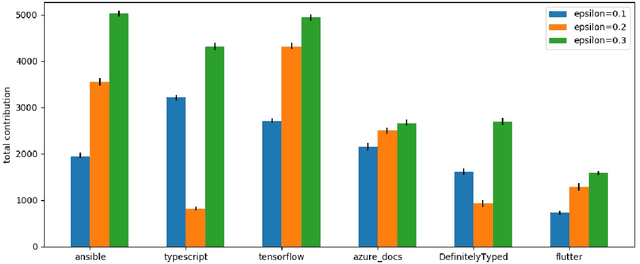
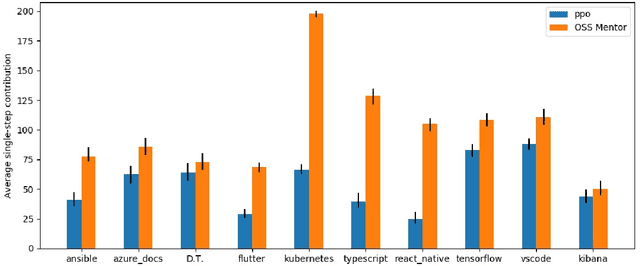
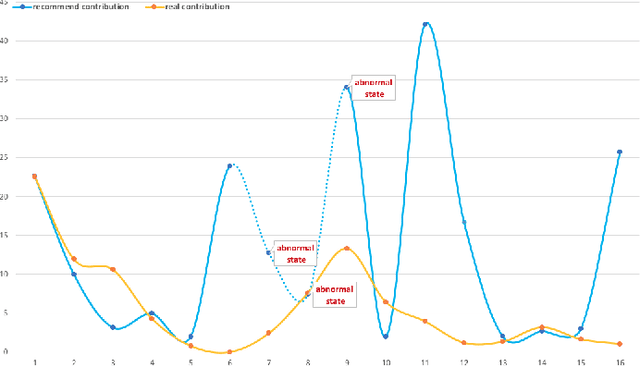
In open source project governance, there has been a lot of concern about how to measure developers' contributions. However, extremely sparse work has focused on enabling developers to improve their contributions, while it is significant and valuable. In this paper, we introduce a deep reinforcement learning framework named Open Source Software(OSS) Mentor, which can be trained from empirical knowledge and then adaptively help developers improve their contributions. Extensive experiments demonstrate that OSS Mentor significantly outperforms excellent experimental results. Moreover, it is the first time that the presented framework explores deep reinforcement learning techniques to manage open source software, which enables us to design a more robust framework to improve developers' contributions.
PVNAS: 3D Neural Architecture Search with Point-Voxel Convolution
Apr 26, 2022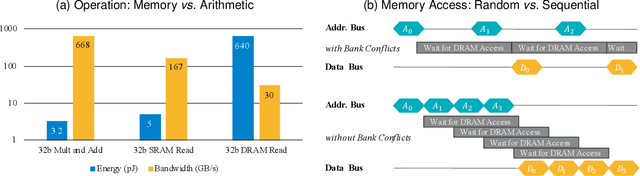
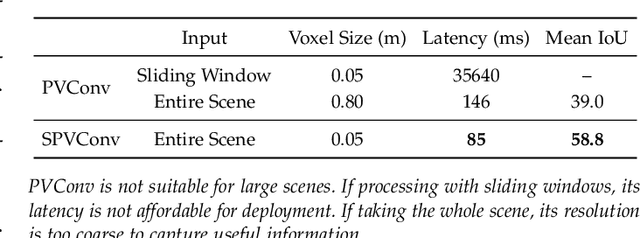
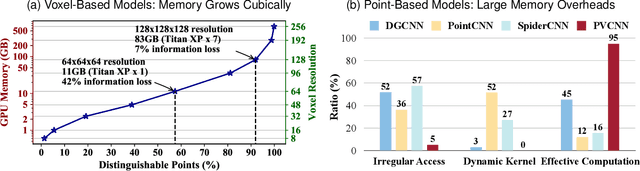
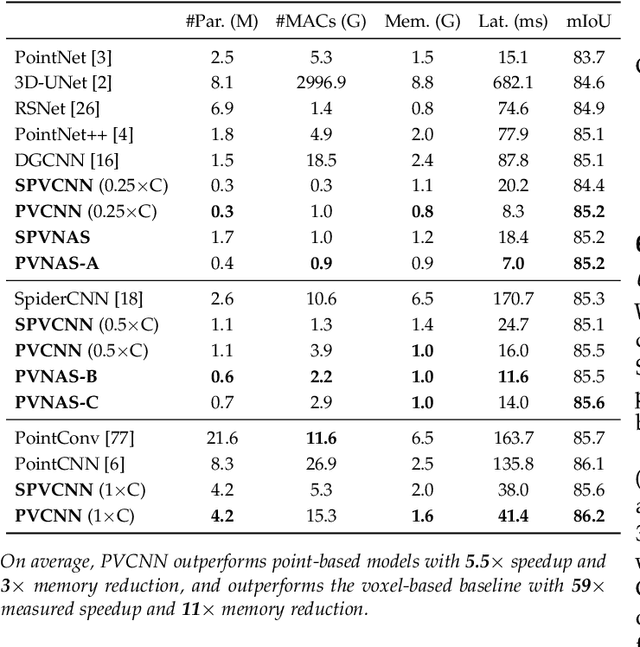
3D neural networks are widely used in real-world applications (e.g., AR/VR headsets, self-driving cars). They are required to be fast and accurate; however, limited hardware resources on edge devices make these requirements rather challenging. Previous work processes 3D data using either voxel-based or point-based neural networks, but both types of 3D models are not hardware-efficient due to the large memory footprint and random memory access. In this paper, we study 3D deep learning from the efficiency perspective. We first systematically analyze the bottlenecks of previous 3D methods. We then combine the best from point-based and voxel-based models together and propose a novel hardware-efficient 3D primitive, Point-Voxel Convolution (PVConv). We further enhance this primitive with the sparse convolution to make it more effective in processing large (outdoor) scenes. Based on our designed 3D primitive, we introduce 3D Neural Architecture Search (3D-NAS) to explore the best 3D network architecture given a resource constraint. We evaluate our proposed method on six representative benchmark datasets, achieving state-of-the-art performance with 1.8-23.7x measured speedup. Furthermore, our method has been deployed to the autonomous racing vehicle of MIT Driverless, achieving larger detection range, higher accuracy and lower latency.
Large Scale Image Completion via Co-Modulated Generative Adversarial Networks
Mar 18, 2021
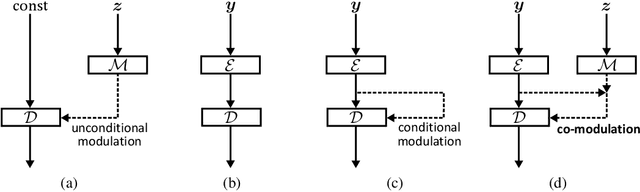
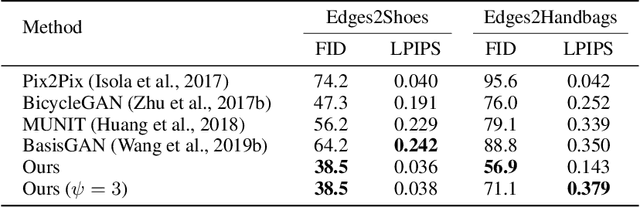
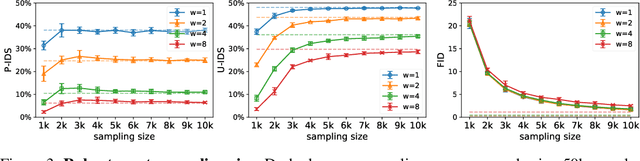
Numerous task-specific variants of conditional generative adversarial networks have been developed for image completion. Yet, a serious limitation remains that all existing algorithms tend to fail when handling large-scale missing regions. To overcome this challenge, we propose a generic new approach that bridges the gap between image-conditional and recent modulated unconditional generative architectures via co-modulation of both conditional and stochastic style representations. Also, due to the lack of good quantitative metrics for image completion, we propose the new Paired/Unpaired Inception Discriminative Score (P-IDS/U-IDS), which robustly measures the perceptual fidelity of inpainted images compared to real images via linear separability in a feature space. Experiments demonstrate superior performance in terms of both quality and diversity over state-of-the-art methods in free-form image completion and easy generalization to image-to-image translation. Code is available at https://github.com/zsyzzsoft/co-mod-gan.
Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution
Aug 13, 2020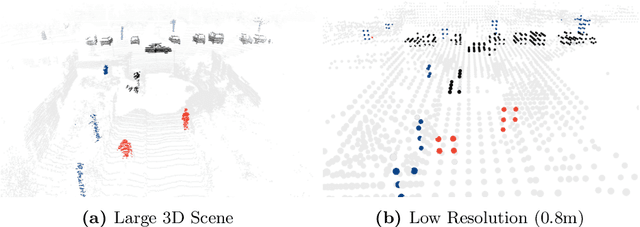
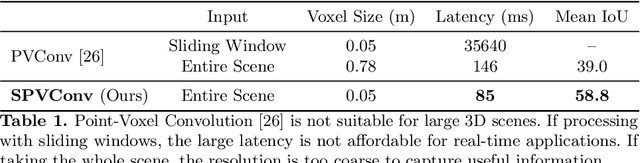
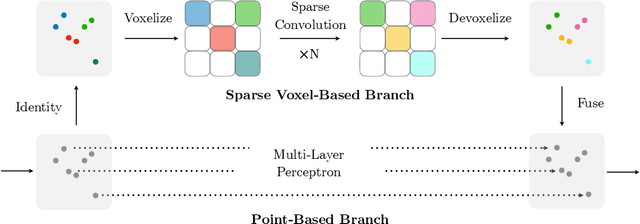
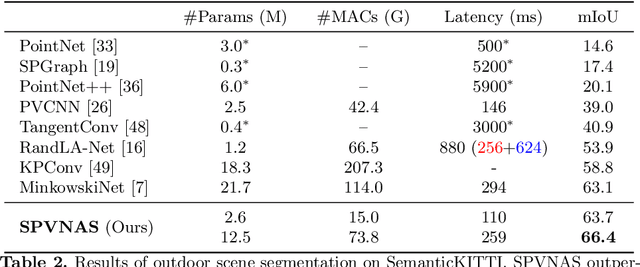
Self-driving cars need to understand 3D scenes efficiently and accurately in order to drive safely. Given the limited hardware resources, existing 3D perception models are not able to recognize small instances (e.g., pedestrians, cyclists) very well due to the low-resolution voxelization and aggressive downsampling. To this end, we propose Sparse Point-Voxel Convolution (SPVConv), a lightweight 3D module that equips the vanilla Sparse Convolution with the high-resolution point-based branch. With negligible overhead, this point-based branch is able to preserve the fine details even from large outdoor scenes. To explore the spectrum of efficient 3D models, we first define a flexible architecture design space based on SPVConv, and we then present 3D Neural Architecture Search (3D-NAS) to search the optimal network architecture over this diverse design space efficiently and effectively. Experimental results validate that the resulting SPVNAS model is fast and accurate: it outperforms the state-of-the-art MinkowskiNet by 3.3%, ranking 1st on the competitive SemanticKITTI leaderboard. It also achieves 8x computation reduction and 3x measured speedup over MinkowskiNet with higher accuracy. Finally, we transfer our method to 3D object detection, and it achieves consistent improvements over the one-stage detection baseline on KITTI.
Differentiable Augmentation for Data-Efficient GAN Training
Jun 18, 2020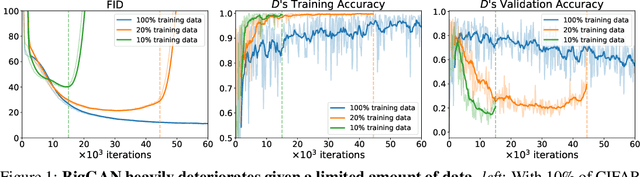

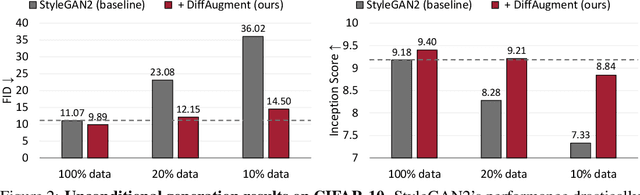

The performance of generative adversarial networks (GANs) heavily deteriorates given a limited amount of training data. This is mainly because the discriminator is memorizing the exact training set. To combat it, we propose Differentiable Augmentation (DiffAugment), a simple method that improves the data efficiency of GANs by imposing various types of differentiable augmentations on both real and fake samples. Previous attempts to directly augment the training data manipulate the distribution of real images, yielding little benefit; DiffAugment enables us to adopt the differentiable augmentation for the generated samples, effectively stabilizes training, and leads to better convergence. Experiments demonstrate consistent gains of our method over a variety of GAN architectures and loss functions for both unconditional and class-conditional generation. With DiffAugment, we achieve a state-of-the-art FID of 6.80 with an IS of 100.8 on ImageNet 128x128. Furthermore, with only 20% training data, we can match the top performance on CIFAR-10 and CIFAR-100. Finally, our method can generate high-fidelity images using only 100 images without pre-training, while being on par with existing transfer learning algorithms. Code is available at https://github.com/mit-han-lab/data-efficient-gans.
MaskFlownet: Asymmetric Feature Matching with Learnable Occlusion Mask
Apr 08, 2020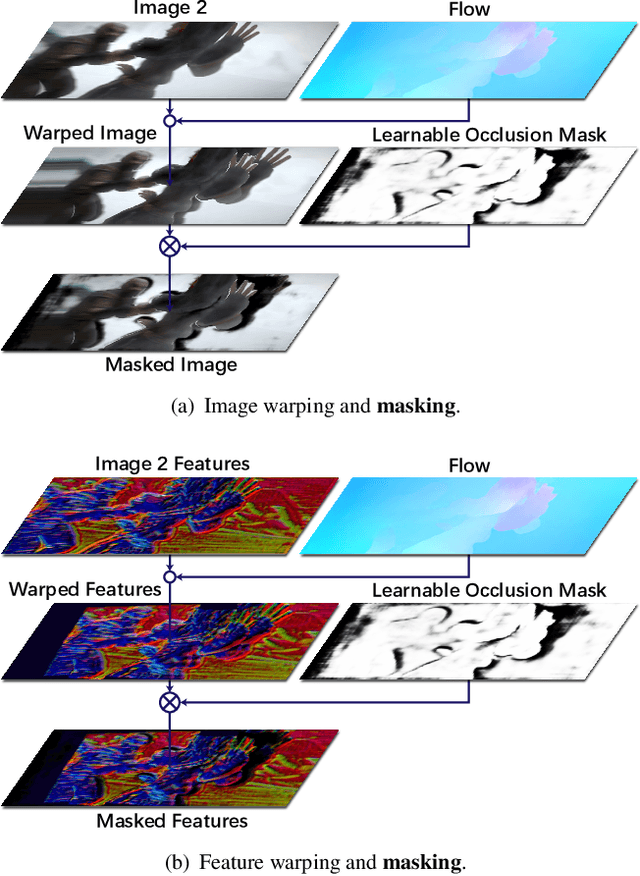
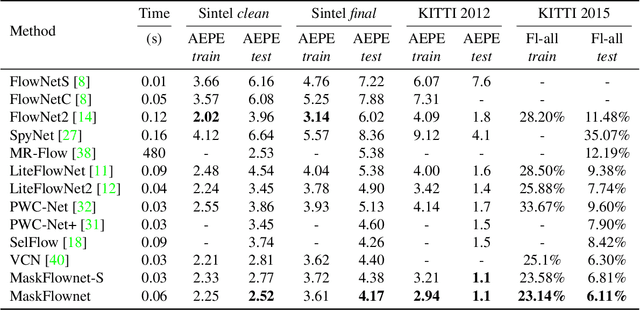
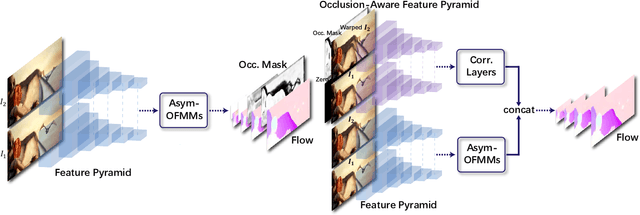
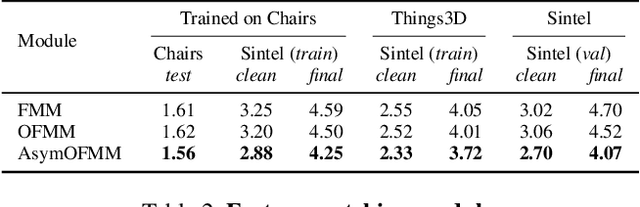
Feature warping is a core technique in optical flow estimation; however, the ambiguity caused by occluded areas during warping is a major problem that remains unsolved. In this paper, we propose an asymmetric occlusion-aware feature matching module, which can learn a rough occlusion mask that filters useless (occluded) areas immediately after feature warping without any explicit supervision. The proposed module can be easily integrated into end-to-end network architectures and enjoys performance gains while introducing negligible computational cost. The learned occlusion mask can be further fed into a subsequent network cascade with dual feature pyramids with which we achieve state-of-the-art performance. At the time of submission, our method, called MaskFlownet, surpasses all published optical flow methods on the MPI Sintel, KITTI 2012 and 2015 benchmarks. Code is available at https://github.com/microsoft/MaskFlownet.
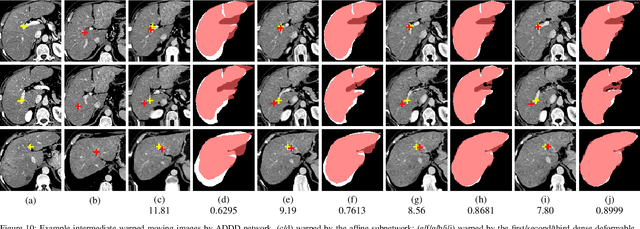
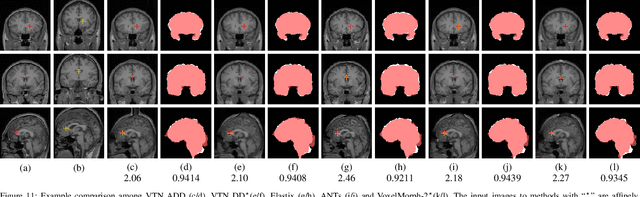
Recursive Cascaded Networks for Unsupervised Medical Image Registration
Jul 29, 2019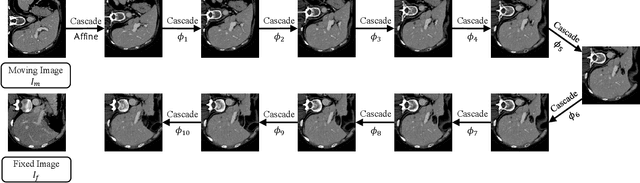
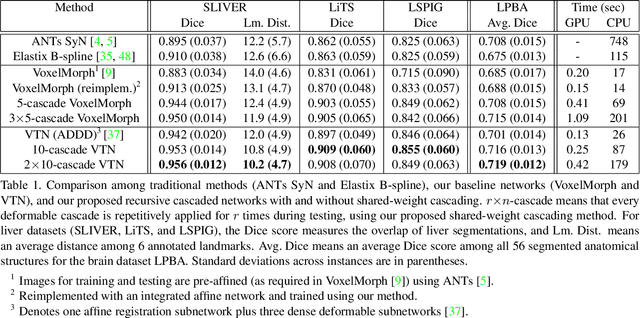
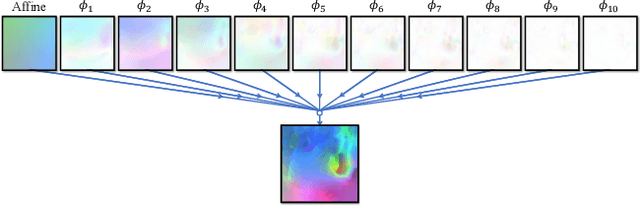
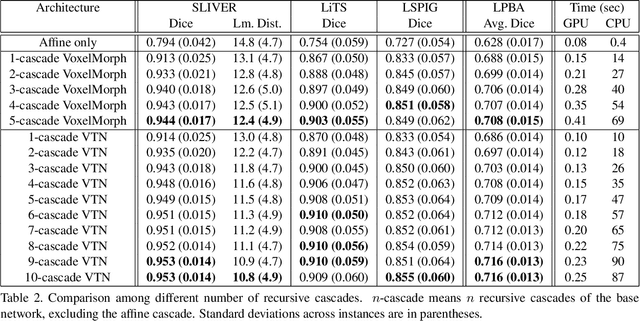
We present recursive cascaded networks, a general architecture that enables learning deep cascades, for deformable image registration. The proposed architecture is simple in design and can be built on any base network. The moving image is warped successively by each cascade and finally aligned to the fixed image; this procedure is recursive in a way that every cascade learns to perform a progressive deformation for the current warped image. The entire system is end-to-end and jointly trained in an unsupervised manner. In addition, enabled by the recursive architecture, one cascade can be iteratively applied for multiple times during testing, which approaches a better fit between each of the image pairs. We evaluate our method on 3D medical images, where deformable registration is most commonly applied. We demonstrate that recursive cascaded networks achieve consistent, significant gains and outperform state-of-the-art methods. The performance reveals an increasing trend as long as more cascades are trained, while the limit is not observed. Our code will be made publicly available.
Unsupervised 3D End-to-End Medical Image Registration with Volume Tweening Network
Feb 13, 2019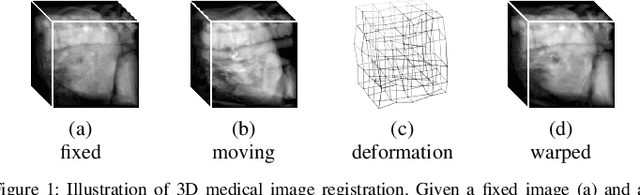
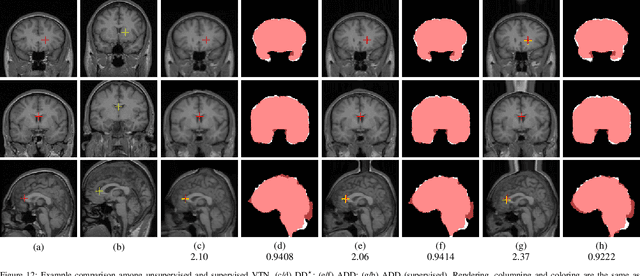
3D medical image registration is of great clinical importance. However, supervised learning methods require a large amount of accurately annotated corresponding control points (or morphing). The ground truth for 3D medical images is very difficult to obtain. Unsupervised learning methods ease the burden of manual annotation by exploiting unlabeled data without supervision. In this paper, we propose a new unsupervised learning method using convolutional neural networks under an end-to-end framework, Volume Tweening Network (VTN), to register 3D medical images. Three technical components ameliorate our unsupervised learning system for 3D end-to-end medical image registration: (1) We cascade the registration subnetworks; (2) We integrate affine registration into our network; and (3) We incorporate an additional invertibility loss into the training process. Experimental results demonstrate that our algorithm is 880x faster (or 3.3x faster without GPU acceleration) than traditional optimization-based methods and achieves state-of-the-art performance in medical image registration.