 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhole Brain Segmentation with Full Volume Neural Network
Oct 29, 2021
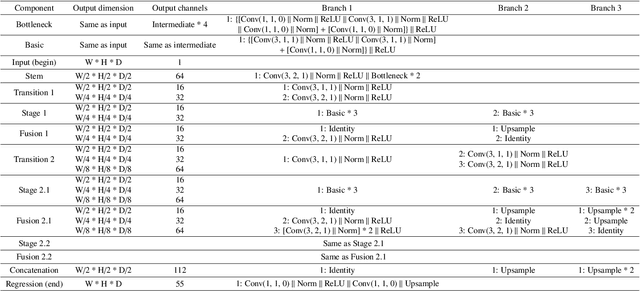
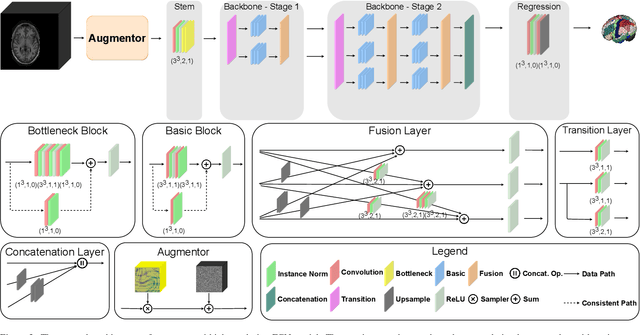
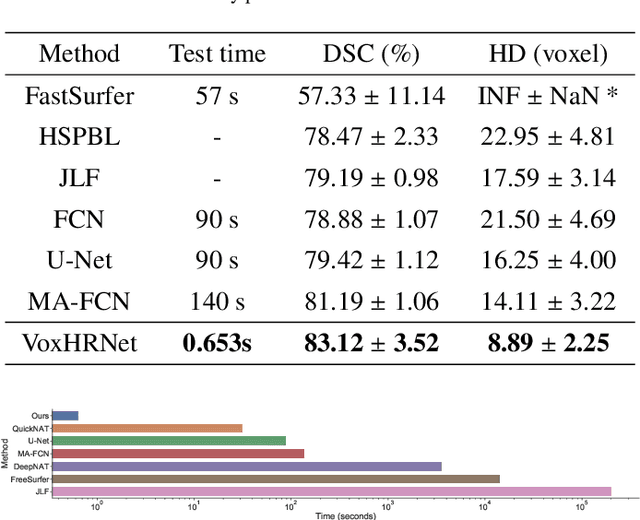
Whole brain segmentation is an important neuroimaging task that segments the whole brain volume into anatomically labeled regions-of-interest. Convolutional neural networks have demonstrated good performance in this task. Existing solutions, usually segment the brain image by classifying the voxels, or labeling the slices or the sub-volumes separately. Their representation learning is based on parts of the whole volume whereas their labeling result is produced by aggregation of partial segmentation. Learning and inference with incomplete information could lead to sub-optimal final segmentation result. To address these issues, we propose to adopt a full volume framework, which feeds the full volume brain image into the segmentation network and directly outputs the segmentation result for the whole brain volume. The framework makes use of complete information in each volume and can be implemented easily. An effective instance in this framework is given subsequently. We adopt the $3$D high-resolution network (HRNet) for learning spatially fine-grained representations and the mixed precision training scheme for memory-efficient training. Extensive experiment results on a publicly available $3$D MRI brain dataset show that our proposed model advances the state-of-the-art methods in terms of segmentation performance. Source code is publicly available at https://github.com/microsoft/VoxHRNet.
* Accepted to CMIG
Large Scale Image Completion via Co-Modulated Generative Adversarial Networks
Mar 18, 2021
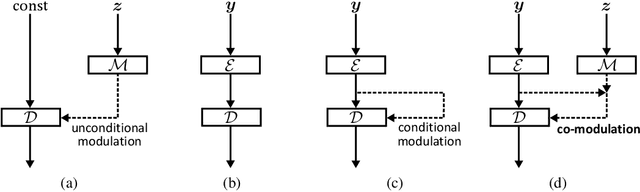
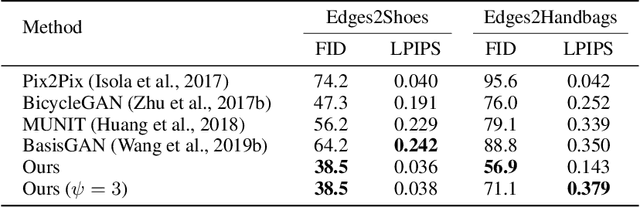
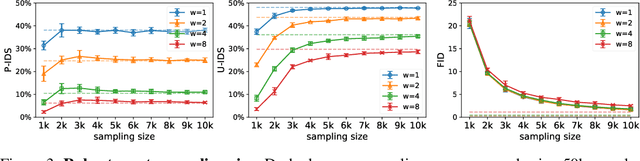
Numerous task-specific variants of conditional generative adversarial networks have been developed for image completion. Yet, a serious limitation remains that all existing algorithms tend to fail when handling large-scale missing regions. To overcome this challenge, we propose a generic new approach that bridges the gap between image-conditional and recent modulated unconditional generative architectures via co-modulation of both conditional and stochastic style representations. Also, due to the lack of good quantitative metrics for image completion, we propose the new Paired/Unpaired Inception Discriminative Score (P-IDS/U-IDS), which robustly measures the perceptual fidelity of inpainted images compared to real images via linear separability in a feature space. Experiments demonstrate superior performance in terms of both quality and diversity over state-of-the-art methods in free-form image completion and easy generalization to image-to-image translation. Code is available at https://github.com/zsyzzsoft/co-mod-gan.
MaskFlownet: Asymmetric Feature Matching with Learnable Occlusion Mask
Apr 08, 2020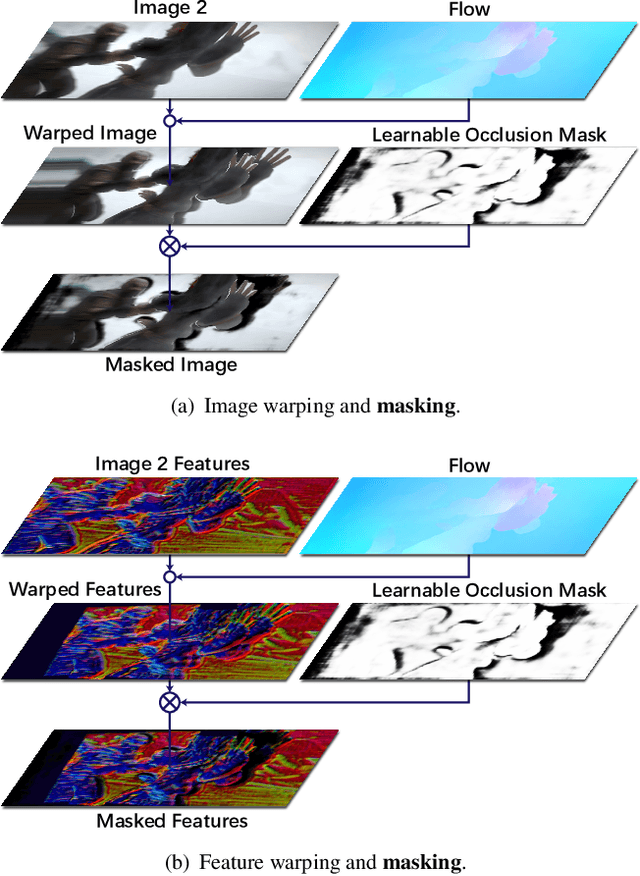
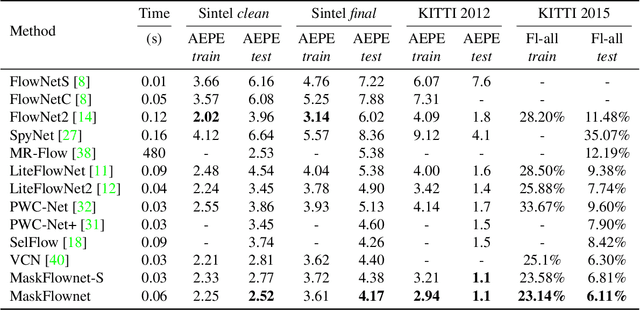
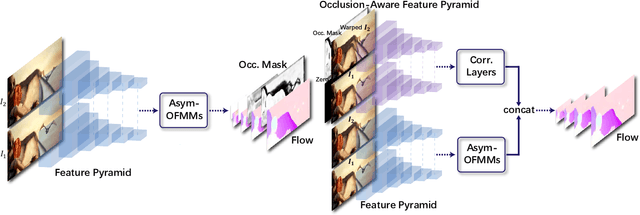
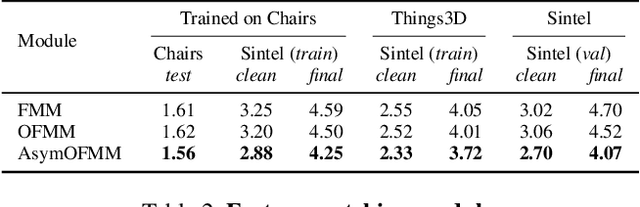
Feature warping is a core technique in optical flow estimation; however, the ambiguity caused by occluded areas during warping is a major problem that remains unsolved. In this paper, we propose an asymmetric occlusion-aware feature matching module, which can learn a rough occlusion mask that filters useless (occluded) areas immediately after feature warping without any explicit supervision. The proposed module can be easily integrated into end-to-end network architectures and enjoys performance gains while introducing negligible computational cost. The learned occlusion mask can be further fed into a subsequent network cascade with dual feature pyramids with which we achieve state-of-the-art performance. At the time of submission, our method, called MaskFlownet, surpasses all published optical flow methods on the MPI Sintel, KITTI 2012 and 2015 benchmarks. Code is available at https://github.com/microsoft/MaskFlownet.