 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivation and analysis of power offset in fiber-longitudinal power profile estimation using pre-FEC hard-decision data
Mar 26, 2025Utilizing the precise reference waveform regenerated by post-forward error correction (FEC) data, the fiber-longitudinal power profile estimation based on the minimum-mean-square-error method (MMSE-PPE) has been validated as an effective tool for absolute power monitoring. However, when post-FEC data is unavailable, it becomes necessary to rely on pre-FEC hard-decision data, which inevitably introduces hard-decision errors. These hard-decision errors will result in a power offset that undermines the accuracy of absolute power monitoring. In this paper, we present the first analytical expression for power offset in MMSE-PPE when using pre-FEC hard-decision data, achieved by introducing a virtual hard-decision nonlinear perturbation term. Based on this analytical expression, we also establish the first nonlinear relationship between the power offset and the symbol error rate (SER) of M-ary quadrature amplitude modulation (M-QAM) formats based on Gaussian assumptions. Verified in a numerical 130-GBaud single-wavelength coherent optical fiber transmission system, the correctness of the analytical expression of power offset has been confirmed with 4-QAM, 16-QAM, and 64-QAM formats under different SER situations. Furthermore, the nonlinear relationship between the power offset and SER of $M$-QAM formats has also been thoroughly validated under both linear scale (measured in mW) and logarithmic scale (measured in dB). These theoretical insights offer significant contributions to the design of potential power offset mitigation strategies in MMSE-PPE, thereby enhancing its real-time application.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Unsupervised 3D End-to-End Medical Image Registration with Volume Tweening Network
Feb 13, 2019
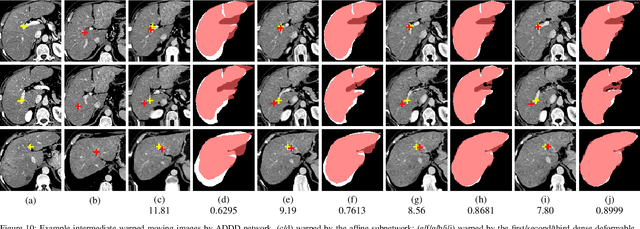
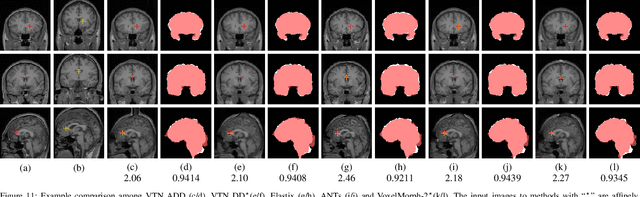
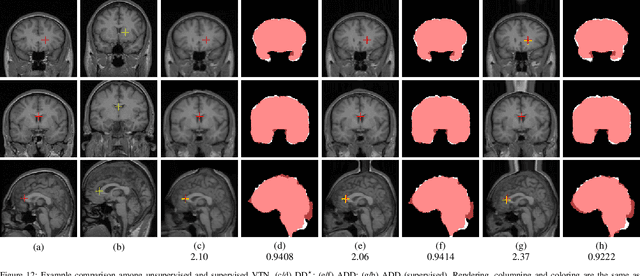
3D medical image registration is of great clinical importance. However, supervised learning methods require a large amount of accurately annotated corresponding control points (or morphing). The ground truth for 3D medical images is very difficult to obtain. Unsupervised learning methods ease the burden of manual annotation by exploiting unlabeled data without supervision. In this paper, we propose a new unsupervised learning method using convolutional neural networks under an end-to-end framework, Volume Tweening Network (VTN), to register 3D medical images. Three technical components ameliorate our unsupervised learning system for 3D end-to-end medical image registration: (1) We cascade the registration subnetworks; (2) We integrate affine registration into our network; and (3) We incorporate an additional invertibility loss into the training process. Experimental results demonstrate that our algorithm is 880x faster (or 3.3x faster without GPU acceleration) than traditional optimization-based methods and achieves state-of-the-art performance in medical image registration.