 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivation and analysis of power offset in fiber-longitudinal power profile estimation using pre-FEC hard-decision data
Mar 26, 2025Utilizing the precise reference waveform regenerated by post-forward error correction (FEC) data, the fiber-longitudinal power profile estimation based on the minimum-mean-square-error method (MMSE-PPE) has been validated as an effective tool for absolute power monitoring. However, when post-FEC data is unavailable, it becomes necessary to rely on pre-FEC hard-decision data, which inevitably introduces hard-decision errors. These hard-decision errors will result in a power offset that undermines the accuracy of absolute power monitoring. In this paper, we present the first analytical expression for power offset in MMSE-PPE when using pre-FEC hard-decision data, achieved by introducing a virtual hard-decision nonlinear perturbation term. Based on this analytical expression, we also establish the first nonlinear relationship between the power offset and the symbol error rate (SER) of M-ary quadrature amplitude modulation (M-QAM) formats based on Gaussian assumptions. Verified in a numerical 130-GBaud single-wavelength coherent optical fiber transmission system, the correctness of the analytical expression of power offset has been confirmed with 4-QAM, 16-QAM, and 64-QAM formats under different SER situations. Furthermore, the nonlinear relationship between the power offset and SER of $M$-QAM formats has also been thoroughly validated under both linear scale (measured in mW) and logarithmic scale (measured in dB). These theoretical insights offer significant contributions to the design of potential power offset mitigation strategies in MMSE-PPE, thereby enhancing its real-time application.
An Augmented Transformer Architecture for Natural Language Generation Tasks
Oct 30, 2019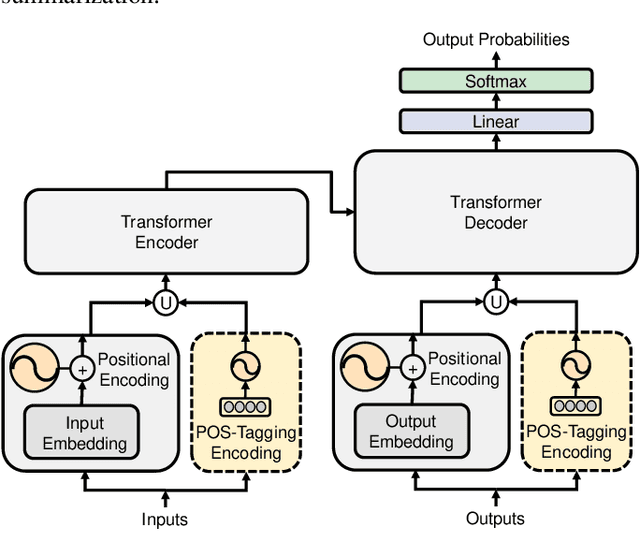
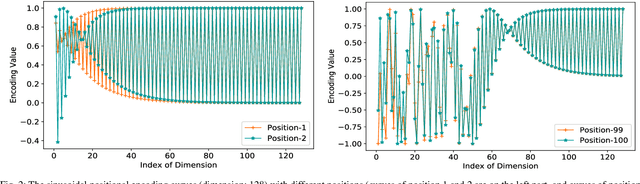
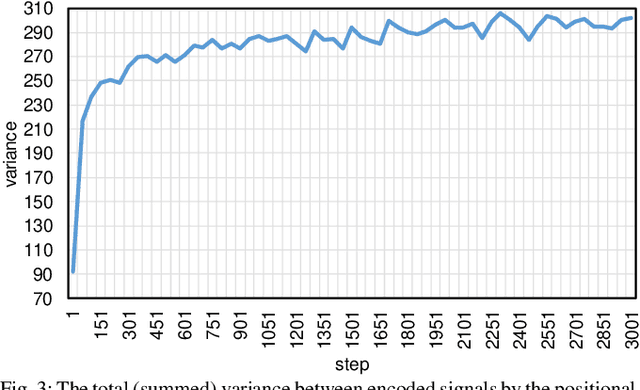
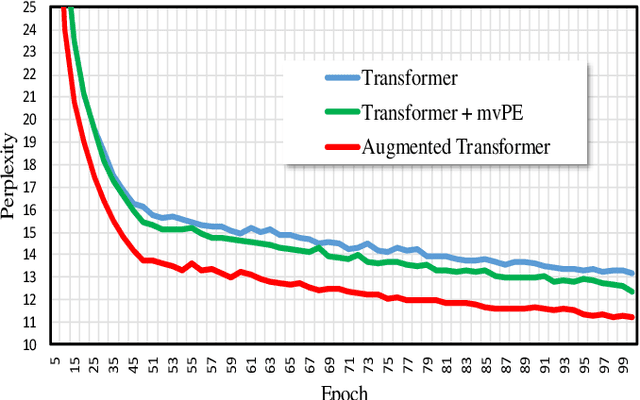
The Transformer based neural networks have been showing significant advantages on most evaluations of various natural language processing and other sequence-to-sequence tasks due to its inherent architecture based superiorities. Although the main architecture of the Transformer has been continuously being explored, little attention was paid to the positional encoding module. In this paper, we enhance the sinusoidal positional encoding algorithm by maximizing the variances between encoded consecutive positions to obtain additional promotion. Furthermore, we propose an augmented Transformer architecture encoded with additional linguistic knowledge, such as the Part-of-Speech (POS) tagging, to boost the performance on some natural language generation tasks, e.g., the automatic translation and summarization tasks. Experiments show that the proposed architecture attains constantly superior results compared to the vanilla Transformer.