 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Inception Boosted U-Net Neural Network for Routability Prediction
Feb 07, 2024



As the modern CPU, GPU, and NPU chip design complexity and transistor counts keep increasing, and with the relentless shrinking of semiconductor technology nodes to nearly 1 nanometer, the placement and routing have gradually become the two most pivotal processes in modern very-large-scale-integrated (VLSI) circuit back-end design. How to evaluate routability efficiently and accurately in advance (at the placement and global routing stages) has grown into a crucial research area in the field of artificial intelligence (AI) assisted electronic design automation (EDA). In this paper, we propose a novel U-Net variant model boosted by an Inception embedded module to predict Routing Congestion (RC) and Design Rule Checking (DRC) hotspots. Experimental results on the recently published CircuitNet dataset benchmark show that our proposed method achieves up to 5% (RC) and 20% (DRC) rate reduction in terms of Avg-NRMSE (Average Normalized Root Mean Square Error) compared to the classic architecture. Furthermore, our approach consistently outperforms the prior model on the SSIM (Structural Similarity Index Measure) metric.
An Augmented Transformer Architecture for Natural Language Generation Tasks
Oct 30, 2019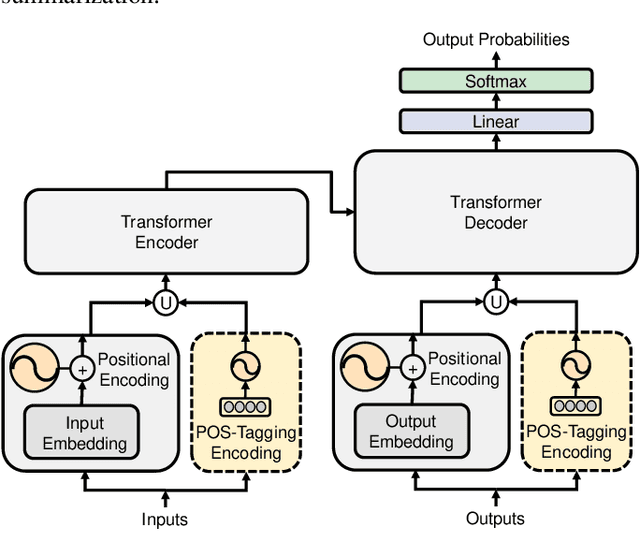
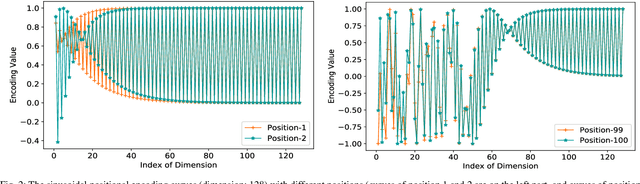
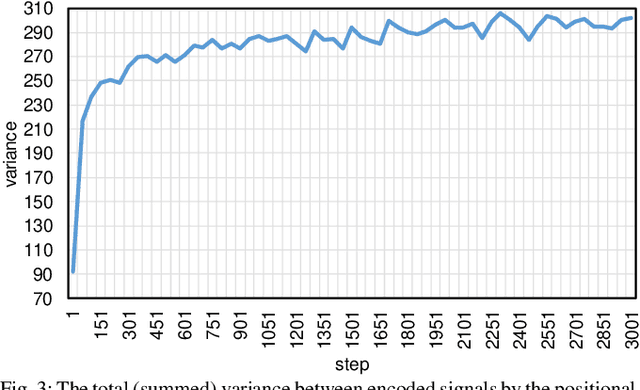
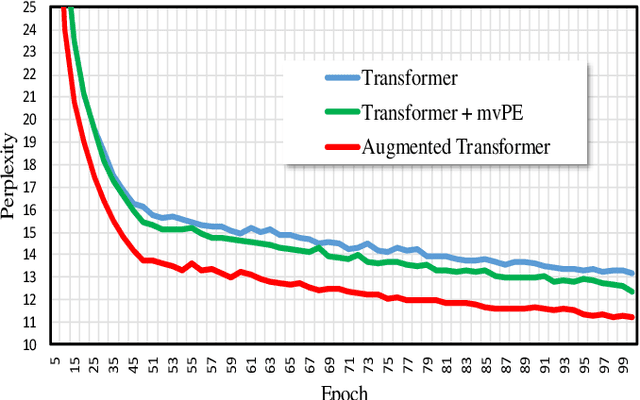
The Transformer based neural networks have been showing significant advantages on most evaluations of various natural language processing and other sequence-to-sequence tasks due to its inherent architecture based superiorities. Although the main architecture of the Transformer has been continuously being explored, little attention was paid to the positional encoding module. In this paper, we enhance the sinusoidal positional encoding algorithm by maximizing the variances between encoded consecutive positions to obtain additional promotion. Furthermore, we propose an augmented Transformer architecture encoded with additional linguistic knowledge, such as the Part-of-Speech (POS) tagging, to boost the performance on some natural language generation tasks, e.g., the automatic translation and summarization tasks. Experiments show that the proposed architecture attains constantly superior results compared to the vanilla Transformer.
Image Super-resolution via Feature-augmented Random Forest
Dec 14, 2017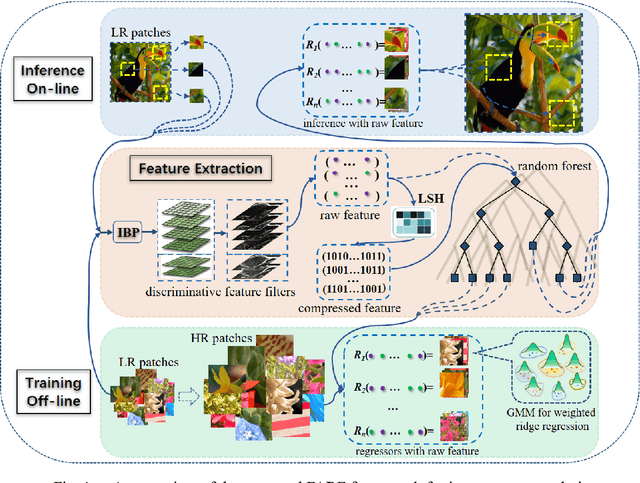
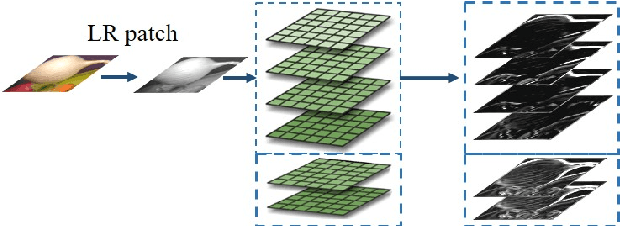

Recent random-forest (RF)-based image super-resolution approaches inherit some properties from dictionary-learning-based algorithms, but the effectiveness of the properties in RF is overlooked in the literature. In this paper, we present a novel feature-augmented random forest (FARF) for image super-resolution, where the conventional gradient-based features are augmented with gradient magnitudes and different feature recipes are formulated on different stages in an RF. The advantages of our method are that, firstly, the dictionary-learning-based features are enhanced by adding gradient magnitudes, based on the observation that the non-linear gradient magnitude are with highly discriminative property. Secondly, generalized locality-sensitive hashing (LSH) is used to replace principal component analysis (PCA) for feature dimensionality reduction and original high-dimensional features are employed, instead of the compressed ones, for the leaf-nodes' regressors, since regressors can benefit from higher dimensional features. This original-compressed coupled feature sets scheme unifies the unsupervised LSH evaluation on both image super-resolution and content-based image retrieval (CBIR). Finally, we present a generalized weighted ridge regression (GWRR) model for the leaf-nodes' regressors. Experiment results on several public benchmark datasets show that our FARF method can achieve an average gain of about 0.3 dB, compared to traditional RF-based methods. Furthermore, a fine-tuned FARF model can compare to or (in many cases) outperform some recent stateof-the-art deep-learning-based algorithms.
Joint Maximum Purity Forest with Application to Image Super-Resolution
Aug 30, 2017In this paper, we propose a novel random-forest scheme, namely Joint Maximum Purity Forest (JMPF), for classification, clustering, and regression tasks. In the JMPF scheme, the original feature space is transformed into a compactly pre-clustered feature space, via a trained rotation matrix. The rotation matrix is obtained through an iterative quantization process, where the input data belonging to different classes are clustered to the respective vertices of the new feature space with maximum purity. In the new feature space, orthogonal hyperplanes, which are employed at the split-nodes of decision trees in random forests, can tackle the clustering problems effectively. We evaluated our proposed method on public benchmark datasets for regression and classification tasks, and experiments showed that JMPF remarkably outperforms other state-of-the-art random-forest-based approaches. Furthermore, we applied JMPF to image super-resolution, because the transformed, compact features are more discriminative to the clustering-regression scheme. Experiment results on several public benchmark datasets also showed that the JMPF-based image super-resolution scheme is consistently superior to recent state-of-the-art image super-resolution algorithms.
Cascaded Face Alignment via Intimacy Definition Feature
Apr 12, 2017In this paper, we present a random-forest based fast cascaded regression model for face alignment, via a novel local feature. Our proposed local lightweight feature, namely intimacy definition feature (IDF), is more discriminative than landmark pose-indexed feature, more efficient than histogram of oriented gradients (HOG) feature and scale-invariant feature transform (SIFT) feature, and more compact than the local binary feature (LBF). Experimental results show that our approach achieves state-of-the-art performance when tested on the most challenging datasets. Compared with an LBF-based algorithm, our method can achieve about two times the speed-up and more than 20% improvement, in terms of alignment accuracy measurement, and save an order of magnitude of memory requirement.
Efficient Likelihood Bayesian Constrained Local Model
Nov 30, 2016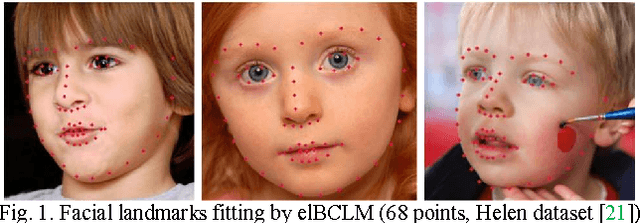
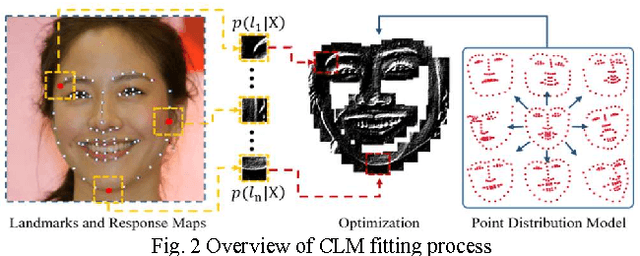
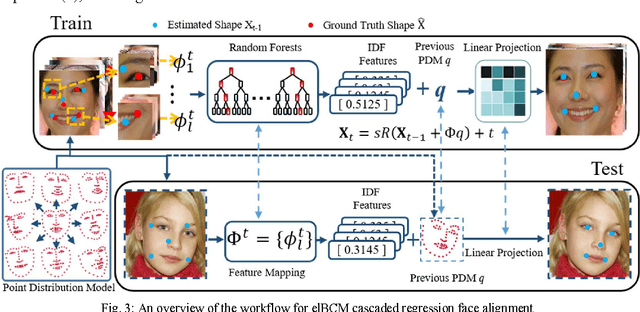
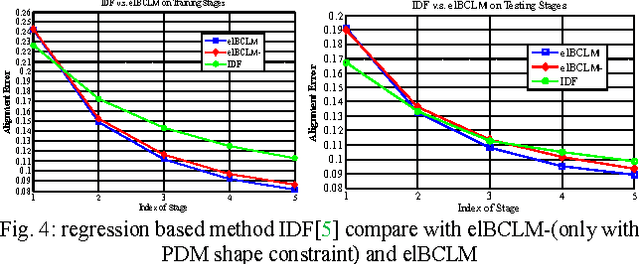
The constrained local model (CLM) proposes a paradigm that the locations of a set of local landmark detectors are constrained to lie in a subspace, spanned by a shape point distribution model (PDM). Fitting the model to an object involves two steps. A response map, which represents the likelihood of the location of a landmark, is first computed for each landmark using local-texture detectors. Then, an optimal PDM is determined by jointly maximizing all the response maps simultaneously, with a global shape constraint. This global optimization can be considered as a Bayesian inference problem, where the posterior distribution of the shape parameters, as well as the pose parameters, can be inferred using maximum a posteriori (MAP). In this paper, we present a cascaded face-alignment approach, which employs random-forest regressors to estimate the positions of each landmark, as a likelihood term, efficiently in the CLM model. Interpretation from CLM framework, this algorithm is named as an efficient likelihood Bayesian constrained local model (elBCLM). Furthermore, in each stage of the regressors, the PDM non-rigid parameters of previous stage can work as shape clues for training each stage regressors. Experimental results on benchmarks show our approach achieve about 3 to 5 times speed-up compared with CLM models and improve around 10% on fitting quality compare with the same setting regression models.