 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Inception Boosted U-Net Neural Network for Routability Prediction
Feb 07, 2024



As the modern CPU, GPU, and NPU chip design complexity and transistor counts keep increasing, and with the relentless shrinking of semiconductor technology nodes to nearly 1 nanometer, the placement and routing have gradually become the two most pivotal processes in modern very-large-scale-integrated (VLSI) circuit back-end design. How to evaluate routability efficiently and accurately in advance (at the placement and global routing stages) has grown into a crucial research area in the field of artificial intelligence (AI) assisted electronic design automation (EDA). In this paper, we propose a novel U-Net variant model boosted by an Inception embedded module to predict Routing Congestion (RC) and Design Rule Checking (DRC) hotspots. Experimental results on the recently published CircuitNet dataset benchmark show that our proposed method achieves up to 5% (RC) and 20% (DRC) rate reduction in terms of Avg-NRMSE (Average Normalized Root Mean Square Error) compared to the classic architecture. Furthermore, our approach consistently outperforms the prior model on the SSIM (Structural Similarity Index Measure) metric.
Distributed Swarm Learning for Internet of Things at the Edge: Where Artificial Intelligence Meets Biological Intelligence
Oct 29, 2022With the proliferation of versatile Internet of Things (IoT) services, smart IoT devices are increasingly deployed at the edge of wireless networks to perform collaborative machine learning tasks using locally collected data, giving rise to the edge learning paradigm. Due to device restrictions and resource constraints, edge learning among massive IoT devices faces major technical challenges caused by the communication bottleneck, data and device heterogeneity, non-convex optimization, privacy and security concerns, and dynamic environments. To overcome these challenges, this article studies a new framework of distributed swarm learning (DSL) through a holistic integration of artificial intelligence and biological swarm intelligence. Leveraging efficient and robust signal processing and communication techniques, DSL contributes to novel tools for learning and optimization tailored for real-time operations of large-scale IoT in edge wireless environments, which will benefit a wide range of edge IoT applications.
CB-DSL: Communication-efficient and Byzantine-robust Distributed Swarm Learning on Non-i.i.d. Data
Aug 10, 2022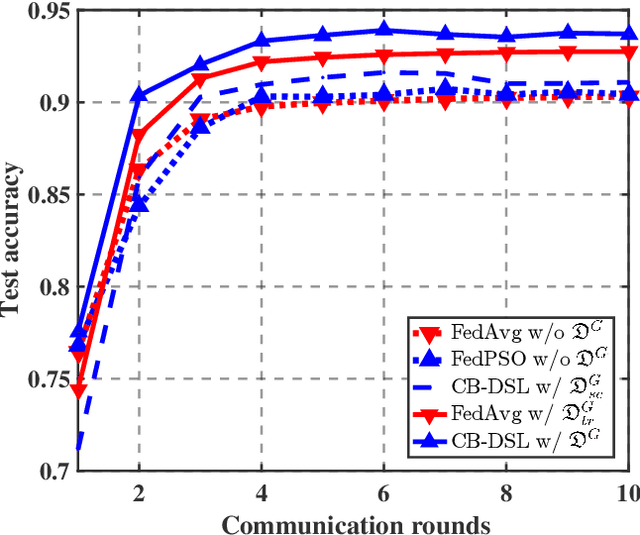
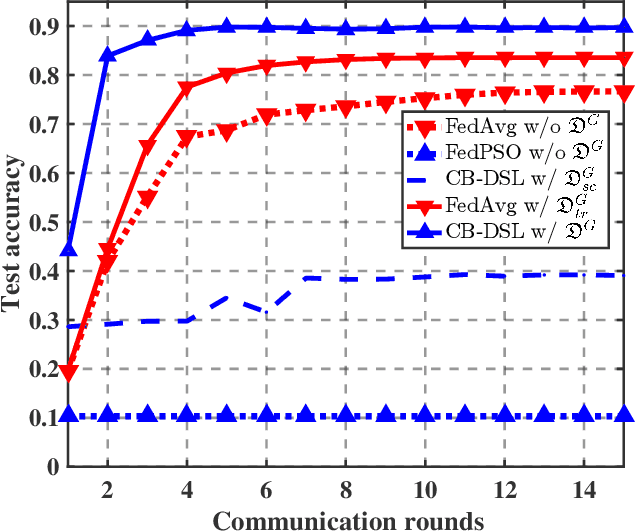
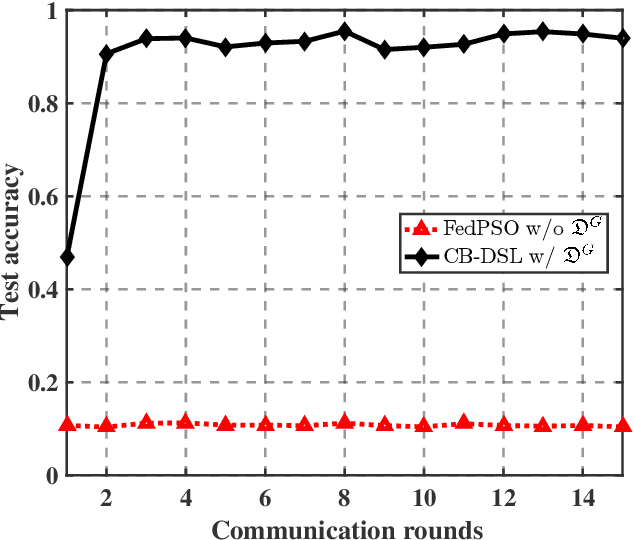
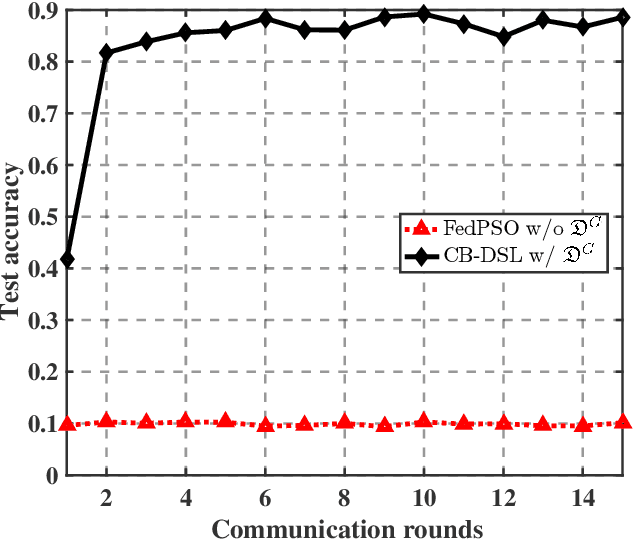
The valuable data collected by IoT devices in edge networks together with the resurgence of ML stimulate the latest trend of edge AI. However, recent FL methods face major challenges including communication bottleneck, data heterogeneity and security concerns in edge IoT scenarios, especially when being adopted for distributed learning among massive IoT devices equipped with limited data and transmission resources. Meanwhile, the swarm nature of IoT systems is overlooked by most existing literature, which calls for new designs of distributed learning algorithms. Inspired by the success of biological intelligence (BI) of gregarious organisms, we propose a novel edge learning approach for swarm IoT, called communication-efficient and Byzantine-robust distributed swarm learning (CB-DSL), through a holistic integration of AI-enabled stochastic gradient descent and BI-enabled particle swarm optimization. To deal with non-i.i.d. data issues and Byzantine attacks, global data samples are introduced in CB-DSL and shared among IoT workers, which not only alleviates the local data heterogeneity effectively but also enables to fully utilize the exploration-exploitation mechanism of swarm intelligence. Further, we provide convergence analysis to theoretically demonstrate that the proposed CB-DSL is superior to the standard FL with better convergence behavior. In addition, to measure the effectiveness of the introduction of the globally shared dataset, we also conduct model divergence analysis by evaluating the distance between the data distribution at local IoT devices and the population distribution for the whole datasets. Numerical results verify that the proposed CB-DSL outperforms the existing benchmarks in terms of faster convergence speed, higher convergent accuracy, lower communication cost, and better robustness against non-i.i.d. data and Byzantine attacks.
BEV-SGD: Best Effort Voting SGD for Analog Aggregation Based Federated Learning against Byzantine Attackers
Oct 18, 2021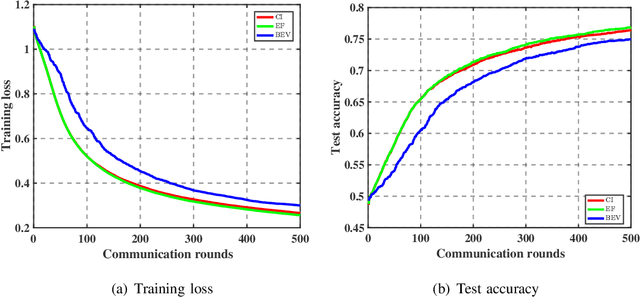
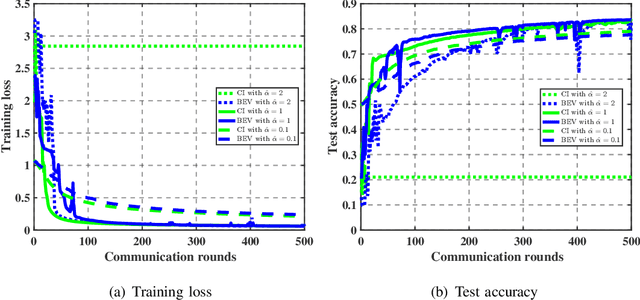
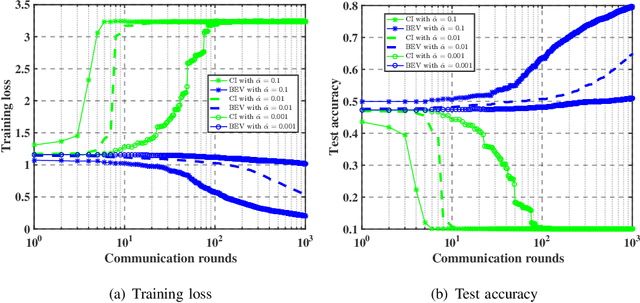
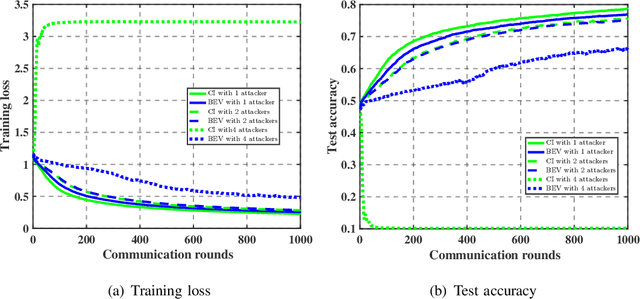
As a promising distributed learning technology, analog aggregation based federated learning over the air (FLOA) provides high communication efficiency and privacy provisioning in edge computing paradigm. When all edge devices (workers) simultaneously upload their local updates to the parameter server (PS) through the commonly shared time-frequency resources, the PS can only obtain the averaged update rather than the individual local ones. As a result, such a concurrent transmission and aggregation scheme reduces the latency and costs of communication but makes FLOA vulnerable to Byzantine attacks which then degrade FLOA performance. For the design of Byzantine-resilient FLOA, this paper starts from analyzing the channel inversion (CI) power control mechanism that is widely used in existing FLOA literature. Our theoretical analysis indicates that although CI can achieve good learning performance in the non-attacking scenarios, it fails to work well with limited defensive capability to Byzantine attacks. Then, we propose a novel defending scheme called best effort voting (BEV) power control policy integrated with stochastic gradient descent (SGD). Our BEV-SGD improves the robustness of FLOA to Byzantine attacks, by allowing all the workers to send their local updates at their maximum transmit power. Under the strongest-attacking circumstance, we derive the expected convergence rates of FLOA with CI and BEV power control policies, respectively. The rate comparison reveals that our BEV-SGD outperforms its counterpart with CI in terms of better convergence behavior, which is verified by experimental simulations.
Joint Optimization of Communications and Federated Learning Over the Air
Apr 08, 2021



Federated learning (FL) is an attractive paradigm for making use of rich distributed data while protecting data privacy. Nonetheless, nonideal communication links and limited transmission resources have become the bottleneck of the implementation of fast and accurate FL. In this paper, we study joint optimization of communications and FL based on analog aggregation transmission in realistic wireless networks. We first derive a closed-form expression for the expected convergence rate of FL over the air, which theoretically quantifies the impact of analog aggregation on FL. Based on the analytical result, we develop a joint optimization model for accurate FL implementation, which allows a parameter server to select a subset of workers and determine an appropriate power scaling factor. Since the practical setting of FL over the air encounters unobservable parameters, we reformulate the joint optimization of worker selection and power allocation using controlled approximation. Finally, we efficiently solve the resulting mixed-integer programming problem via a simple yet optimal finite-set search method by reducing the search space. Simulation results show that the proposed solutions developed for realistic wireless analog channels outperform a benchmark method, and achieve comparable performance of the ideal case where FL is implemented over noise-free wireless channels.
1-Bit Compressive Sensing for Efficient Federated Learning Over the Air
Mar 30, 2021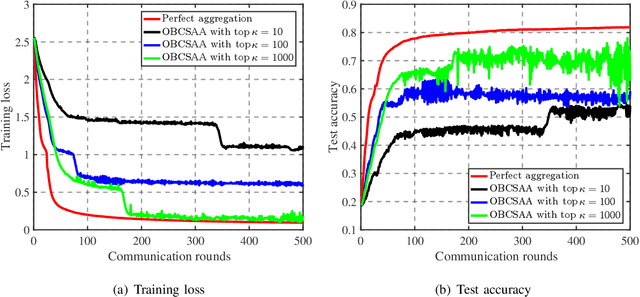
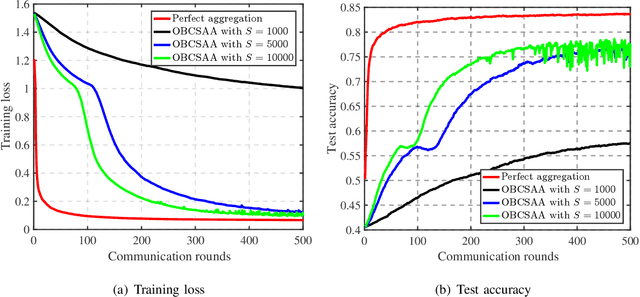
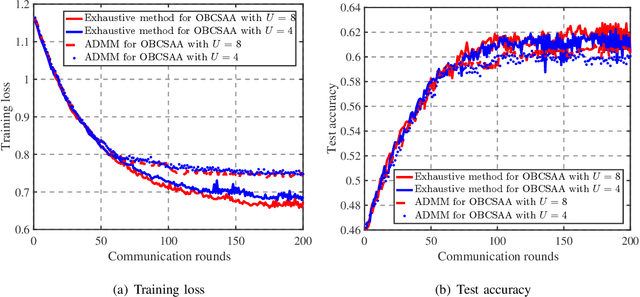

For distributed learning among collaborative users, this paper develops and analyzes a communication-efficient scheme for federated learning (FL) over the air, which incorporates 1-bit compressive sensing (CS) into analog aggregation transmissions. To facilitate design parameter optimization, we theoretically analyze the efficacy of the proposed scheme by deriving a closed-form expression for the expected convergence rate of the FL over the air. Our theoretical results reveal the tradeoff between convergence performance and communication efficiency as a result of the aggregation errors caused by sparsification, dimension reduction, quantization, signal reconstruction and noise. Then, we formulate 1-bit CS based FL over the air as a joint optimization problem to mitigate the impact of these aggregation errors through joint optimal design of worker scheduling and power scaling policy. An enumeration-based method is proposed to solve this non-convex problem, which is optimal but becomes computationally infeasible as the number of devices increases. For scalable computing, we resort to the alternating direction method of multipliers (ADMM) technique to develop an efficient implementation that is suitable for large-scale networks. Simulation results show that our proposed 1-bit CS based FL over the air achieves comparable performance to the ideal case where conventional FL without compression and quantification is applied over error-free aggregation, at much reduced communication overhead and transmission latency.