 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero and Few-shot Semantic Parsing with Ambiguous Inputs
Jun 01, 2023



Despite the ubiquity of ambiguity in natural language, it is often ignored or deliberately removed in semantic parsing tasks, which generally assume that a given surface form has only one correct logical form. We attempt to address this shortcoming by introducing AmP, a framework, dataset, and challenge for parsing with linguistic ambiguity. We define templates and generate data for five well-documented linguistic ambiguities. Using AmP, we investigate how several few-shot semantic parsing systems handle ambiguity, introducing three new metrics. We find that large pre-trained models perform poorly at capturing the distribution of possible meanings without deliberate instruction. However, models are able to capture distribution well when ambiguity is attested in their inputs. These results motivate a call for ambiguity to be explicitly included in semantic parsing, and promotes considering the distribution of possible outputs when evaluating semantic parsing systems.
LOME: Large Ontology Multilingual Extraction
Jan 28, 2021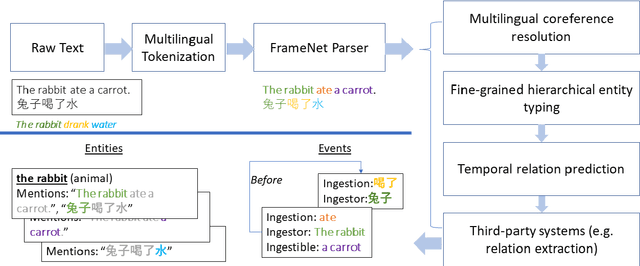
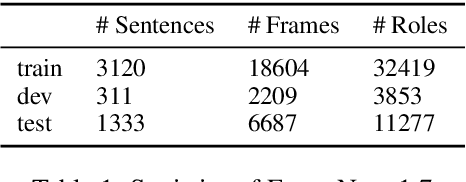
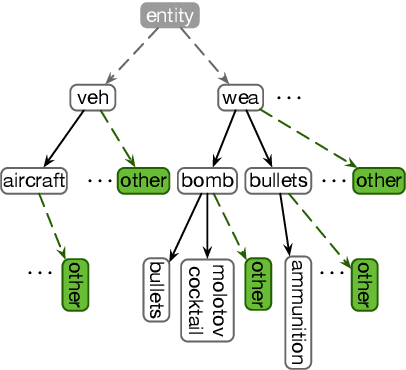
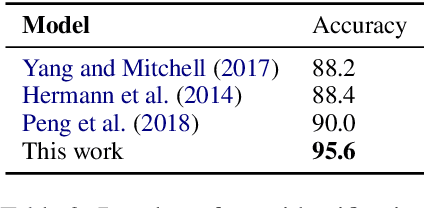
We present LOME, a system for performing multilingual information extraction. Given a text document as input, our core system identifies spans of textual entity and event mentions with a FrameNet (Baker et al., 1998) parser. It subsequently performs coreference resolution, fine-grained entity typing, and temporal relation prediction between events. By doing so, the system constructs an event and entity focused knowledge graph. We can further apply third-party modules for other types of annotation, like relation extraction. Our (multilingual) first-party modules either outperform or are competitive with the (monolingual) state-of-the-art. We achieve this through the use of multilingual encoders like XLM-R (Conneau et al., 2020) and leveraging multilingual training data. LOME is available as a Docker container on Docker Hub. In addition, a lightweight version of the system is accessible as a web demo.
Frequency, Acceptability, and Selection: A case study of clause-embedding
Apr 08, 2020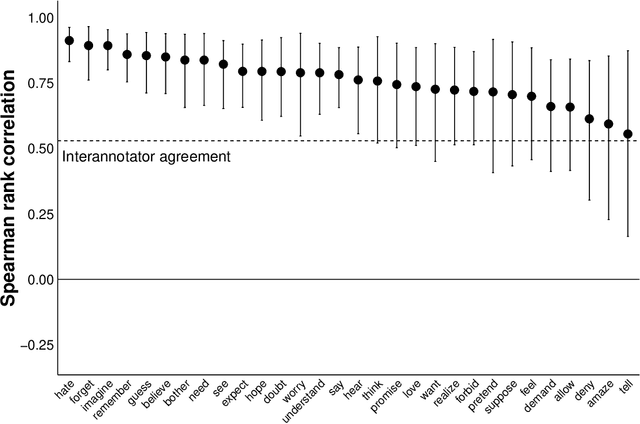
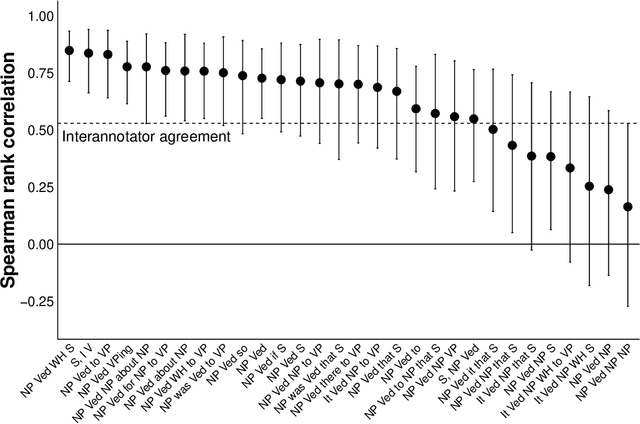


We investigate the relationship between the frequency with which verbs are found in particular subcategorization frames and the acceptability of those verbs in those frames, focusing in particular on subordinate clause-taking verbs, such as "think", "want", and "tell". We show that verbs' subcategorization frame frequency distributions are poor predictors of their acceptability in those frames---explaining, at best, less than 1/3 of the total information about acceptability across the lexicon---and, further, that common matrix factorization techniques used to model the acquisition of verbs' acceptability in subcategorization frames fare only marginally better. All data and code are available at http://megaattitude.io.
Multi-Sentence Argument Linking
Nov 09, 2019
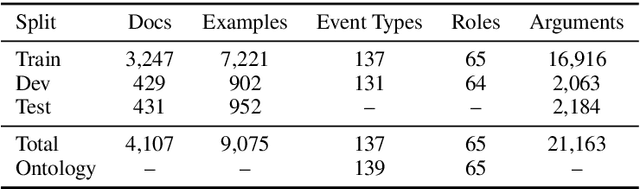
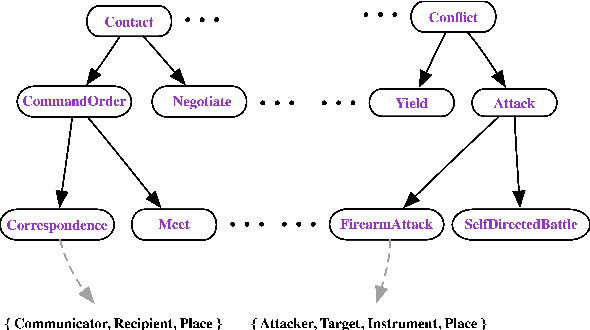
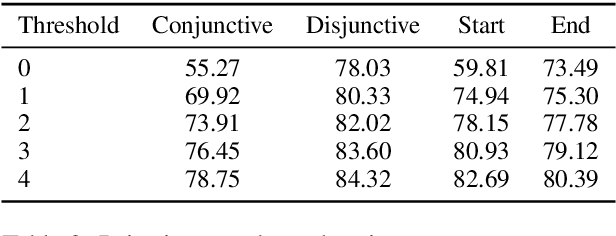
We introduce a dataset with annotated Roles Across Multiple Sentences (RAMS), consisting of over 9,000 annotated events. This enables the development of a novel span-based labeling framework that operates at the document level, which connects related ideas in sentence-level semantic role labeling and coreference resolution. We achieve 68.1 F1 on RAMS when given argument span boundaries and 73.2 F1 when also given gold event types. We additionally illustrate the applicability of the approach to the slot filling task in the Gun Violence Database.
The Universal Decompositional Semantics Dataset and Decomp Toolkit
Sep 30, 2019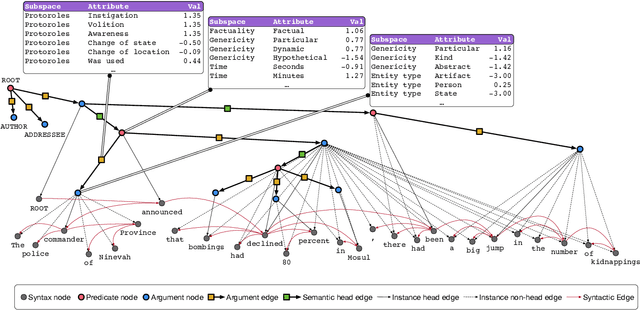
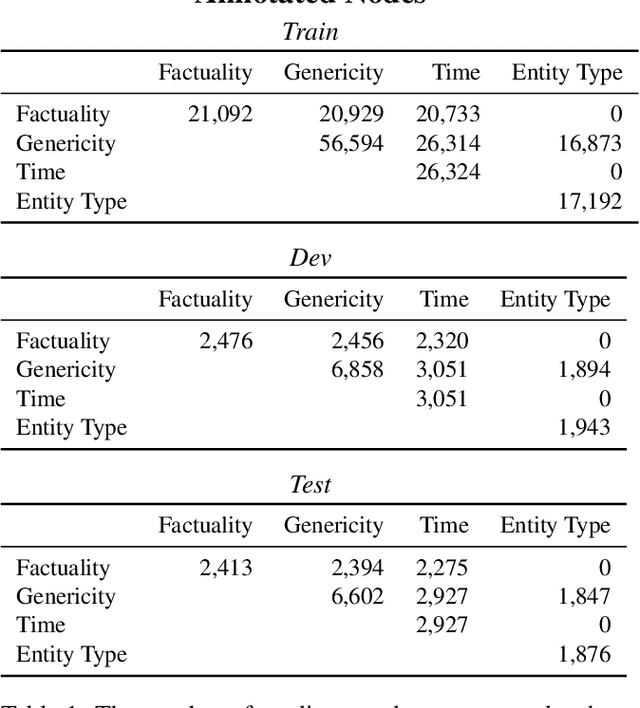
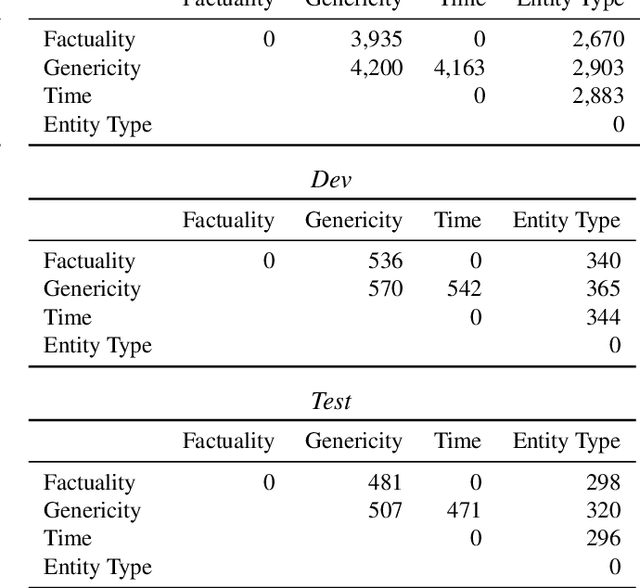

We present the Universal Decompositional Semantics (UDS) dataset (v1.0), which is bundled with the Decomp toolkit (v0.1). UDS1.0 unifies five high-quality, decompositional semantics-aligned annotation sets within a single semantic graph specification---with graph structures defined by the predicative patterns produced by the PredPatt tool and real-valued node and edge attributes constructed using sophisticated normalization procedures. The Decomp toolkit provides a suite of Python 3 tools for querying UDS graphs using SPARQL. Both UDS1.0 and Decomp0.1 are publicly available at http://decomp.io.
Predicting Argumenthood of English Preposition Phrases
Sep 24, 2018


Distinguishing between core and non-core dependents (i.e., arguments and adjuncts) of a verb is a longstanding, nontrivial problem. In natural language processing, argumenthood information is important in tasks such as semantic role labeling (SRL) and preposition phrase (PP) attachment disambiguation. In theoretical linguistics, many diagnostic tests for argumenthood exist but they often yield conflicting and potentially gradient results. This is especially the case for syntactically oblique items such as PPs. We propose two PP argumenthood prediction tasks branching from these two motivations: (1) binary argument/adjunct classification of PPs in VerbNet, and (2) gradient argumenthood prediction using human judgments as gold standard, and report results from prediction models that use pretrained word embeddings and other linguistically informed features. Our best results on each task are (1) $acc.=0.955$, $F_1=0.954$ (ELMo+BiLSTM) and (2) Pearson's $r=0.624$ (word2vec+MLP). Furthermore, we demonstrate the utility of argumenthood prediction in improving sentence representations via performance gains on SRL when a sentence encoder is pretrained with our tasks.
Lexicosyntactic Inference in Neural Models
Aug 19, 2018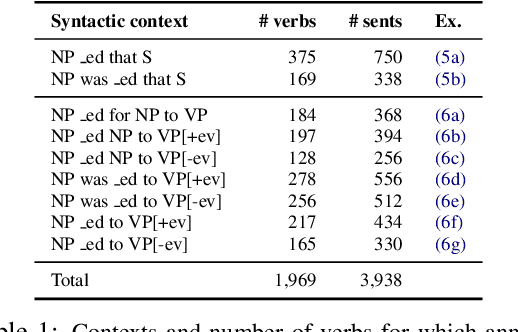
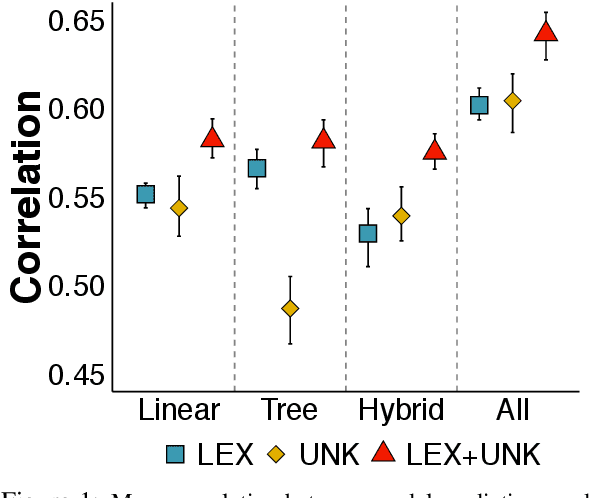
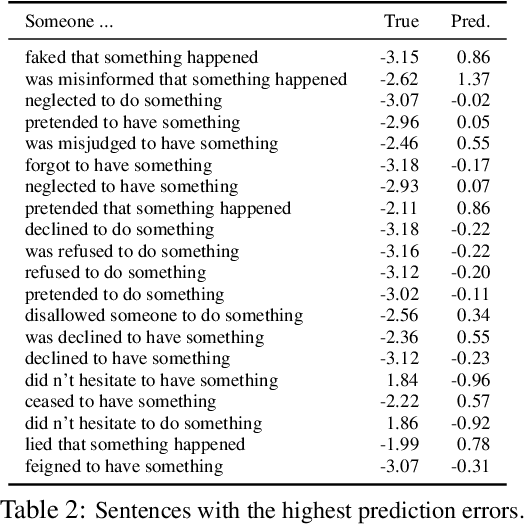
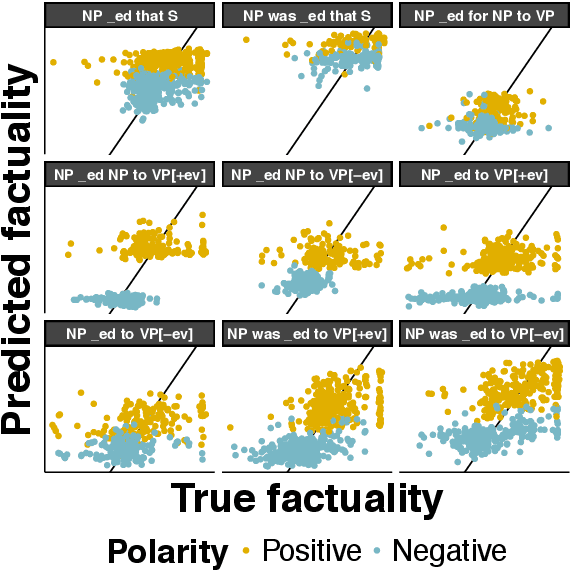
We investigate neural models' ability to capture lexicosyntactic inferences: inferences triggered by the interaction of lexical and syntactic information. We take the task of event factuality prediction as a case study and build a factuality judgment dataset for all English clause-embedding verbs in various syntactic contexts. We use this dataset, which we make publicly available, to probe the behavior of current state-of-the-art neural systems, showing that these systems make certain systematic errors that are clearly visible through the lens of factuality prediction.
Computational linking theory
Oct 08, 2016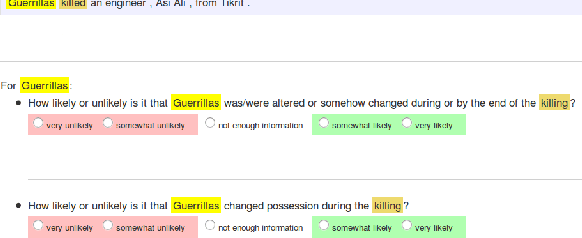


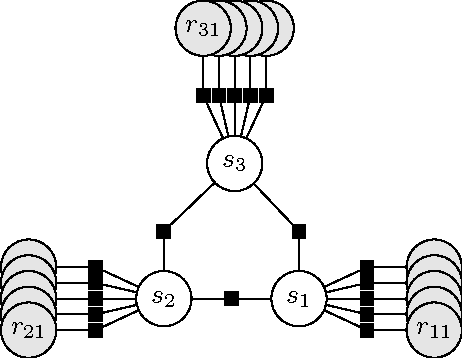
A linking theory explains how verbs' semantic arguments are mapped to their syntactic arguments---the inverse of the Semantic Role Labeling task from the shallow semantic parsing literature. In this paper, we develop the Computational Linking Theory framework as a method for implementing and testing linking theories proposed in the theoretical literature. We deploy this framework to assess two cross-cutting types of linking theory: local v. global models and categorical v. featural models. To further investigate the behavior of these models, we develop a measurement model in the spirit of previous work in semantic role induction: the Semantic Proto-Role Linking Model. We use this model, which implements a generalization of Dowty's seminal Proto-Role Theory, to induce semantic proto-roles, which we compare to those Dowty proposes.