 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Morphology in Topic Modeling
Paper and Code
Aug 13, 2016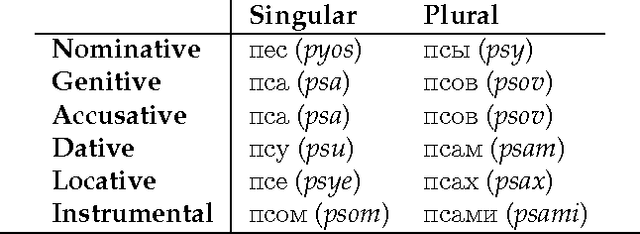


Topic models make strong assumptions about their data. In particular, different words are implicitly assumed to have different meanings: topic models are often used as human-interpretable dimensionality reductions and a proliferation of words with identical meanings would undermine the utility of the top-$m$ word list representation of a topic. Though a number of authors have added preprocessing steps such as lemmatization to better accommodate these assumptions, the effects of such data massaging have not been publicly studied. We make first steps toward elucidating the role of morphology in topic modeling by testing the effect of lemmatization on the interpretability of a latent Dirichlet allocation (LDA) model. Using a word intrusion evaluation, we quantitatively demonstrate that lemmatization provides a significant benefit to the interpretability of a model learned on Wikipedia articles in a morphologically rich language.