Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Effects of Leakage on Dependency Parsing
Paper and Code

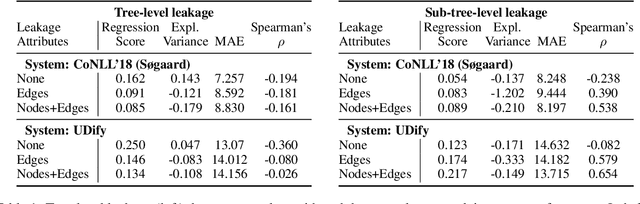

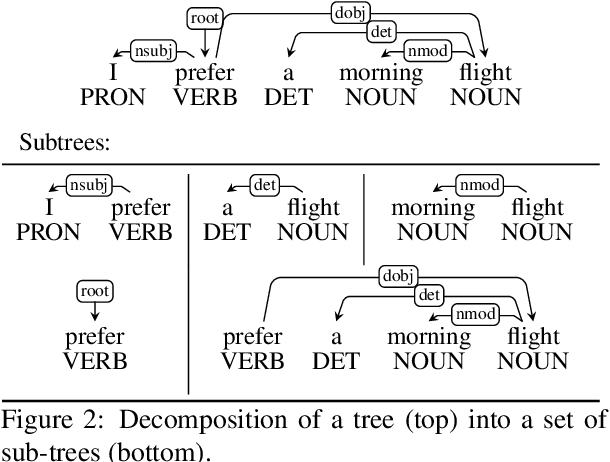
Recent work by S{\o}gaard (2020) showed that, treebank size aside, overlap between training and test graphs (termed leakage) explains more of the observed variation in dependency parsing performance than other explanations. In this work we revisit this claim, testing it on more models and languages. We find that it only holds for zero-shot cross-lingual settings. We then propose a more fine-grained measure of such leakage which, unlike the original measure, not only explains but also correlates with observed performance variation. Code and data are available here: https://github.com/miriamwanner/reu-nlp-project
* to be presented at ACL'22 Findings
View paper on