 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Impact of Accent on English Speech: Acoustic and Articulatory Perspectives
May 21, 2025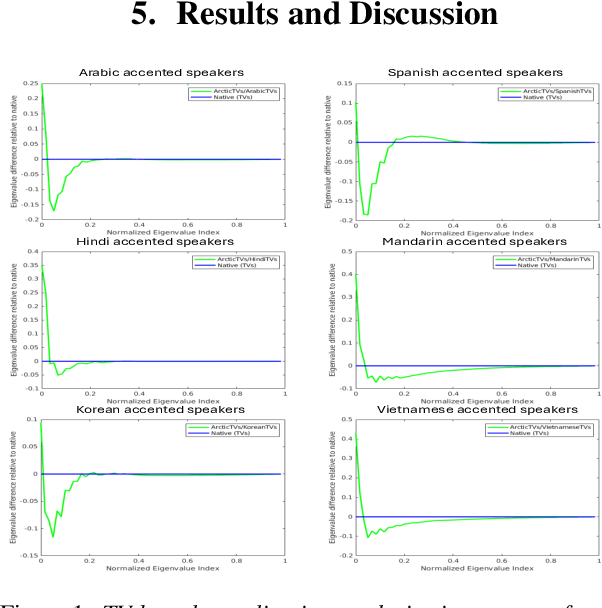
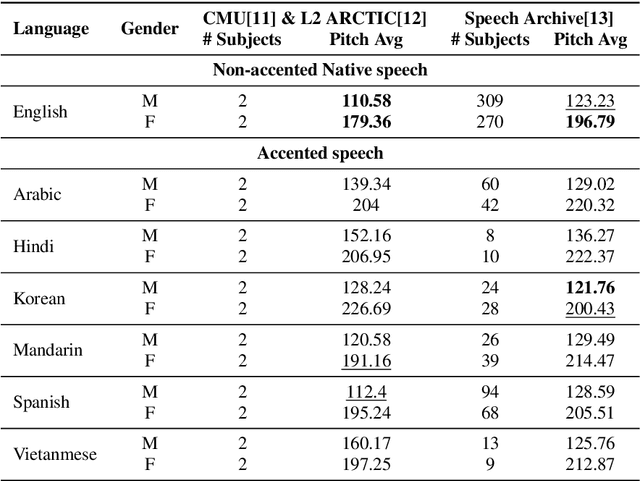
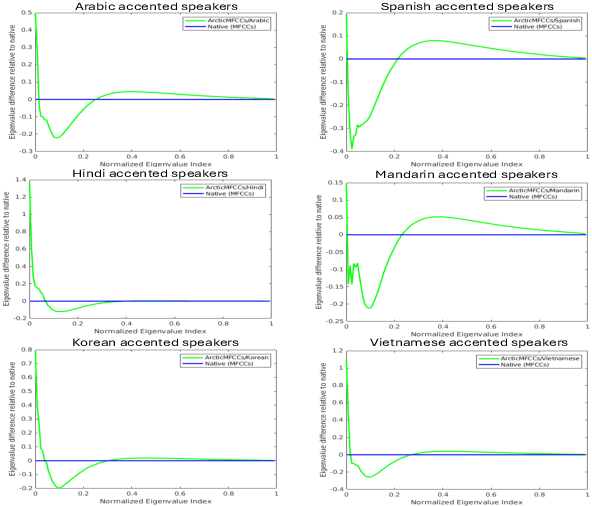
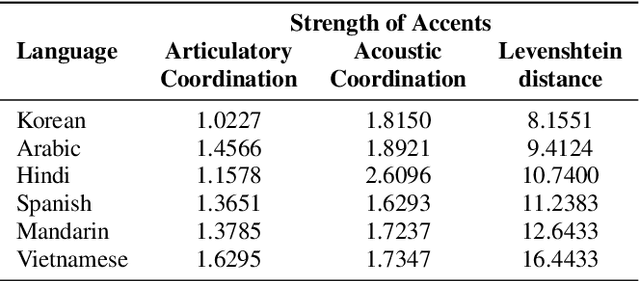
Advancements in AI-driven speech-based applications have transformed diverse industries ranging from healthcare to customer service. However, the increasing prevalence of non-native accented speech in global interactions poses significant challenges for speech-processing systems, which are often trained on datasets dominated by native speech. This study investigates accented English speech through articulatory and acoustic analysis, identifying simpler coordination patterns and higher average pitch than native speech. Using eigenspectra and Vocal Tract Variable-based coordination features, we establish an efficient method for quantifying accent strength without relying on resource-intensive phonetic transcriptions. Our findings provide a new avenue for research on the impacts of accents on speech intelligibility and offer insights for developing inclusive, robust speech processing systems that accommodate diverse linguistic communities.
Multimodal Biomarkers for Schizophrenia: Towards Individual Symptom Severity Estimation
May 21, 2025Studies on schizophrenia assessments using deep learning typically treat it as a classification task to detect the presence or absence of the disorder, oversimplifying the condition and reducing its clinical applicability. This traditional approach overlooks the complexity of schizophrenia, limiting its practical value in healthcare settings. This study shifts the focus to individual symptom severity estimation using a multimodal approach that integrates speech, video, and text inputs. We develop unimodal models for each modality and a multimodal framework to improve accuracy and robustness. By capturing a more detailed symptom profile, this approach can help in enhancing diagnostic precision and support personalized treatment, offering a scalable and objective tool for mental health assessment.
Speech-Based Estimation of Schizophrenia Severity Using Feature Fusion
Nov 20, 2024



Speech-based assessment of the schizophrenia spectrum has been widely researched over in the recent past. In this study, we develop a deep learning framework to estimate schizophrenia severity scores from speech using a feature fusion approach that fuses articulatory features with different self-supervised speech features extracted from pre-trained audio models. We also propose an auto-encoder-based self-supervised representation learning framework to extract compact articulatory embeddings from speech. Our top-performing speech-based fusion model with Multi-Head Attention (MHA) reduces Mean Absolute Error (MAE) by 9.18% and Root Mean Squared Error (RMSE) by 9.36% for schizophrenia severity estimation when compared with the previous models that combined speech and video inputs.
Self-supervised Multimodal Speech Representations for the Assessment of Schizophrenia Symptoms
Sep 15, 2024



Multimodal schizophrenia assessment systems have gained traction over the last few years. This work introduces a schizophrenia assessment system to discern between prominent symptom classes of schizophrenia and predict an overall schizophrenia severity score. We develop a Vector Quantized Variational Auto-Encoder (VQ-VAE) based Multimodal Representation Learning (MRL) model to produce task-agnostic speech representations from vocal Tract Variables (TVs) and Facial Action Units (FAUs). These representations are then used in a Multi-Task Learning (MTL) based downstream prediction model to obtain class labels and an overall severity score. The proposed framework outperforms the previous works on the multi-class classification task across all evaluation metrics (Weighted F1 score, AUC-ROC score, and Weighted Accuracy). Additionally, it estimates the schizophrenia severity score, a task not addressed by earlier approaches.
A Multimodal Framework for the Assessment of the Schizophrenia Spectrum
Jun 14, 2024This paper presents a novel multimodal framework to distinguish between different symptom classes of subjects in the schizophrenia spectrum and healthy controls using audio, video, and text modalities. We implemented Convolution Neural Network and Long Short Term Memory based unimodal models and experimented on various multimodal fusion approaches to come up with the proposed framework. We utilized a minimal Gated multimodal unit (mGMU) to obtain a bi-modal intermediate fusion of the features extracted from the input modalities before finally fusing the outputs of the bimodal fusions to perform subject-wise classifications. The use of mGMU units in the multimodal framework improved the performance in both weighted f1-score and weighted AUC-ROC scores.
A multi-modal approach for identifying schizophrenia using cross-modal attention
Sep 26, 2023This study focuses on how different modalities of human communication can be used to distinguish between healthy controls and subjects with schizophrenia who exhibit strong positive symptoms. We developed a multi-modal schizophrenia classification system using audio, video, and text. Facial action units and vocal tract variables were extracted as low-level features from video and audio respectively, which were then used to compute high-level coordination features that served as the inputs to the audio and video modalities. Context-independent text embeddings extracted from transcriptions of speech were used as the input for the text modality. The multi-modal system is developed by fusing a segment-to-session-level classifier for video and audio modalities with a text model based on a Hierarchical Attention Network (HAN) with cross-modal attention. The proposed multi-modal system outperforms the previous state-of-the-art multi-modal system by 8.53% in the weighted average F1 score.