 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Compute the Articulatory Representations of Speech with the MIRRORNET
Oct 29, 2022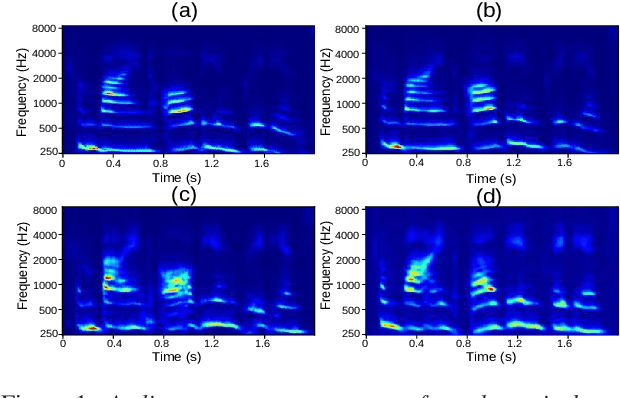
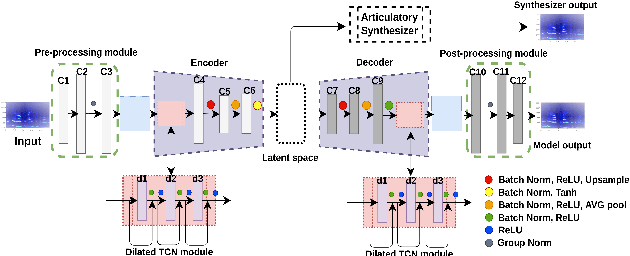
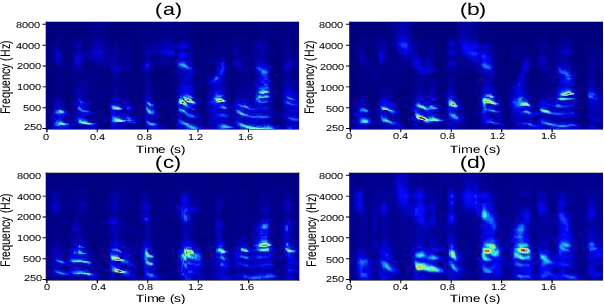
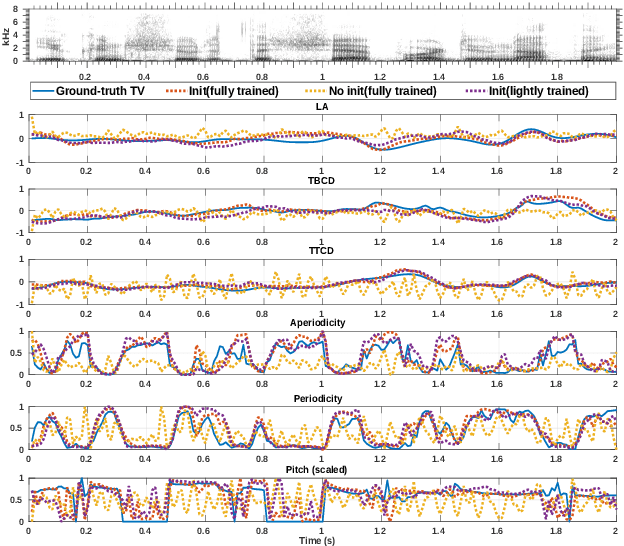
Most organisms including humans function by coordinating and integrating sensory signals with motor actions to survive and accomplish desired tasks. Learning these complex sensorimotor mappings proceeds simultaneously and often in an unsupervised or semi-supervised fashion. An autoencoder architecture (MirrorNet) inspired by this sensorimotor learning paradigm is explored in this work to learn how to control an articulatory synthesizer. The synthesizer takes as input control signals consisting of six vocal Tract Variables (TVs) and source features (voicing indicators and pitch), and generates the corresponding auditory spectrograms. Due to the non-linear structure of the synthesizer, the control parameters that produce a target speech signal are not readily computable nor are they always unique. Here we demonstrate how to initialize the MirrorNet learning so as to produce a meaningful range of articulatory values. Once trained, the MirrorNet successfully estimates the TVs and source features needed to synthesize any arbitrary speech utterance. This approach outperforms the best previously designed `speech inversion' systems on the Wisconsin X-ray microbeam (XRMB) dataset.
An Empirical Analysis on the Vulnerabilities of End-to-End Speech Segregation Models
Jun 20, 2022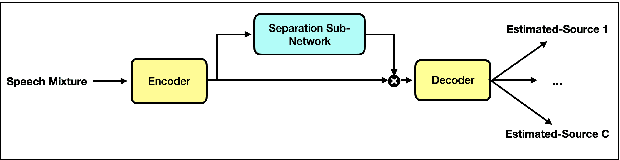
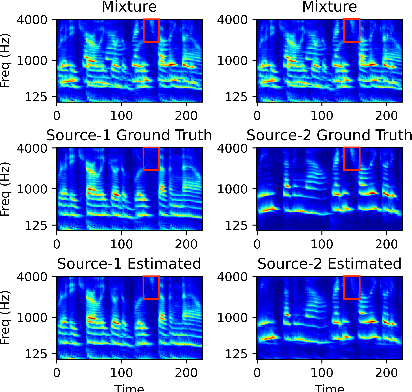
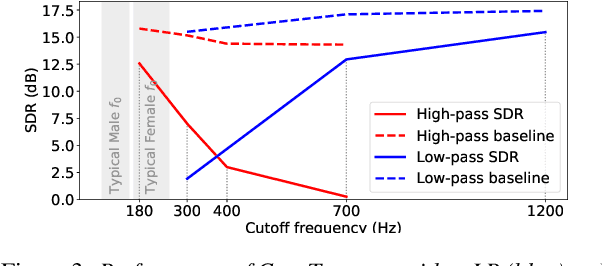
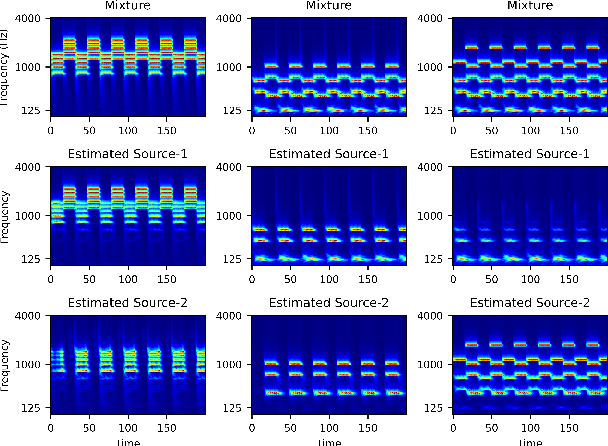
End-to-end learning models have demonstrated a remarkable capability in performing speech segregation. Despite their wide-scope of real-world applications, little is known about the mechanisms they employ to group and consequently segregate individual speakers. Knowing that harmonicity is a critical cue for these networks to group sources, in this work, we perform a thorough investigation on ConvTasnet and DPT-Net to analyze how they perform a harmonic analysis of the input mixture. We perform ablation studies where we apply low-pass, high-pass, and band-stop filters of varying pass-bands to empirically analyze the harmonics most critical for segregation. We also investigate how these networks decide which output channel to assign to an estimated source by introducing discontinuities in synthetic mixtures. We find that end-to-end networks are highly unstable, and perform poorly when confronted with deformations which are imperceptible to humans. Replacing the encoder in these networks with a spectrogram leads to lower overall performance, but much higher stability. This work helps us to understand what information these network rely on for speech segregation, and exposes two sources of generalization-errors. It also pinpoints the encoder as the part of the network responsible for these errors, allowing for a redesign with expert knowledge or transfer learning.
Acoustic To Articulatory Speech Inversion Using Multi-Resolution Spectro-Temporal Representations Of Speech Signals
Mar 11, 2022

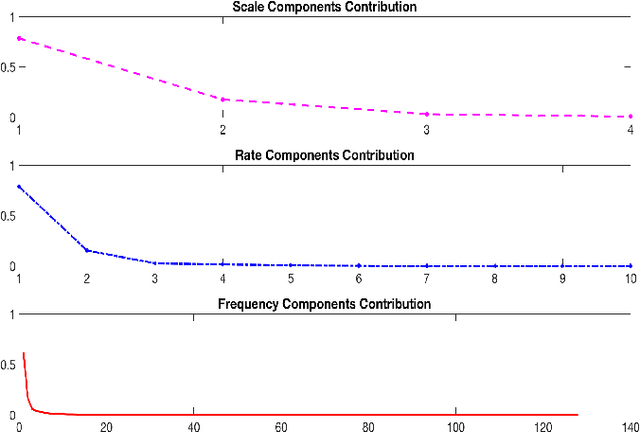

Multi-resolution spectro-temporal features of a speech signal represent how the brain perceives sounds by tuning cortical cells to different spectral and temporal modulations. These features produce a higher dimensional representation of the speech signals. The purpose of this paper is to evaluate how well the auditory cortex representation of speech signals contribute to estimate articulatory features of those corresponding signals. Since obtaining articulatory features from acoustic features of speech signals has been a challenging topic of interest for different speech communities, we investigate the possibility of using this multi-resolution representation of speech signals as acoustic features. We used U. of Wisconsin X-ray Microbeam (XRMB) database of clean speech signals to train a feed-forward deep neural network (DNN) to estimate articulatory trajectories of six tract variables. The optimal set of multi-resolution spectro-temporal features to train the model were chosen using appropriate scale and rate vector parameters to obtain the best performing model. Experiments achieved a correlation of 0.675 with ground-truth tract variables. We compared the performance of this speech inversion system with prior experiments conducted using Mel Frequency Cepstral Coefficients (MFCCs).
Harmonicity Plays a Critical Role in DNN Based Versus in Biologically-Inspired Monaural Speech Segregation Systems
Mar 08, 2022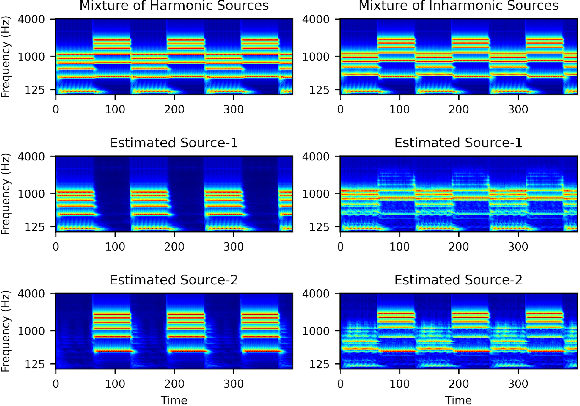
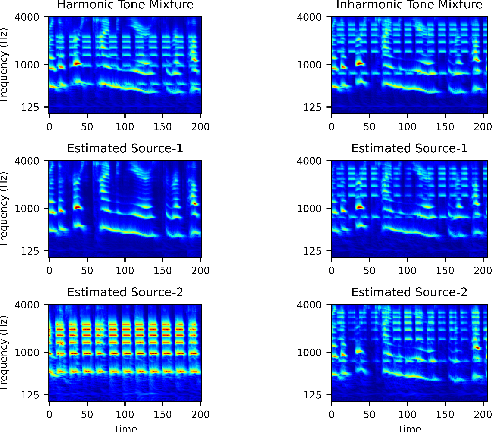
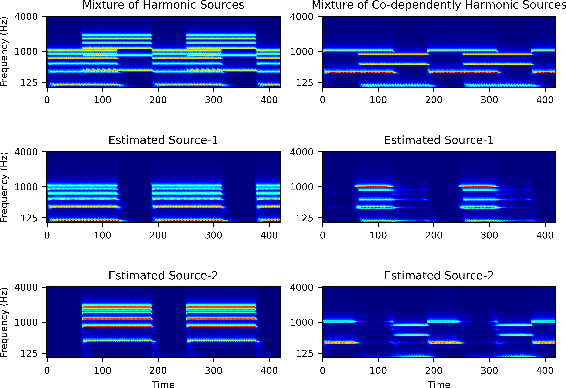
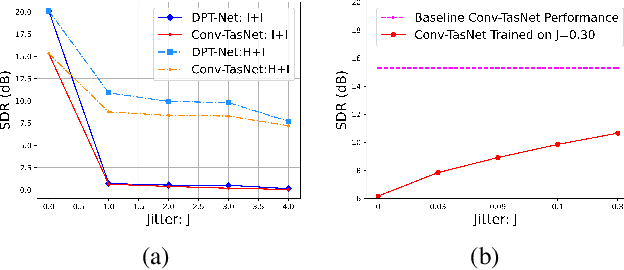
Recent advancements in deep learning have led to drastic improvements in speech segregation models. Despite their success and growing applicability, few efforts have been made to analyze the underlying principles that these networks learn to perform segregation. Here we analyze the role of harmonicity on two state-of-the-art Deep Neural Networks (DNN)-based models- Conv-TasNet and DPT-Net. We evaluate their performance with mixtures of natural speech versus slightly manipulated inharmonic speech, where harmonics are slightly frequency jittered. We find that performance deteriorates significantly if one source is even slightly harmonically jittered, e.g., an imperceptible 3% harmonic jitter degrades performance of Conv-TasNet from 15.4 dB to 0.70 dB. Training the model on inharmonic speech does not remedy this sensitivity, instead resulting in worse performance on natural speech mixtures, making inharmonicity a powerful adversarial factor in DNN models. Furthermore, additional analyses reveal that DNN algorithms deviate markedly from biologically inspired algorithms that rely primarily on timing cues and not harmonicity to segregate speech.
The Mirrornet : Learning Audio Synthesizer Controls Inspired by Sensorimotor Interaction
Oct 18, 2021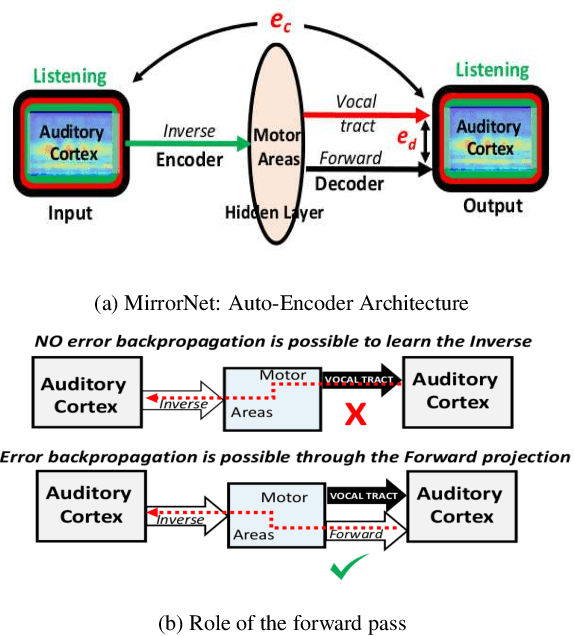
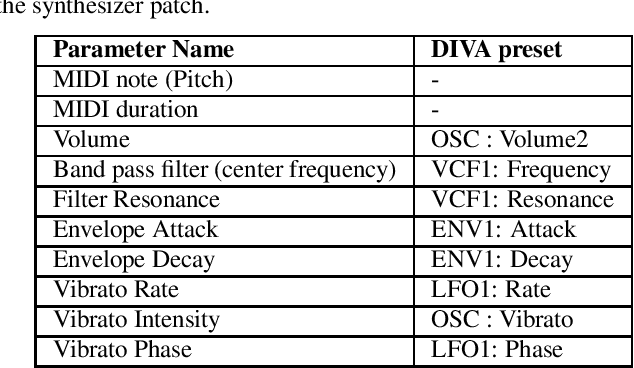
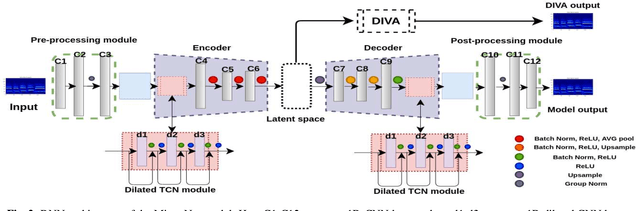
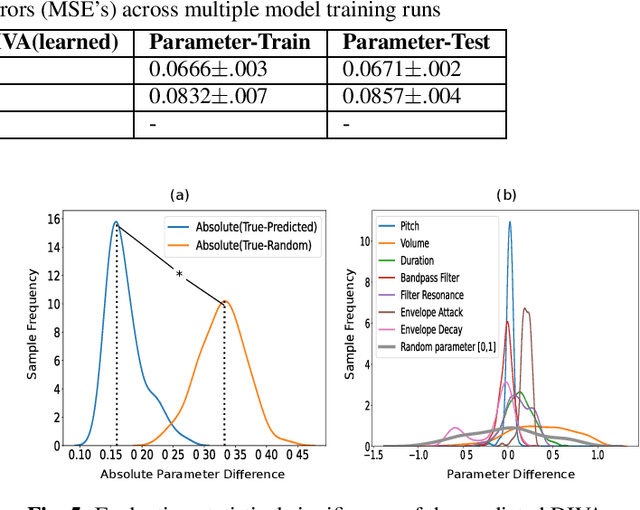
Experiments to understand the sensorimotor neural interactions in the human cortical speech system support the existence of a bidirectional flow of interactions between the auditory and motor regions. Their key function is to enable the brain to 'learn' how to control the vocal tract for speech production. This idea is the impetus for the recently proposed "MirrorNet", a constrained autoencoder architecture. In this paper, the MirrorNet is applied to learn, in an unsupervised manner, the controls of a specific audio synthesizer (DIVA) to produce melodies only from their auditory spectrograms. The results demonstrate how the MirrorNet discovers the synthesizer parameters to generate the melodies that closely resemble the original and those of unseen melodies, and even determine the best set parameters to approximate renditions of complex piano melodies generated by a different synthesizer. This generalizability of the MirrorNet illustrates its potential to discover from sensory data the controls of arbitrary motor-plants such as autonomous vehicles.