 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Rainbow in Deep Network Black Boxes
May 29, 2023We introduce rainbow networks as a probabilistic model of trained deep neural networks. The model cascades random feature maps whose weight distributions are learned. It assumes that dependencies between weights at different layers are reduced to rotations which align the input activations. Neuron weights within a layer are independent after this alignment. Their activations define kernels which become deterministic in the infinite-width limit. This is verified numerically for ResNets trained on the ImageNet dataset. We also show that the learned weight distributions have low-rank covariances. Rainbow networks thus alternate between linear dimension reductions and non-linear high-dimensional embeddings with white random features. Gaussian rainbow networks are defined with Gaussian weight distributions. These models are validated numerically on image classification on the CIFAR-10 dataset, with wavelet scattering networks. We further show that during training, SGD updates the weight covariances while mostly preserving the Gaussian initialization.
An Empirical Analysis on the Vulnerabilities of End-to-End Speech Segregation Models
Jun 20, 2022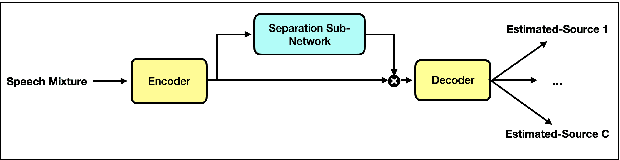
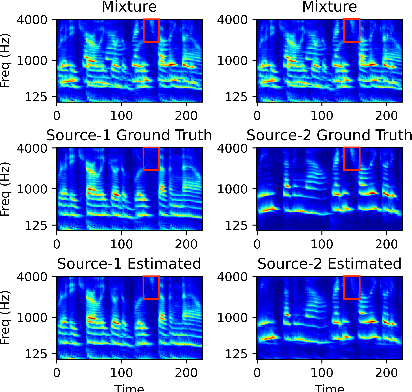
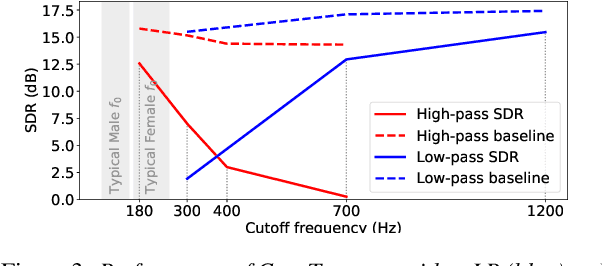
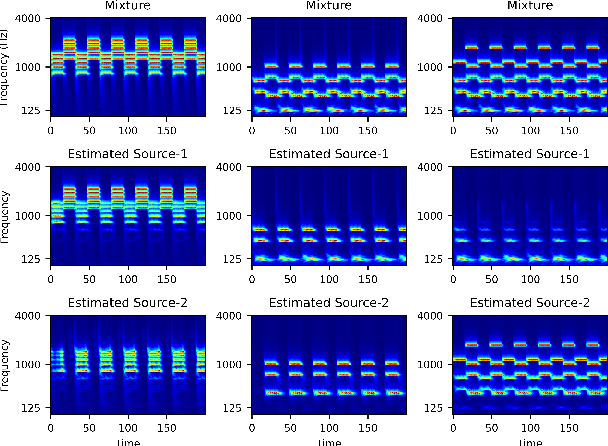
End-to-end learning models have demonstrated a remarkable capability in performing speech segregation. Despite their wide-scope of real-world applications, little is known about the mechanisms they employ to group and consequently segregate individual speakers. Knowing that harmonicity is a critical cue for these networks to group sources, in this work, we perform a thorough investigation on ConvTasnet and DPT-Net to analyze how they perform a harmonic analysis of the input mixture. We perform ablation studies where we apply low-pass, high-pass, and band-stop filters of varying pass-bands to empirically analyze the harmonics most critical for segregation. We also investigate how these networks decide which output channel to assign to an estimated source by introducing discontinuities in synthetic mixtures. We find that end-to-end networks are highly unstable, and perform poorly when confronted with deformations which are imperceptible to humans. Replacing the encoder in these networks with a spectrogram leads to lower overall performance, but much higher stability. This work helps us to understand what information these network rely on for speech segregation, and exposes two sources of generalization-errors. It also pinpoints the encoder as the part of the network responsible for these errors, allowing for a redesign with expert knowledge or transfer learning.
Scale Dependencies and Self-Similarity Through Wavelet Scattering Covariance
Apr 19, 2022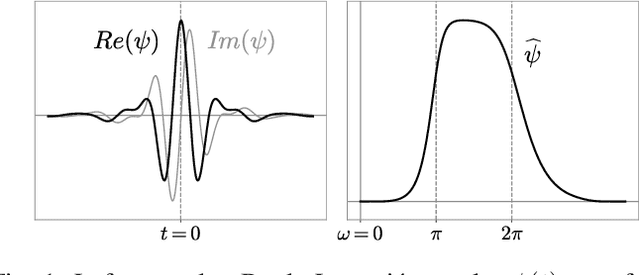

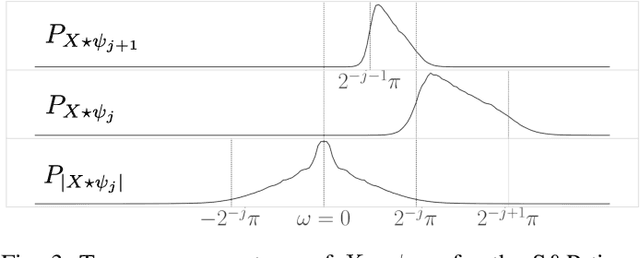
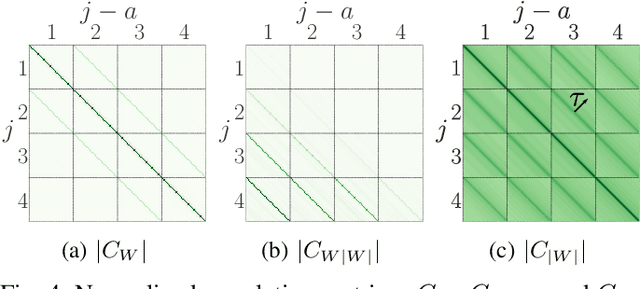
We introduce a scattering covariance matrix which provides non-Gaussian models of time-series having stationary increments. A complex wavelet transform computes signal variations at each scale. Dependencies across scales are captured by the joint covariance across time and scales of complex wavelet coefficients and their modulus. This covariance is nearly diagonalized by a second wavelet transform, which defines the scattering covariance. We show that this set of moments characterizes a wide range of non-Gaussian properties of multi-scale processes. This is analyzed for a variety of processes, including fractional Brownian motions, Poisson, multifractal random walks and Hawkes processes. We prove that self-similar processes have a scattering covariance matrix which is scale invariant. This property can be estimated numerically and defines a class of wide-sense self-similar processes. We build maximum entropy models conditioned by scattering covariance coefficients, and generate new time-series with a microcanonical sampling algorithm. Applications are shown for highly non-Gaussian financial and turbulence time-series.
Efficient Per-Example Gradient Computations in Convolutional Neural Networks
Dec 12, 2019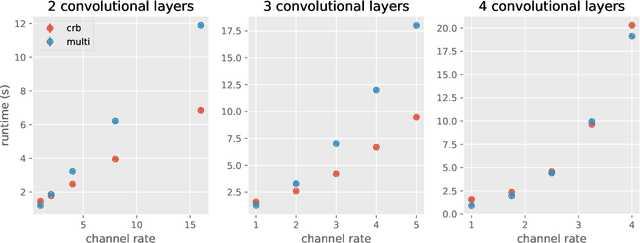

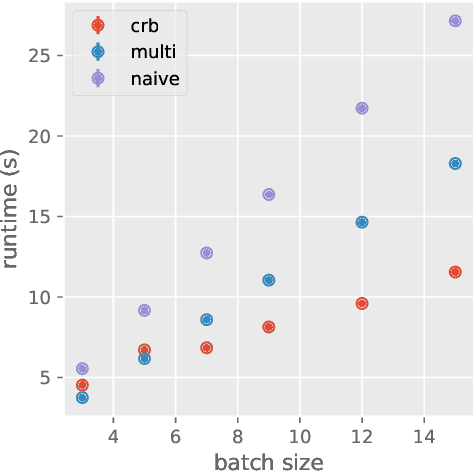
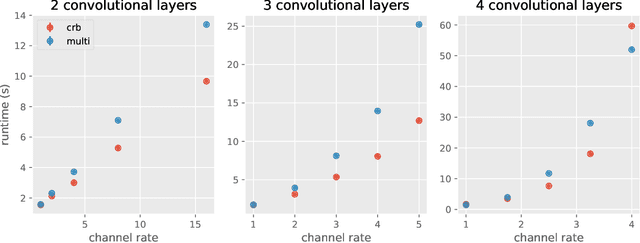
Deep learning frameworks leverage GPUs to perform massively-parallel computations over batches of many training examples efficiently. However, for certain tasks, one may be interested in performing per-example computations, for instance using per-example gradients to evaluate a quantity of interest unique to each example. One notable application comes from the field of differential privacy, where per-example gradients must be norm-bounded in order to limit the impact of each example on the aggregated batch gradient. In this work, we discuss how per-example gradients can be efficiently computed in convolutional neural networks (CNNs). We compare existing strategies by performing a few steps of differentially-private training on CNNs of varying sizes. We also introduce a new strategy for per-example gradient calculation, which is shown to be advantageous depending on the model architecture and how the model is trained. This is a first step in making differentially-private training of CNNs practical.
Kymatio: Scattering Transforms in Python
Dec 28, 2018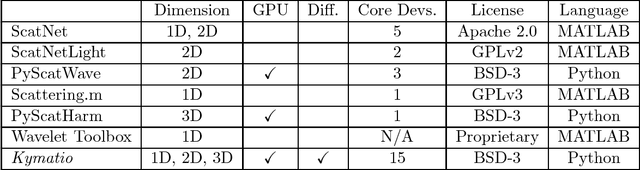
The wavelet scattering transform is an invariant signal representation suitable for many signal processing and machine learning applications. We present the Kymatio software package, an easy-to-use, high-performance Python implementation of the scattering transform in 1D, 2D, and 3D that is compatible with modern deep learning frameworks. All transforms may be executed on a GPU (in addition to CPU), offering a considerable speed up over CPU implementations. The package also has a small memory footprint, resulting inefficient memory usage. The source code, documentation, and examples are available undera BSD license at https://www.kymat.io/
Phase Harmonics and Correlation Invariants in Convolutional Neural Networks
Oct 29, 2018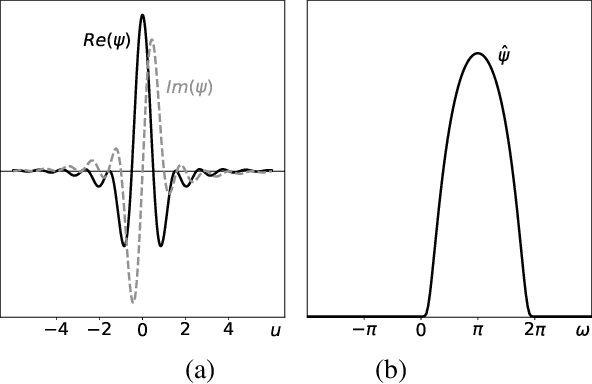



We prove that linear rectifiers act as phase transformations on complex analytic extensions of convolutional network coefficients. These phase transformations are linearized over a set of phase harmonics, computed with a Fourier transform. The correlation matrix of one-layer convolutional network coefficients is a translation invariant representation, which is used to build statistical models of stationary processes. We prove that it is Lipschitz continuous and that it has a sparse representation over phase harmonics. When network filters are wavelets, phase harmonic correlations provide important information about phase alignments across scales. We demonstrate numerically that large classes of one-dimensional signals and images are precisely reconstructed with a small fraction of phase harmonic correlations.