 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhase Collapse in Neural Networks
Oct 11, 2021



Deep convolutional image classifiers progressively transform the spatial variability into a smaller number of channels, which linearly separates all classes. A fundamental challenge is to understand the role of rectifiers together with convolutional filters in this transformation. Rectifiers with biases are often interpreted as thresholding operators which improve sparsity and discrimination. This paper demonstrates that it is a different phase collapse mechanism which explains the ability to progressively eliminate spatial variability, while improving linear class separation. This is explained and shown numerically by defining a simplified complex-valued convolutional network architecture. It implements spatial convolutions with wavelet filters and uses a complex modulus to collapse phase variables. This phase collapse network reaches the classification accuracy of ResNets of similar depths, whereas its performance is considerably degraded when replacing the phase collapse with thresholding operators. This is justified by explaining how iterated phase collapses progressively improve separation of class means, as opposed to thresholding non-linearities.
Separation and Concentration in Deep Networks
Dec 18, 2020

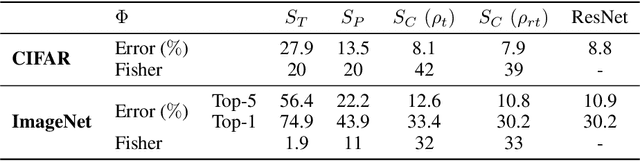

Numerical experiments demonstrate that deep neural network classifiers progressively separate class distributions around their mean, achieving linear separability on the training set, and increasing the Fisher discriminant ratio. We explain this mechanism with two types of operators. We prove that a rectifier without biases applied to sign-invariant tight frames can separate class means and increase Fisher ratios. On the opposite, a soft-thresholding on tight frames can reduce within-class variabilities while preserving class means. Variance reduction bounds are proved for Gaussian mixture models. For image classification, we show that separation of class means can be achieved with rectified wavelet tight frames that are not learned. It defines a scattering transform. Learning $1 \times 1$ convolutional tight frames along scattering channels and applying a soft-thresholding reduces within-class variabilities. The resulting scattering network reaches the classification accuracy of ResNet-18 on CIFAR-10 and ImageNet, with fewer layers and no learned biases.
Deep Network classification by Scattering and Homotopy dictionary learning
Oct 08, 2019



We introduce a sparse scattering deep convolutional neural network, which provides a simple model to analyze properties of deep representation learning for classification. Learning a single dictionary matrix with a classifier yields a higher classification accuracy than AlexNet over the ImageNet ILSVRC2012 dataset. The network first applies a scattering transform which linearizes variabilities due to geometric transformations such as translations and small deformations. A sparse l1 dictionary coding reduces intra-class variability while preserving class separation through projections over unions of linear spaces. It is implemented in a deep convolutional network with a homotopy algorithm having an exponential convergence. A convergence proof is given in a general framework including ALISTA. Classification results are analyzed over ImageNet.
Kymatio: Scattering Transforms in Python
Dec 28, 2018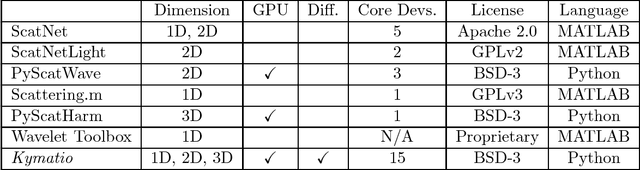
The wavelet scattering transform is an invariant signal representation suitable for many signal processing and machine learning applications. We present the Kymatio software package, an easy-to-use, high-performance Python implementation of the scattering transform in 1D, 2D, and 3D that is compatible with modern deep learning frameworks. All transforms may be executed on a GPU (in addition to CPU), offering a considerable speed up over CPU implementations. The package also has a small memory footprint, resulting inefficient memory usage. The source code, documentation, and examples are available undera BSD license at https://www.kymat.io/