 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic To Articulatory Speech Inversion Using Multi-Resolution Spectro-Temporal Representations Of Speech Signals
Mar 11, 2022

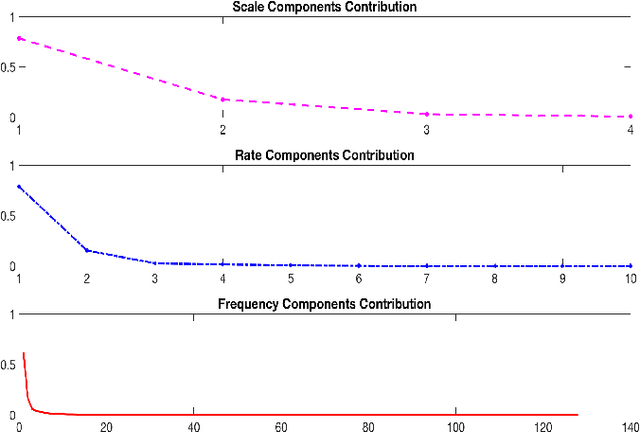

Multi-resolution spectro-temporal features of a speech signal represent how the brain perceives sounds by tuning cortical cells to different spectral and temporal modulations. These features produce a higher dimensional representation of the speech signals. The purpose of this paper is to evaluate how well the auditory cortex representation of speech signals contribute to estimate articulatory features of those corresponding signals. Since obtaining articulatory features from acoustic features of speech signals has been a challenging topic of interest for different speech communities, we investigate the possibility of using this multi-resolution representation of speech signals as acoustic features. We used U. of Wisconsin X-ray Microbeam (XRMB) database of clean speech signals to train a feed-forward deep neural network (DNN) to estimate articulatory trajectories of six tract variables. The optimal set of multi-resolution spectro-temporal features to train the model were chosen using appropriate scale and rate vector parameters to obtain the best performing model. Experiments achieved a correlation of 0.675 with ground-truth tract variables. We compared the performance of this speech inversion system with prior experiments conducted using Mel Frequency Cepstral Coefficients (MFCCs).
Multimodal Depression Classification Using Articulatory Coordination Features And Hierarchical Attention Based Text Embeddings
Feb 13, 2022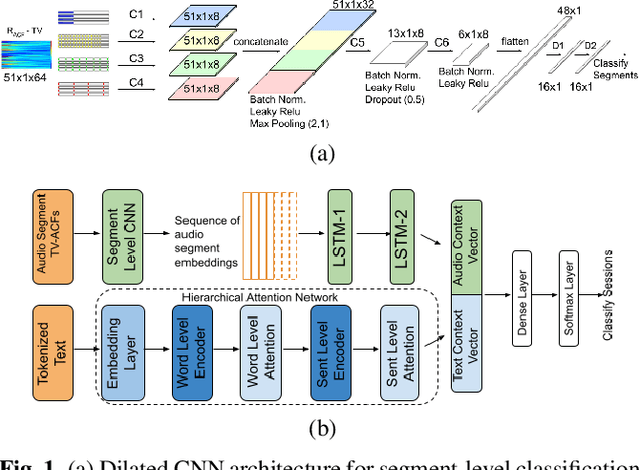

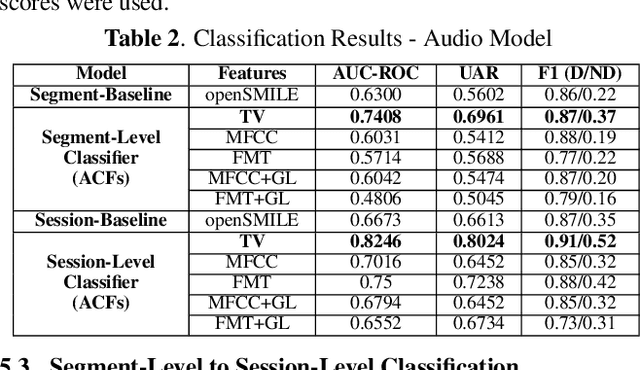
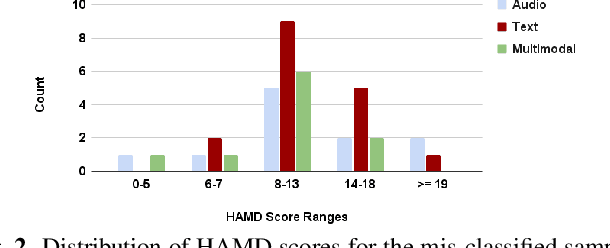
Multimodal depression classification has gained immense popularity over the recent years. We develop a multimodal depression classification system using articulatory coordination features extracted from vocal tract variables and text transcriptions obtained from an automatic speech recognition tool that yields improvements of area under the receiver operating characteristics curve compared to uni-modal classifiers (7.5% and 13.7% for audio and text respectively). We show that in the case of limited training data, a segment-level classifier can first be trained to then obtain a session-wise prediction without hindering the performance, using a multi-stage convolutional recurrent neural network. A text model is trained using a Hierarchical Attention Network (HAN). The multimodal system is developed by combining embeddings from the session-level audio model and the HAN text model
Speech based Depression Severity Level Classification Using a Multi-Stage Dilated CNN-LSTM Model
Apr 09, 2021


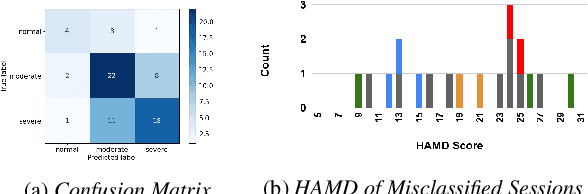
Speech based depression classification has gained immense popularity over the recent years. However, most of the classification studies have focused on binary classification to distinguish depressed subjects from non-depressed subjects. In this paper, we formulate the depression classification task as a severity level classification problem to provide more granularity to the classification outcomes. We use articulatory coordination features (ACFs) developed to capture the changes of neuromotor coordination that happens as a result of psychomotor slowing, a necessary feature of Major Depressive Disorder. The ACFs derived from the vocal tract variables (TVs) are used to train a dilated Convolutional Neural Network based depression classification model to obtain segment-level predictions. Then, we propose a Recurrent Neural Network based approach to obtain session-level predictions from segment-level predictions. We show that strengths of the segment-wise classifier are amplified when a session-wise classifier is trained on embeddings obtained from it. The model trained on ACFs derived from TVs show relative improvement of 27.47% in Unweighted Average Recall (UAR) at the session-level classification task, compared to the ACFs derived from Mel Frequency Cepstral Coefficients (MFCCs).
Deep Learning Based Generalized Models for Depression Classification
Nov 13, 2020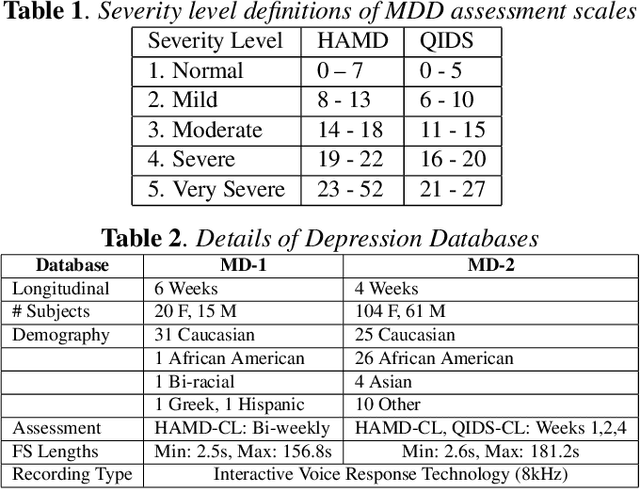

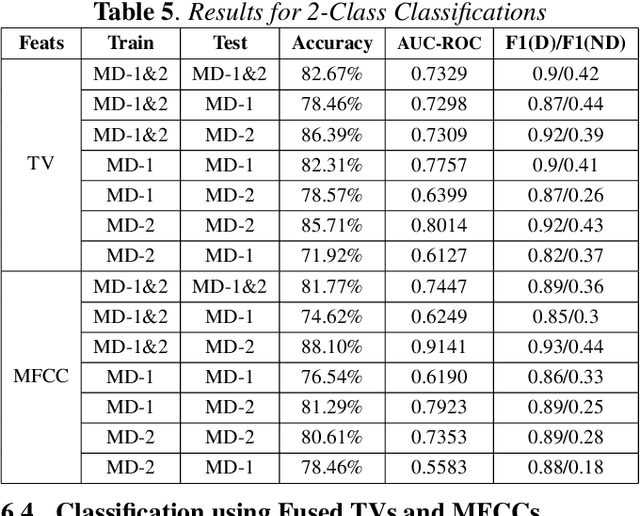
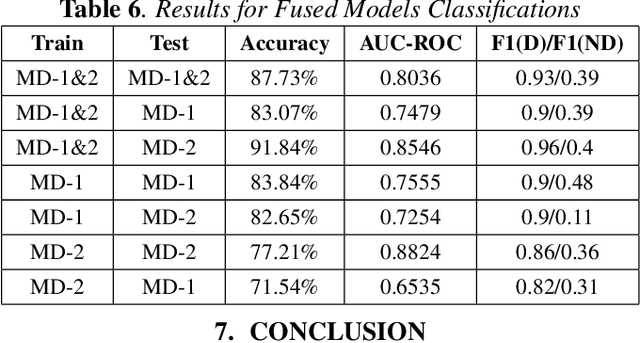
Depression detection using vocal biomarkers is a highly researched area. Articulatory coordination features (ACFs) are developed based on the changes in neuromotor coordination due to psychomotor slowing, a key feature of Major Depressive Disorder. However findings of existing studies are mostly validated on a single database which limits the generalizability of results. Variability across different depression databases adversely affects the results in cross corpus evaluations (CCEs). We propose to develop a generalized classifier for depression detection using a dilated Convolutional Neural Network which is trained on ACFs extracted from two depression databases. We show that ACFs derived from Vocal Tract Variables (TVs) show promise as a robust set of features for depression detection. Our model achieves relative accuracy improvements of ~10% compared to CCEs performed on models trained on a single database. We extend the study to show that fusing TVs and Mel-Frequency Cepstral Coefficients can further improve the performance of this classifier.