 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePindrop it! Audio and Visual Deepfake Countermeasures for Robust Detection and Fine Grained-Localization
Aug 11, 2025The field of visual and audio generation is burgeoning with new state-of-the-art methods. This rapid proliferation of new techniques underscores the need for robust solutions for detecting synthetic content in videos. In particular, when fine-grained alterations via localized manipulations are performed in visual, audio, or both domains, these subtle modifications add challenges to the detection algorithms. This paper presents solutions for the problems of deepfake video classification and localization. The methods were submitted to the ACM 1M Deepfakes Detection Challenge, achieving the best performance in the temporal localization task and a top four ranking in the classification task for the TestA split of the evaluation dataset.
Open-Set Source Tracing of Audio Deepfake Systems
Jul 09, 2025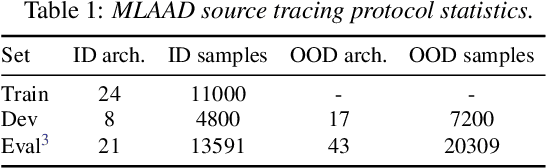
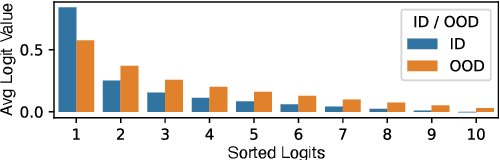
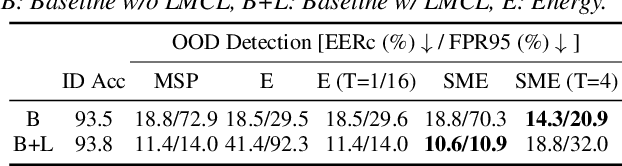
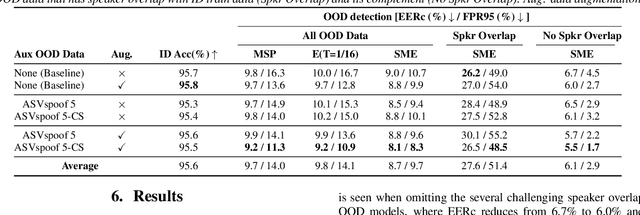
Existing research on source tracing of audio deepfake systems has focused primarily on the closed-set scenario, while studies that evaluate open-set performance are limited to a small number of unseen systems. Due to the large number of emerging audio deepfake systems, robust open-set source tracing is critical. We leverage the protocol of the Interspeech 2025 special session on source tracing to evaluate methods for improving open-set source tracing performance. We introduce a novel adaptation to the energy score for out-of-distribution (OOD) detection, softmax energy (SME). We find that replacing the typical temperature-scaled energy score with SME provides a relative average improvement of 31% in the standard FPR95 (false positive rate at true positive rate of 95%) measure. We further explore SME-guided training as well as copy synthesis, codec, and reverberation augmentations, yielding an FPR95 of 8.3%.
Source Tracing of Audio Deepfake Systems
Jul 10, 2024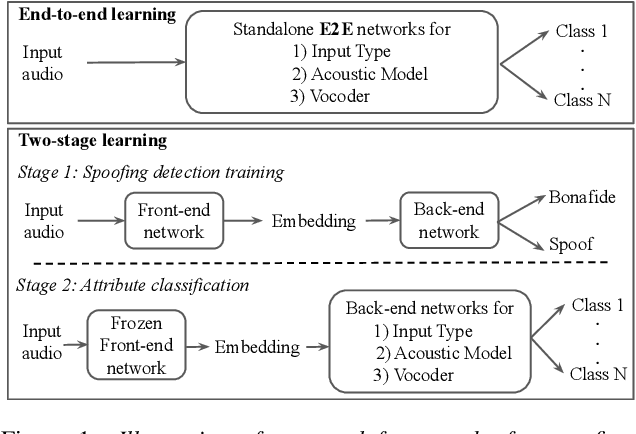
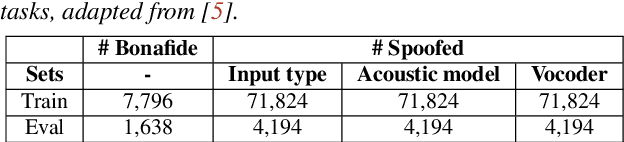

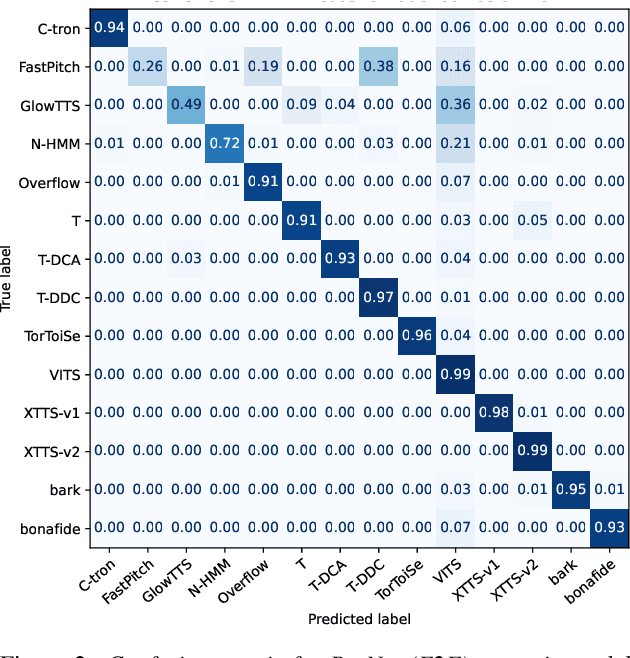
Recent progress in generative AI technology has made audio deepfakes remarkably more realistic. While current research on anti-spoofing systems primarily focuses on assessing whether a given audio sample is fake or genuine, there has been limited attention on discerning the specific techniques to create the audio deepfakes. Algorithms commonly used in audio deepfake generation, like text-to-speech (TTS) and voice conversion (VC), undergo distinct stages including input processing, acoustic modeling, and waveform generation. In this work, we introduce a system designed to classify various spoofing attributes, capturing the distinctive features of individual modules throughout the entire generation pipeline. We evaluate our system on two datasets: the ASVspoof 2019 Logical Access and the Multi-Language Audio Anti-Spoofing Dataset (MLAAD). Results from both experiments demonstrate the robustness of the system to identify the different spoofing attributes of deepfake generation systems.
Phonetic Richness for Improved Automatic Speaker Verification
Jul 10, 2024When it comes to authentication in speaker verification systems, not all utterances are created equal. It is essential to estimate the quality of test utterances in order to account for varying acoustic conditions. In addition to the net-speech duration of an utterance, it is observed in this paper that phonetic richness is also a key indicator of utterance quality, playing a significant role in accurate speaker verification. Several phonetic histogram based formulations of phonetic richness are explored using transcripts obtained from an automatic speaker recognition system. The proposed phonetic richness measure is found to be positively correlated with voice authentication scores across evaluation benchmarks. Additionally, the proposed measure in combination with net speech helps in calibrating the speaker verification scores, obtaining a relative EER improvement of 5.8% on the Voxceleb1 evaluation protocol. The proposed phonetic richness based calibration provides higher benefit for short utterances with repeated words.