 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulatory and bottleneck features for speaker-independent ASR of dysarthric speech
Paper and Code
May 21, 2019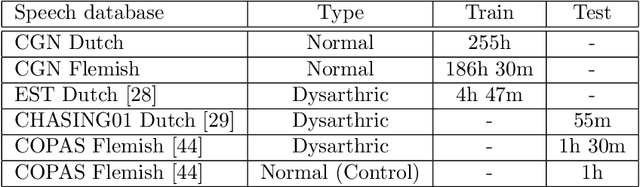
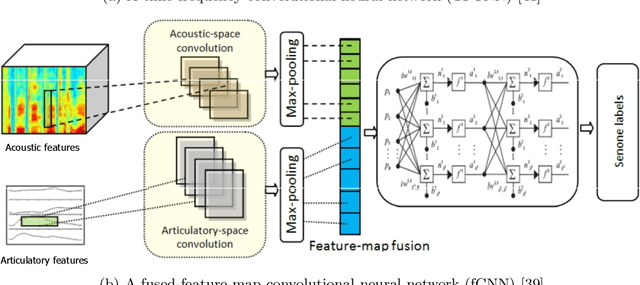
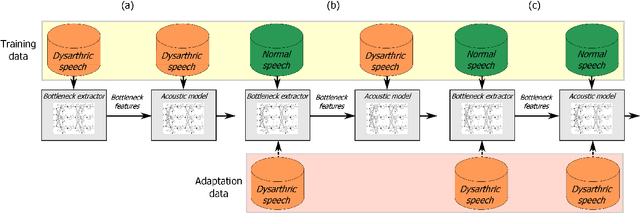
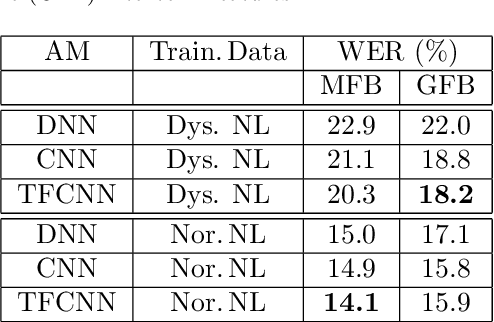
The rapid population aging has stimulated the development of assistive devices that provide personalized medical support to the needies suffering from various etiologies. One prominent clinical application is a computer-assisted speech training system which enables personalized speech therapy to patients impaired by communicative disorders in the patient's home environment. Such a system relies on the robust automatic speech recognition (ASR) technology to be able to provide accurate articulation feedback. With the long-term aim of developing off-the-shelf ASR systems that can be incorporated in clinical context without prior speaker information, we compare the ASR performance of speaker-independent bottleneck and articulatory features on dysarthric speech used in conjunction with dedicated neural network-based acoustic models that have been shown to be robust against spectrotemporal deviations. We report ASR performance of these systems on two dysarthric speech datasets of different characteristics to quantify the achieved performance gains. Despite the remaining performance gap between the dysarthric and normal speech, significant improvements have been reported on both datasets using speaker-independent ASR architectures.