 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Deep Neural Network Activation Entropy to cope with Unseen Data in Speech Recognition
Paper and Code
Aug 31, 2017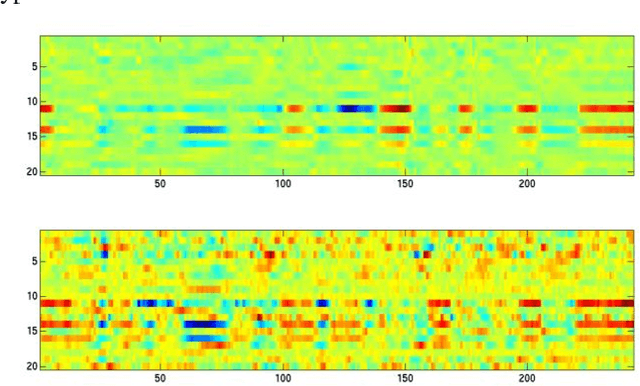
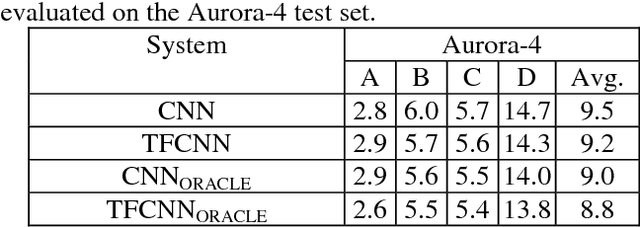
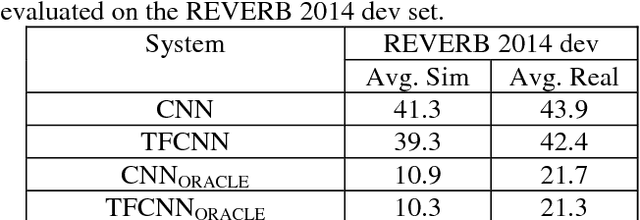
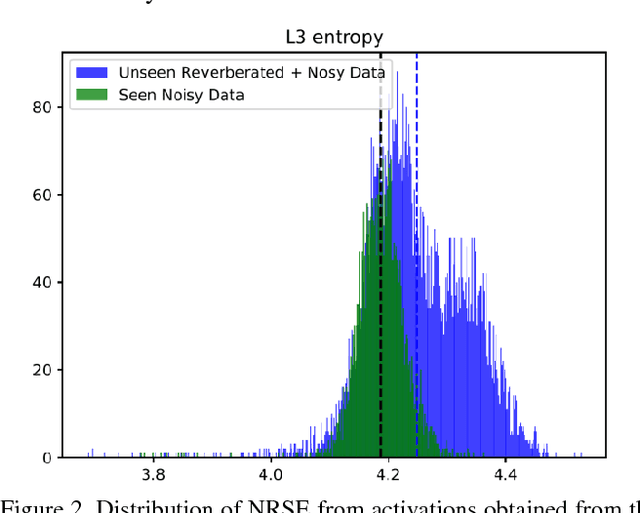
Unseen data conditions can inflict serious performance degradation on systems relying on supervised machine learning algorithms. Because data can often be unseen, and because traditional machine learning algorithms are trained in a supervised manner, unsupervised adaptation techniques must be used to adapt the model to the unseen data conditions. However, unsupervised adaptation is often challenging, as one must generate some hypothesis given a model and then use that hypothesis to bootstrap the model to the unseen data conditions. Unfortunately, reliability of such hypotheses is often poor, given the mismatch between the training and testing datasets. In such cases, a model hypothesis confidence measure enables performing data selection for the model adaptation. Underlying this approach is the fact that for unseen data conditions, data variability is introduced to the model, which the model propagates to its output decision, impacting decision reliability. In a fully connected network, this data variability is propagated as distortions from one layer to the next. This work aims to estimate the propagation of such distortion in the form of network activation entropy, which is measured over a short- time running window on the activation from each neuron of a given hidden layer, and these measurements are then used to compute summary entropy. This work demonstrates that such an entropy measure can help to select data for unsupervised model adaptation, resulting in performance gains in speech recognition tasks. Results from standard benchmark speech recognition tasks show that the proposed approach can alleviate the performance degradation experienced under unseen data conditions by iteratively adapting the model to the unseen datas acoustic condition.