 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Modeling for Automatic Lyrics-to-Audio Alignment
Paper and Code
Jun 25, 2019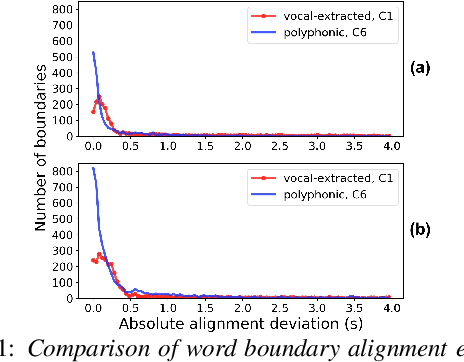



Automatic lyrics to polyphonic audio alignment is a challenging task not only because the vocals are corrupted by background music, but also there is a lack of annotated polyphonic corpus for effective acoustic modeling. In this work, we propose (1) using additional speech and music-informed features and (2) adapting the acoustic models trained on a large amount of solo singing vocals towards polyphonic music using a small amount of in-domain data. Incorporating additional information such as voicing and auditory features together with conventional acoustic features aims to bring robustness against the increased spectro-temporal variations in singing vocals. By adapting the acoustic model using a small amount of polyphonic audio data, we reduce the domain mismatch between training and testing data. We perform several alignment experiments and present an in-depth alignment error analysis on acoustic features, and model adaptation techniques. The results demonstrate that the proposed strategy provides a significant error reduction of word boundary alignment over comparable existing systems, especially on more challenging polyphonic data with long-duration musical interludes.