 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Speaker Diarization of Radio Broadcast Archives
Jun 28, 2019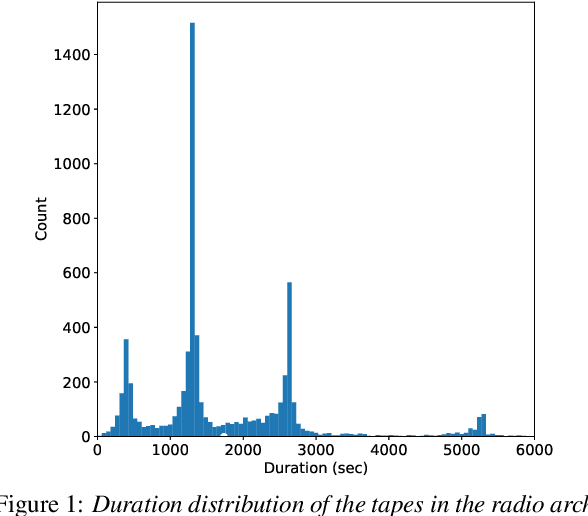
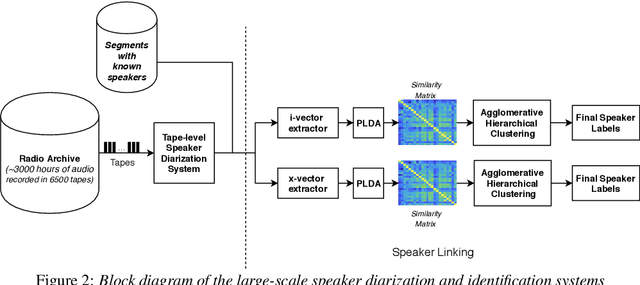

This paper describes our initial efforts to build a large-scale speaker diarization (SD) and identification system on a recently digitized radio broadcast archive from the Netherlands which has more than 6500 audio tapes with 3000 hours of Frisian-Dutch speech recorded between 1950-2016. The employed large-scale diarization scheme involves two stages: (1) tape-level speaker diarization providing pseudo-speaker identities and (2) speaker linking to relate pseudo-speakers appearing in multiple tapes. Having access to the speaker models of several frequently appearing speakers from the previously collected FAME! speech corpus, we further perform speaker identification by linking these known speakers to the pseudo-speakers identified at the first stage. In this work, we present a recently created longitudinal and multilingual SD corpus designed for large-scale SD research and evaluate the performance of a new speaker linking system using x-vectors with PLDA to quantify cross-tape speaker similarity on this corpus. The performance of this speaker linking system is evaluated on a small subset of the archive which is manually annotated with speaker information. The speaker linking performance reported on this subset (53 hours) and the whole archive (3000 hours) is compared to quantify the impact of scaling up in the amount of speech data.