 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Technology Services for Oral History Research
Apr 26, 2024


Oral history is about oral sources of witnesses and commentors on historical events. Speech technology is an important instrument to process such recordings in order to obtain transcription and further enhancements to structure the oral account In this contribution we address the transcription portal and the webservices associated with speech processing at BAS, speech solutions developed at LINDAT, how to do it yourself with Whisper, remaining challenges, and future developments.
Connecting Humanities and Social Sciences: Applying Language and Speech Technology to Online Panel Surveys
Feb 21, 2023



In this paper, we explore the application of language and speech technology to open-ended questions in a Dutch panel survey. In an experimental wave respondents could choose to answer open questions via speech or keyboard. Automatic speech recognition (ASR) was used to process spoken responses. We evaluated answers from these input modalities to investigate differences between spoken and typed answers.We report the errors the ASR system produces and investigate the impact of these errors on downstream analyses. Open-ended questions give more freedom to answer for respondents, but entail a non-trivial amount of work to analyse. We evaluated the feasibility of using transformer-based models (e.g. BERT) to apply sentiment analysis and topic modelling on the answers of open questions. A big advantage of transformer-based models is that they are trained on a large amount of language materials and do not necessarily need training on the target materials. This is especially advantageous for survey data, which does not contain a lot of text materials. We tested the quality of automatic sentiment analysis by comparing automatic labeling with three human raters and tested the robustness of topic modelling by comparing the generated models based on automatic and manually transcribed spoken answers.
Large-Scale Speaker Diarization of Radio Broadcast Archives
Jun 28, 2019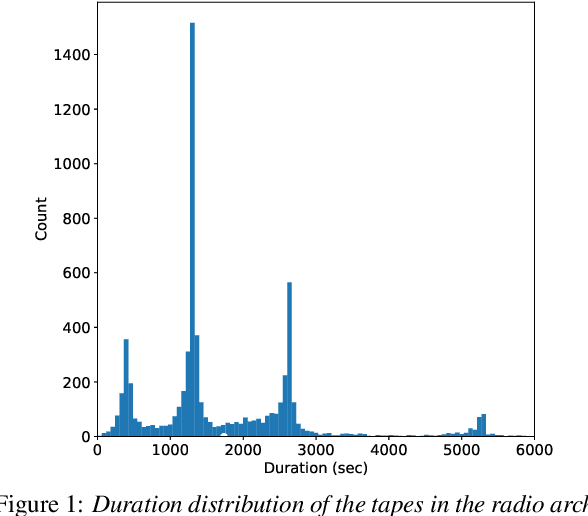
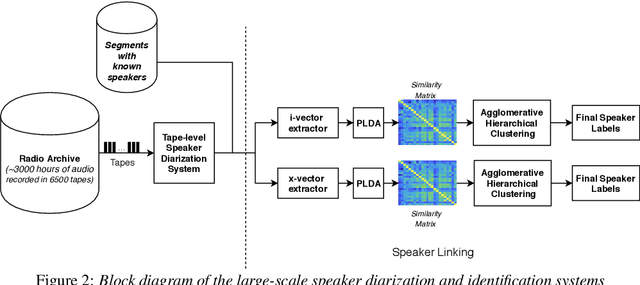

This paper describes our initial efforts to build a large-scale speaker diarization (SD) and identification system on a recently digitized radio broadcast archive from the Netherlands which has more than 6500 audio tapes with 3000 hours of Frisian-Dutch speech recorded between 1950-2016. The employed large-scale diarization scheme involves two stages: (1) tape-level speaker diarization providing pseudo-speaker identities and (2) speaker linking to relate pseudo-speakers appearing in multiple tapes. Having access to the speaker models of several frequently appearing speakers from the previously collected FAME! speech corpus, we further perform speaker identification by linking these known speakers to the pseudo-speakers identified at the first stage. In this work, we present a recently created longitudinal and multilingual SD corpus designed for large-scale SD research and evaluate the performance of a new speaker linking system using x-vectors with PLDA to quantify cross-tape speaker similarity on this corpus. The performance of this speaker linking system is evaluated on a small subset of the archive which is manually annotated with speaker information. The speaker linking performance reported on this subset (53 hours) and the whole archive (3000 hours) is compared to quantify the impact of scaling up in the amount of speech data.
Semi-supervised acoustic model training for speech with code-switching
Oct 23, 2018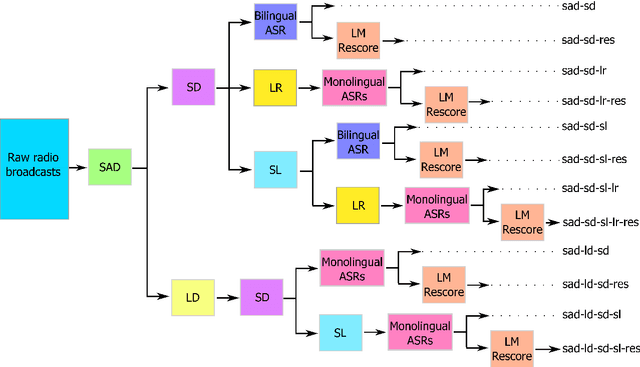
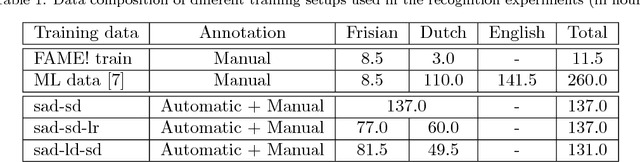

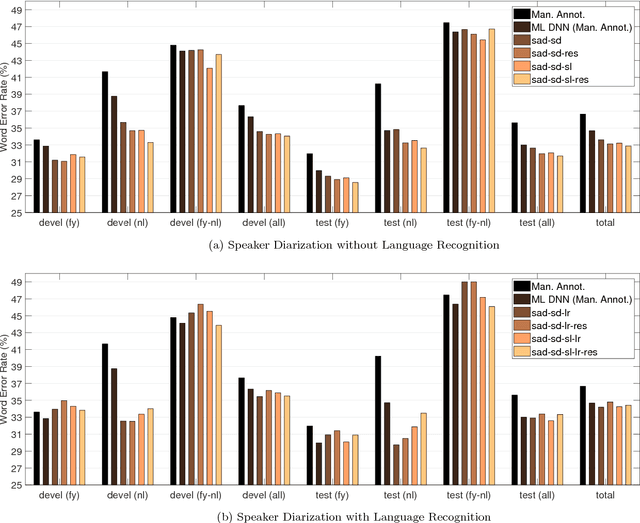
In the FAME! project, we aim to develop an automatic speech recognition (ASR) system for Frisian-Dutch code-switching (CS) speech extracted from the archives of a local broadcaster with the ultimate goal of building a spoken document retrieval system. Unlike Dutch, Frisian is a low-resourced language with a very limited amount of manually annotated speech data. In this paper, we describe several automatic annotation approaches to enable using of a large amount of raw bilingual broadcast data for acoustic model training in a semi-supervised setting. Previously, it has been shown that the best-performing ASR system is obtained by two-stage multilingual deep neural network (DNN) training using 11 hours of manually annotated CS speech (reference) data together with speech data from other high-resourced languages. We compare the quality of transcriptions provided by this bilingual ASR system with several other approaches that use a language recognition system for assigning language labels to raw speech segments at the front-end and using monolingual ASR resources for transcription. We further investigate automatic annotation of the speakers appearing in the raw broadcast data by first labeling with (pseudo) speaker tags using a speaker diarization system and then linking to the known speakers appearing in the reference data using a speaker recognition system. These speaker labels are essential for speaker-adaptive training in the proposed setting. We train acoustic models using the manually and automatically annotated data and run recognition experiments on the development and test data of the FAME! speech corpus to quantify the quality of the automatic annotations. The ASR and CS detection results demonstrate the potential of using automatic language and speaker tagging in semi-supervised bilingual acoustic model training.
Code-Switching Detection with Data-Augmented Acoustic and Language Models
Jul 28, 2018
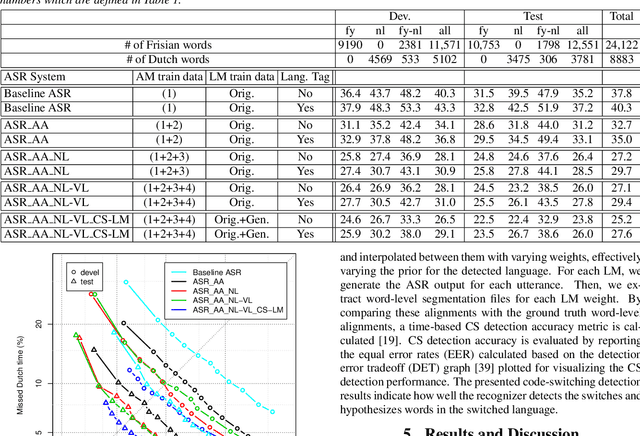
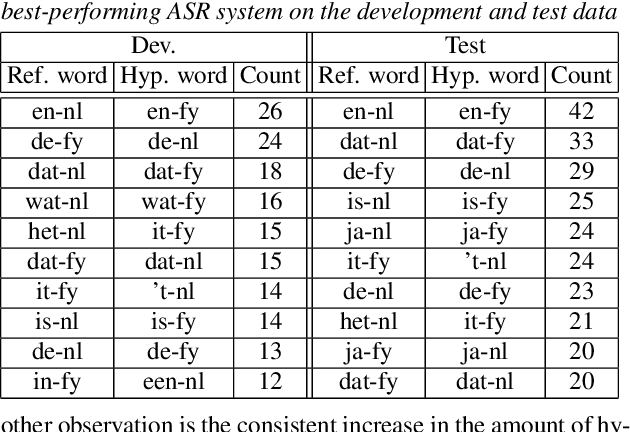

In this paper, we investigate the code-switching detection performance of a code-switching (CS) automatic speech recognition (ASR) system with data-augmented acoustic and language models. We focus on the recognition of Frisian-Dutch radio broadcasts where one of the mixed languages, namely Frisian, is under-resourced. Recently, we have explored how the acoustic modeling (AM) can benefit from monolingual speech data belonging to the high-resourced mixed language. For this purpose, we have trained state-of-the-art AMs on a significantly increased amount of CS speech by applying automatic transcription and monolingual Dutch speech. Moreover, we have improved the language model (LM) by creating CS text in various ways including text generation using recurrent LMs trained on existing CS text. Motivated by the significantly improved CS ASR performance, we delve into the CS detection performance of the same ASR system in this work by reporting CS detection accuracies together with a detailed detection error analysis.
Acoustic and Textual Data Augmentation for Improved ASR of Code-Switching Speech
Jul 28, 2018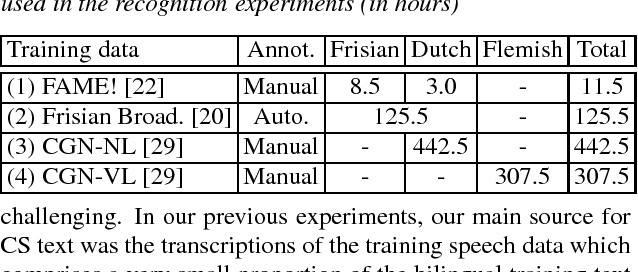
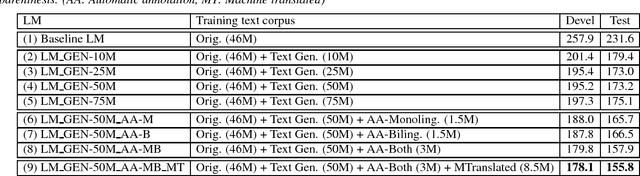
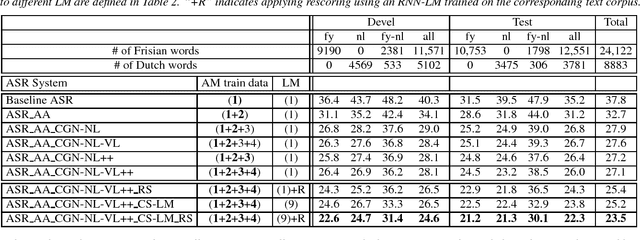
In this paper, we describe several techniques for improving the acoustic and language model of an automatic speech recognition (ASR) system operating on code-switching (CS) speech. We focus on the recognition of Frisian-Dutch radio broadcasts where one of the mixed languages, namely Frisian, is an under-resourced language. In previous work, we have proposed several automatic transcription strategies for CS speech to increase the amount of available training speech data. In this work, we explore how the acoustic modeling (AM) can benefit from monolingual speech data belonging to the high-resourced mixed language. For this purpose, we train state-of-the-art AMs, which were ineffective due to lack of training data, on a significantly increased amount of CS speech and monolingual Dutch speech. Moreover, we improve the language model (LM) by creating code-switching text, which is in practice almost non-existent, by (1) generating text using recurrent LMs trained on the transcriptions of the training CS speech data, (2) adding the transcriptions of the automatically transcribed CS speech data and (3) translating Dutch text extracted from the transcriptions of a large Dutch speech corpora. We report significantly improved CS ASR performance due to the increase in the acoustic and textual training data.