 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Speech Recognition of Non-Native Child Speech for Language Learning Applications
Jun 29, 2023
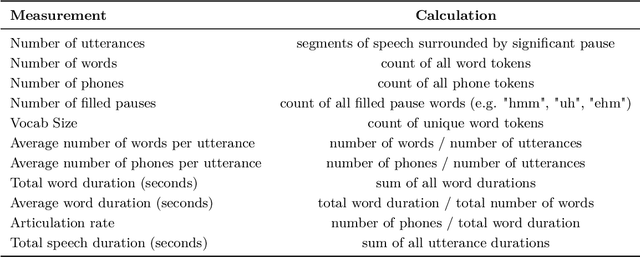
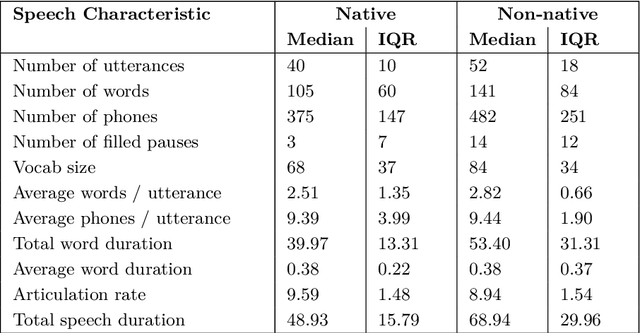
Voicebots have provided a new avenue for supporting the development of language skills, particularly within the context of second language learning. Voicebots, though, have largely been geared towards native adult speakers. We sought to assess the performance of two state-of-the-art ASR systems, Wav2Vec2.0 and Whisper AI, with a view to developing a voicebot that can support children acquiring a foreign language. We evaluated their performance on read and extemporaneous speech of native and non-native Dutch children. We also investigated the utility of using ASR technology to provide insight into the children's pronunciation and fluency. The results show that recent, pre-trained ASR transformer-based models achieve acceptable performance from which detailed feedback on phoneme pronunciation quality can be extracted, despite the challenging nature of child and non-native speech.
* Published on SLATE 2023, Esmad, Politecnico Do Porto, Portugal, 26-28 June, 2023, pp: 11:1-11:8
Alzheimer Disease Classification through ASR-based Transcriptions: Exploring the Impact of Punctuation and Pauses
Jun 06, 2023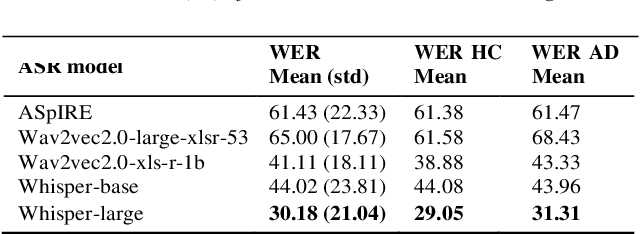
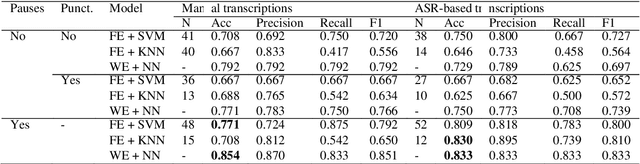
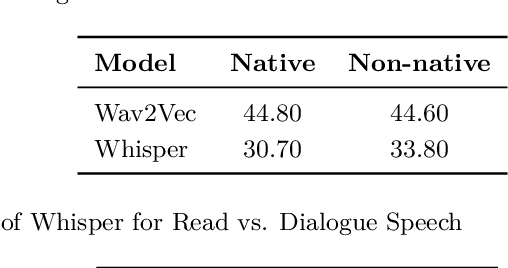
Alzheimer's Disease (AD) is the world's leading neurodegenerative disease, which often results in communication difficulties. Analysing speech can serve as a diagnostic tool for identifying the condition. The recent ADReSS challenge provided a dataset for AD classification and highlighted the utility of manual transcriptions. In this study, we used the new state-of-the-art Automatic Speech Recognition (ASR) model Whisper to obtain the transcriptions, which also include automatic punctuation. The classification models achieved test accuracy scores of 0.854 and 0.833 combining the pretrained FastText word embeddings and recurrent neural networks on manual and ASR transcripts respectively. Additionally, we explored the influence of including pause information and punctuation in the transcriptions. We found that punctuation only yielded minor improvements in some cases, whereas pause encoding aided AD classification for both manual and ASR transcriptions across all approaches investigated.
Connecting Humanities and Social Sciences: Applying Language and Speech Technology to Online Panel Surveys
Feb 21, 2023



In this paper, we explore the application of language and speech technology to open-ended questions in a Dutch panel survey. In an experimental wave respondents could choose to answer open questions via speech or keyboard. Automatic speech recognition (ASR) was used to process spoken responses. We evaluated answers from these input modalities to investigate differences between spoken and typed answers.We report the errors the ASR system produces and investigate the impact of these errors on downstream analyses. Open-ended questions give more freedom to answer for respondents, but entail a non-trivial amount of work to analyse. We evaluated the feasibility of using transformer-based models (e.g. BERT) to apply sentiment analysis and topic modelling on the answers of open questions. A big advantage of transformer-based models is that they are trained on a large amount of language materials and do not necessarily need training on the target materials. This is especially advantageous for survey data, which does not contain a lot of text materials. We tested the quality of automatic sentiment analysis by comparing automatic labeling with three human raters and tested the robustness of topic modelling by comparing the generated models based on automatic and manually transcribed spoken answers.