 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Finetuned SpeechLLM for Joint Multi-Granular L2 Assessment and Natural-Language Rationales
Jun 08, 2026Automated L2 speech assessment can assign proficiency labels, but often lacks interpretability. We propose a rubric-guided SpeechLLM for multi-aspect, multi-granular assessment, trained with a hybrid objective combining supervised fine-tuning and Bounded Direct Preference Optimization. The model jointly predicts ordinal labels at the sentence-level (accuracy, fluency, prosody), word/phoneme-level accuracy, and generates a natural-language rationale in the same response. On SpeechOcean762, our approach matches or outperforms single-granularity models while remaining competitive with prior approaches. We analyze rationale reliability along two axes: self-consistency with model predictions and alignment with ground-truth labels, using sentiment consistency (plausibility) and mention-based agreement (faithfulness). Rationales are plausible at the sentence level, but faithfulness degrades at the word/phoneme level: references are sparse and weakly aligned with token-level labels.
A Benchmark for Early-stage Parkinson's Disease Detection from Speech
May 13, 2026Early-stage Parkinson's disease (EarlyPD) detection from speech is clinically meaningful yet underexplored, and published results are hard to compare because studies differ in datasets, languages, tasks, evaluation protocols, and EarlyPD definitions. To address this issue, we propose the first benchmark for speech-based EarlyPD detection, with a speaker-independent split designed for fair and replicable cross-method evaluation on researcher-accessible datasets. The benchmark covers three common speech tasks and evaluates methods under different training-resource settings. We also present multi-dimensional evaluation breakdowns by dataset, aggregation level, gender, and disease stage to support fine-grained comparisons and clinical adoption. Our results provide a replicable reference and actionable insights, encouraging the adoption of this publicly available benchmark to advance robust and clinically meaningful EarlyPD detection from speech.
Zero-Shot Speech LLMs for Multi-Aspect Evaluation of L2 Speech: Challenges and Opportunities
Jan 20, 2026An accurate assessment of L2 English pronunciation is crucial for language learning, as it provides personalized feedback and ensures a fair evaluation of individual progress. However, automated scoring remains challenging due to the complexity of sentence-level fluency, prosody, and completeness. This paper evaluates the zero-shot performance of Qwen2-Audio-7B-Instruct, an instruction-tuned speech-LLM, on 5,000 Speechocean762 utterances. The model generates rubric-aligned scores for accuracy, fluency, prosody, and completeness, showing strong agreement with human ratings within +-2 tolerance, especially for high-quality speech. However, it tends to overpredict low-quality speech scores and lacks precision in error detection. These findings demonstrate the strong potential of speech LLMs in scalable pronunciation assessment and suggest future improvements through enhanced prompting, calibration, and phonetic integration to advance Computer-Assisted Pronunciation Training.
* This publication is part of the project Responsible AI for Voice Diagnostics (RAIVD) with file number NGF.1607.22.013 of the research programme NGF AiNed Fellowship Grants which is financed by the Dutch Research Council (NWO)
Evaluating the Usefulness of Non-Diagnostic Speech Data for Developing Parkinson's Disease Classifiers
May 24, 2025



Speech-based Parkinson's disease (PD) detection has gained attention for its automated, cost-effective, and non-intrusive nature. As research studies usually rely on data from diagnostic-oriented speech tasks, this work explores the feasibility of diagnosing PD on the basis of speech data not originally intended for diagnostic purposes, using the Turn-Taking (TT) dataset. Our findings indicate that TT can be as useful as diagnostic-oriented PD datasets like PC-GITA. We also investigate which specific dataset characteristics impact PD classification performance. The results show that concatenating audio recordings and balancing participants' gender and status distributions can be beneficial. Cross-dataset evaluation reveals that models trained on PC-GITA generalize poorly to TT, whereas models trained on TT perform better on PC-GITA. Furthermore, we provide insights into the high variability across folds, which is mainly due to large differences in individual speaker performance.
Reading Miscue Detection in Primary School through Automatic Speech Recognition
Jun 11, 2024



Automatic reading diagnosis systems can benefit both teachers for more efficient scoring of reading exercises and students for accessing reading exercises with feedback more easily. However, there are limited studies on Automatic Speech Recognition (ASR) for child speech in languages other than English, and limited research on ASR-based reading diagnosis systems. This study investigates how efficiently state-of-the-art (SOTA) pretrained ASR models recognize Dutch native children speech and manage to detect reading miscues. We found that Hubert Large finetuned on Dutch speech achieves SOTA phoneme-level child speech recognition (PER at 23.1\%), while Whisper (Faster Whisper Large-v2) achieves SOTA word-level performance (WER at 9.8\%). Our findings suggest that Wav2Vec2 Large and Whisper are the two best ASR models for reading miscue detection. Specifically, Wav2Vec2 Large shows the highest recall at 0.83, whereas Whisper exhibits the highest precision at 0.52 and an F1 score of 0.52.
Automatic Speech Recognition of Non-Native Child Speech for Language Learning Applications
Jun 29, 2023
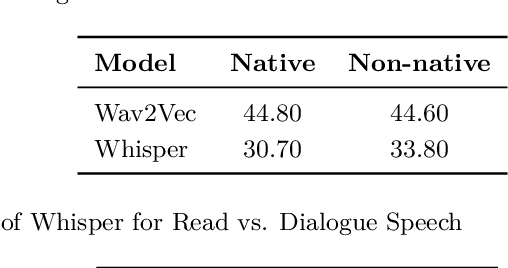
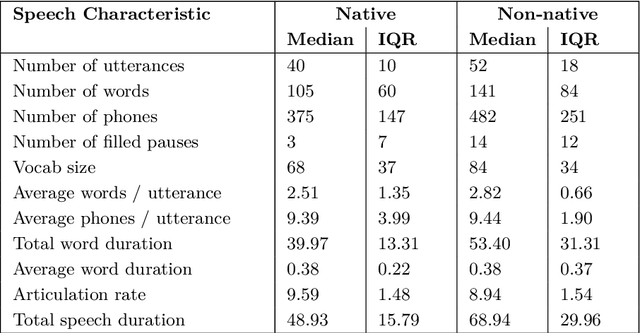
Voicebots have provided a new avenue for supporting the development of language skills, particularly within the context of second language learning. Voicebots, though, have largely been geared towards native adult speakers. We sought to assess the performance of two state-of-the-art ASR systems, Wav2Vec2.0 and Whisper AI, with a view to developing a voicebot that can support children acquiring a foreign language. We evaluated their performance on read and extemporaneous speech of native and non-native Dutch children. We also investigated the utility of using ASR technology to provide insight into the children's pronunciation and fluency. The results show that recent, pre-trained ASR transformer-based models achieve acceptable performance from which detailed feedback on phoneme pronunciation quality can be extracted, despite the challenging nature of child and non-native speech.
* Published on SLATE 2023, Esmad, Politecnico Do Porto, Portugal, 26-28 June, 2023, pp: 11:1-11:8
An ASR-Based Tutor for Learning to Read: How to Optimize Feedback to First Graders
Jun 07, 2023The interest in employing automatic speech recognition (ASR) in applications for reading practice has been growing in recent years. In a previous study, we presented an ASR-based Dutch reading tutor application that was developed to provide instantaneous feedback to first-graders learning to read. We saw that ASR has potential at this stage of the reading process, as the results suggested that pupils made progress in reading accuracy and fluency by using the software. In the current study, we used children's speech from an existing corpus (JASMIN) to develop two new ASR systems, and compared the results to those of the previous study. We analyze correct/incorrect classification of the ASR systems using human transcripts at word level, by means of evaluation measures such as Cohen's Kappa, Matthews Correlation Coefficient (MCC), precision, recall and F-measures. We observe improvements for the newly developed ASR systems regarding the agreement with human-based judgment and correct rejection (CR). The accuracy of the ASR systems varies for different reading tasks and word types. Our results suggest that, in the current configuration, it is difficult to classify isolated words. We discuss these results, possible ways to improve our systems and avenues for future research.
* Published (double-blind peer-reviewed) on SPECOM 2021
Automatic Assessment of Oral Reading Accuracy for Reading Diagnostics
Jun 06, 2023



Automatic assessment of reading fluency using automatic speech recognition (ASR) holds great potential for early detection of reading difficulties and subsequent timely intervention. Precise assessment tools are required, especially for languages other than English. In this study, we evaluate six state-of-the-art ASR-based systems for automatically assessing Dutch oral reading accuracy using Kaldi and Whisper. Results show our most successful system reached substantial agreement with human evaluations (MCC = .63). The same system reached the highest correlation between forced decoding confidence scores and word correctness (r = .45). This system's language model (LM) consisted of manual orthographic transcriptions and reading prompts of the test data, which shows that including reading errors in the LM improves assessment performance. We discuss the implications for developing automatic assessment systems and identify possible avenues of future research.
Alzheimer Disease Classification through ASR-based Transcriptions: Exploring the Impact of Punctuation and Pauses
Jun 06, 2023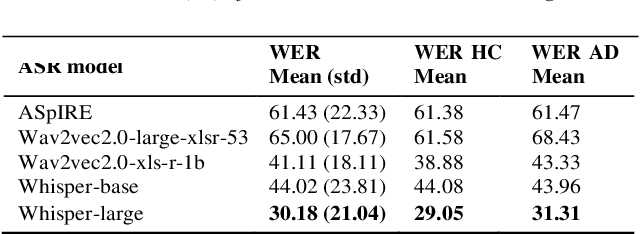
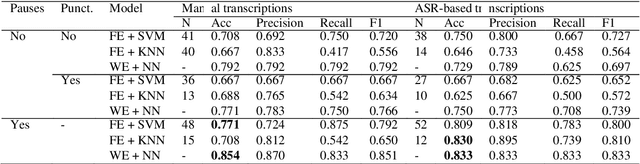
Alzheimer's Disease (AD) is the world's leading neurodegenerative disease, which often results in communication difficulties. Analysing speech can serve as a diagnostic tool for identifying the condition. The recent ADReSS challenge provided a dataset for AD classification and highlighted the utility of manual transcriptions. In this study, we used the new state-of-the-art Automatic Speech Recognition (ASR) model Whisper to obtain the transcriptions, which also include automatic punctuation. The classification models achieved test accuracy scores of 0.854 and 0.833 combining the pretrained FastText word embeddings and recurrent neural networks on manual and ASR transcripts respectively. Additionally, we explored the influence of including pause information and punctuation in the transcriptions. We found that punctuation only yielded minor improvements in some cases, whereas pause encoding aided AD classification for both manual and ASR transcriptions across all approaches investigated.