 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech emotion recognition from voice messages recorded in the wild
Mar 04, 2024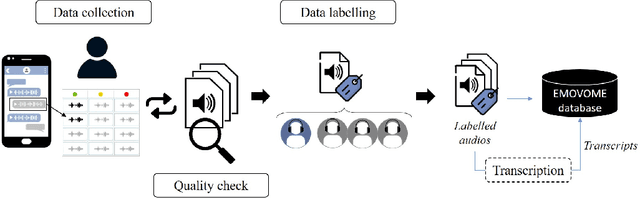

Emotion datasets used for Speech Emotion Recognition (SER) often contain acted or elicited speech, limiting their applicability in real-world scenarios. In this work, we used the Emotional Voice Messages (EMOVOME) database, including spontaneous voice messages from conversations of 100 Spanish speakers on a messaging app, labeled in continuous and discrete emotions by expert and non-expert annotators. We created speaker-independent SER models using the eGeMAPS features, transformer-based models and their combination. We compared the results with reference databases and analyzed the influence of annotators and gender fairness. The pre-trained Unispeech-L model and its combination with eGeMAPS achieved the highest results, with 61.64% and 55.57% Unweighted Accuracy (UA) for 3-class valence and arousal prediction respectively, a 10% improvement over baseline models. For the emotion categories, 42.58% UA was obtained. EMOVOME performed lower than the acted RAVDESS database. The elicited IEMOCAP database also outperformed EMOVOME in the prediction of emotion categories, while similar results were obtained in valence and arousal. Additionally, EMOVOME outcomes varied with annotator labels, showing superior results and better fairness when combining expert and non-expert annotations. This study significantly contributes to the evaluation of SER models in real-life situations, advancing in the development of applications for analyzing spontaneous voice messages.
Emotional Voice Messages (EMOVOME) database: emotion recognition in spontaneous voice messages
Feb 27, 2024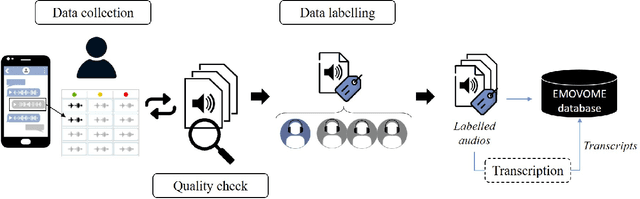



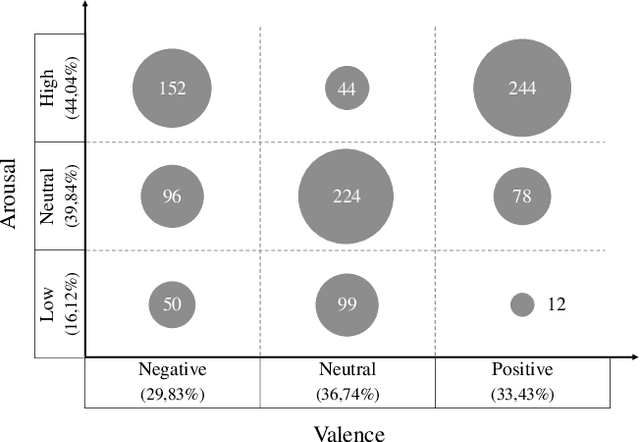
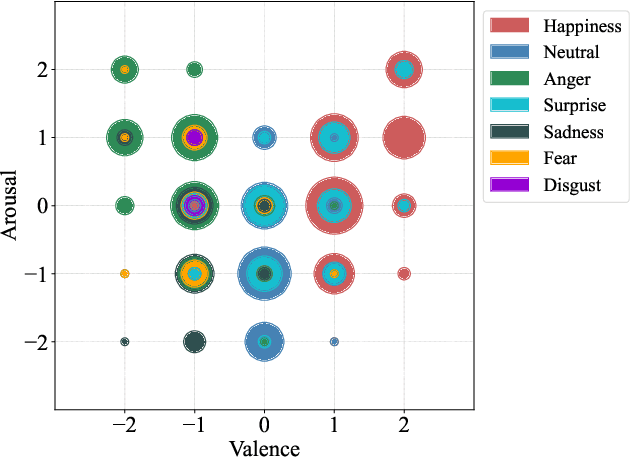
Emotional Voice Messages (EMOVOME) is a spontaneous speech dataset containing 999 audio messages from real conversations on a messaging app from 100 Spanish speakers, gender balanced. Voice messages were produced in-the-wild conditions before participants were recruited, avoiding any conscious bias due to laboratory environment. Audios were labeled in valence and arousal dimensions by three non-experts and two experts, which were then combined to obtain a final label per dimension. The experts also provided an extra label corresponding to seven emotion categories. To set a baseline for future investigations using EMOVOME, we implemented emotion recognition models using both speech and audio transcriptions. For speech, we used the standard eGeMAPS feature set and support vector machines, obtaining 49.27% and 44.71% unweighted accuracy for valence and arousal respectively. For text, we fine-tuned a multilingual BERT model and achieved 61.15% and 47.43% unweighted accuracy for valence and arousal respectively. This database will significantly contribute to research on emotion recognition in the wild, while also providing a unique natural and freely accessible resource for Spanish.
Comparing Feature Engineering and End-to-End Deep Learning for Autism Spectrum Disorder Assessment based on Fullbody-Tracking
Nov 24, 2023Autism Spectrum Disorder (ASD) is characterized by challenges in social communication and restricted patterns, with motor abnormalities gaining traction for early detection. However, kinematic analysis in ASD is limited, often lacking robust validation and relying on hand-crafted features for single tasks, leading to inconsistencies across studies. Thus, end-to-end models have become promising methods to overcome the need for feature engineering. Our aim is to assess both approaches across various kinematic tasks to measure the efficacy of commonly used features in ASD assessment, while comparing them to end-to-end models. Specifically, we developed a virtual reality environment with multiple motor tasks and trained models using both classification approaches. We prioritized a reliable validation framework with repeated cross-validation. Our comparative analysis revealed that hand-crafted features outperformed our deep learning approach in specific tasks, achieving a state-of-the-art area under the curve (AUC) of 0.90$\pm$0.06. Conversely, end-to-end models provided more consistent results with less variability across all VR tasks, demonstrating domain generalization and reliability, with a maximum task AUC of 0.89$\pm$0.06. These findings show that end-to-end models enable less variable and context-independent ASD assessments without requiring domain knowledge or task specificity. However, they also recognize the effectiveness of hand-crafted features in specific task scenarios.
Alzheimer Disease Classification through ASR-based Transcriptions: Exploring the Impact of Punctuation and Pauses
Jun 06, 2023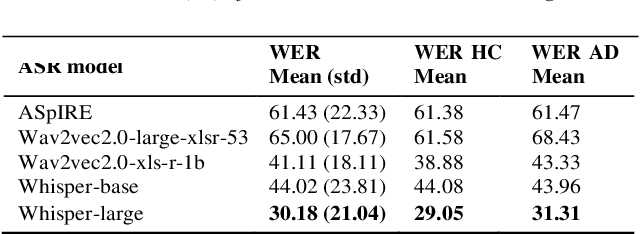
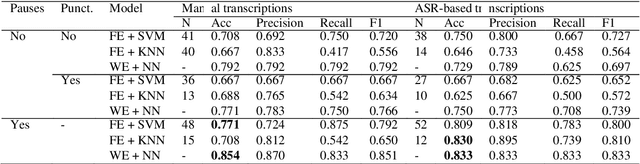
Alzheimer's Disease (AD) is the world's leading neurodegenerative disease, which often results in communication difficulties. Analysing speech can serve as a diagnostic tool for identifying the condition. The recent ADReSS challenge provided a dataset for AD classification and highlighted the utility of manual transcriptions. In this study, we used the new state-of-the-art Automatic Speech Recognition (ASR) model Whisper to obtain the transcriptions, which also include automatic punctuation. The classification models achieved test accuracy scores of 0.854 and 0.833 combining the pretrained FastText word embeddings and recurrent neural networks on manual and ASR transcripts respectively. Additionally, we explored the influence of including pause information and punctuation in the transcriptions. We found that punctuation only yielded minor improvements in some cases, whereas pause encoding aided AD classification for both manual and ASR transcriptions across all approaches investigated.