 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring visual language models as a powerful tool in the diagnosis of Ewing Sarcoma
Jan 14, 2025



Ewing's sarcoma (ES), characterized by a high density of small round blue cells without structural organization, presents a significant health concern, particularly among adolescents aged 10 to 19. Artificial intelligence-based systems for automated analysis of histopathological images are promising to contribute to an accurate diagnosis of ES. In this context, this study explores the feature extraction ability of different pre-training strategies for distinguishing ES from other soft tissue or bone sarcomas with similar morphology in digitized tissue microarrays for the first time, as far as we know. Vision-language supervision (VLS) is compared to fully-supervised ImageNet pre-training within a multiple instance learning paradigm. Our findings indicate a substantial improvement in diagnostic accuracy with the adaption of VLS using an in-domain dataset. Notably, these models not only enhance the accuracy of predicted classes but also drastically reduce the number of trainable parameters and computational costs.
Enhancing Whole Slide Image Classification through Supervised Contrastive Domain Adaptation
Dec 05, 2024



Domain shift in the field of histopathological imaging is a common phenomenon due to the intra- and inter-hospital variability of staining and digitization protocols. The implementation of robust models, capable of creating generalized domains, represents a need to be solved. In this work, a new domain adaptation method to deal with the variability between histopathological images from multiple centers is presented. In particular, our method adds a training constraint to the supervised contrastive learning approach to achieve domain adaptation and improve inter-class separability. Experiments performed on domain adaptation and classification of whole-slide images of six skin cancer subtypes from two centers demonstrate the method's usefulness. The results reflect superior performance compared to not using domain adaptation after feature extraction or staining normalization.
MI-VisionShot: Few-shot adaptation of vision-language models for slide-level classification of histopathological images
Oct 21, 2024



Vision-language supervision has made remarkable strides in learning visual representations from textual guidance. In digital pathology, vision-language models (VLM), pre-trained on curated datasets of histological image-captions, have been adapted to downstream tasks, such as region of interest classification. Zero-shot transfer for slide-level prediction has been formulated by MI-Zero, but it exhibits high variability depending on the textual prompts. Inspired by prototypical learning, we propose MI-VisionShot, a training-free adaptation method on top of VLMs to predict slide-level labels in few-shot learning scenarios. Our framework takes advantage of the excellent representation learning of VLM to create prototype-based classifiers under a multiple-instance setting by retrieving the most discriminative patches within each slide. Experimentation through different settings shows the ability of MI-VisionShot to surpass zero-shot transfer with lower variability, even in low-shot scenarios. Code coming soon at thttps://github.com/cvblab/MIVisionShot.
Foundation Models for Slide-level Cancer Subtyping in Digital Pathology
Oct 21, 2024



Since the emergence of the ImageNet dataset, the pretraining and fine-tuning approach has become widely adopted in computer vision due to the ability of ImageNet-pretrained models to learn a wide variety of visual features. However, a significant challenge arises when adapting these models to domain-specific fields, such as digital pathology, due to substantial gaps between domains. To address this limitation, foundation models (FM) have been trained on large-scale in-domain datasets to learn the intricate features of histopathology images. In cancer diagnosis, whole-slide image (WSI) prediction is essential for patient prognosis, and multiple instance learning (MIL) has been implemented to handle the giga-pixel size of WSI. As MIL frameworks rely on patch-level feature aggregation, this work aims to compare the performance of various feature extractors developed under different pretraining strategies for cancer subtyping on WSI under a MIL framework. Results demonstrate the ability of foundation models to surpass ImageNet-pretrained models for the prediction of six skin cancer subtypes
Speech emotion recognition from voice messages recorded in the wild
Mar 04, 2024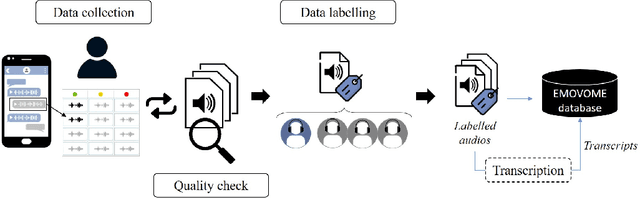

Emotion datasets used for Speech Emotion Recognition (SER) often contain acted or elicited speech, limiting their applicability in real-world scenarios. In this work, we used the Emotional Voice Messages (EMOVOME) database, including spontaneous voice messages from conversations of 100 Spanish speakers on a messaging app, labeled in continuous and discrete emotions by expert and non-expert annotators. We created speaker-independent SER models using the eGeMAPS features, transformer-based models and their combination. We compared the results with reference databases and analyzed the influence of annotators and gender fairness. The pre-trained Unispeech-L model and its combination with eGeMAPS achieved the highest results, with 61.64% and 55.57% Unweighted Accuracy (UA) for 3-class valence and arousal prediction respectively, a 10% improvement over baseline models. For the emotion categories, 42.58% UA was obtained. EMOVOME performed lower than the acted RAVDESS database. The elicited IEMOCAP database also outperformed EMOVOME in the prediction of emotion categories, while similar results were obtained in valence and arousal. Additionally, EMOVOME outcomes varied with annotator labels, showing superior results and better fairness when combining expert and non-expert annotations. This study significantly contributes to the evaluation of SER models in real-life situations, advancing in the development of applications for analyzing spontaneous voice messages.
Emotional Voice Messages (EMOVOME) database: emotion recognition in spontaneous voice messages
Feb 27, 2024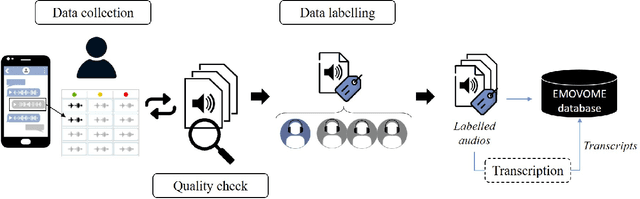



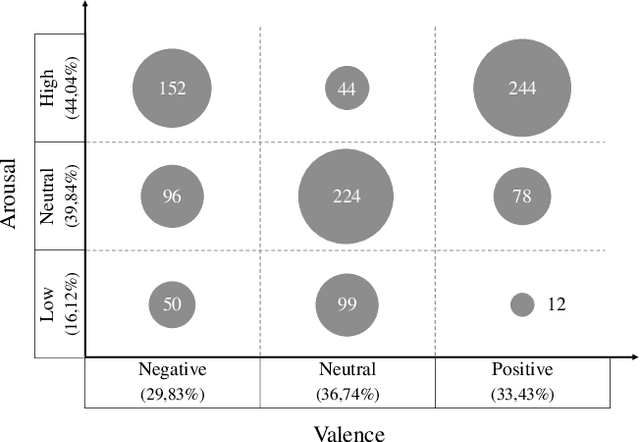
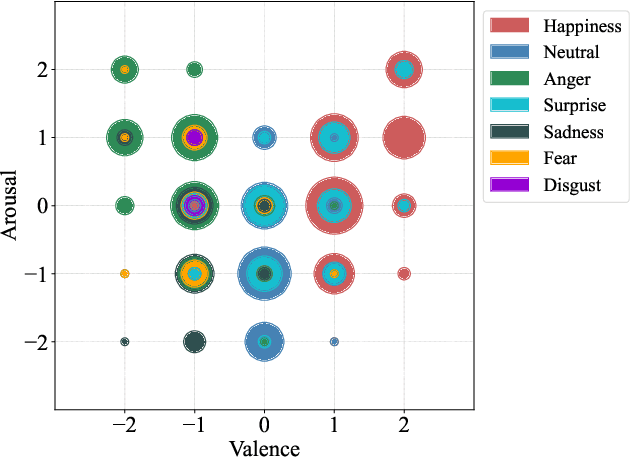
Emotional Voice Messages (EMOVOME) is a spontaneous speech dataset containing 999 audio messages from real conversations on a messaging app from 100 Spanish speakers, gender balanced. Voice messages were produced in-the-wild conditions before participants were recruited, avoiding any conscious bias due to laboratory environment. Audios were labeled in valence and arousal dimensions by three non-experts and two experts, which were then combined to obtain a final label per dimension. The experts also provided an extra label corresponding to seven emotion categories. To set a baseline for future investigations using EMOVOME, we implemented emotion recognition models using both speech and audio transcriptions. For speech, we used the standard eGeMAPS feature set and support vector machines, obtaining 49.27% and 44.71% unweighted accuracy for valence and arousal respectively. For text, we fine-tuned a multilingual BERT model and achieved 61.15% and 47.43% unweighted accuracy for valence and arousal respectively. This database will significantly contribute to research on emotion recognition in the wild, while also providing a unique natural and freely accessible resource for Spanish.
Attention to detail: inter-resolution knowledge distillation
Jan 11, 2024The development of computer vision solutions for gigapixel images in digital pathology is hampered by significant computational limitations due to the large size of whole slide images. In particular, digitizing biopsies at high resolutions is a time-consuming process, which is necessary due to the worsening results from the decrease in image detail. To alleviate this issue, recent literature has proposed using knowledge distillation to enhance the model performance at reduced image resolutions. In particular, soft labels and features extracted at the highest magnification level are distilled into a model that takes lower-magnification images as input. However, this approach fails to transfer knowledge about the most discriminative image regions in the classification process, which may be lost when the resolution is decreased. In this work, we propose to distill this information by incorporating attention maps during training. In particular, our formulation leverages saliency maps of the target class via grad-CAMs, which guides the lower-resolution Student model to match the Teacher distribution by minimizing the l2 distance between them. Comprehensive experiments on prostate histology image grading demonstrate that the proposed approach substantially improves the model performance across different image resolutions compared to previous literature.
HistoColAi: An Open-Source Web Platform for Collaborative Digital Histology Image Annotation with AI-Driven Predictive Integration
Jul 11, 2023



Digital pathology has become a standard in the pathology workflow due to its many benefits. These include the level of detail of the whole slide images generated and the potential immediate sharing of cases between hospitals. Recent advances in deep learning-based methods for image analysis make them of potential aid in digital pathology. However, a major limitation in developing computer-aided diagnostic systems for pathology is the lack of an intuitive and open web application for data annotation. This paper proposes a web service that efficiently provides a tool to visualize and annotate digitized histological images. In addition, to show and validate the tool, in this paper we include a use case centered on the diagnosis of spindle cell skin neoplasm for multiple annotators. A usability study of the tool is also presented, showing the feasibility of the developed tool.
Circumpapillary OCT-Focused Hybrid Learning for Glaucoma Grading Using Tailored Prototypical Neural Networks
Jun 25, 2021

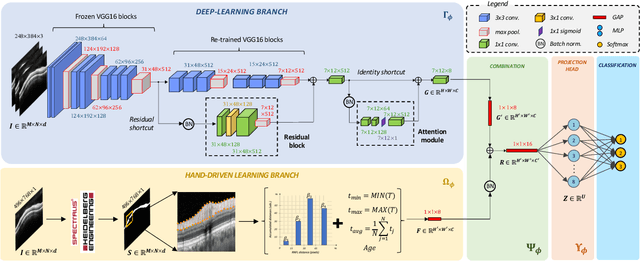

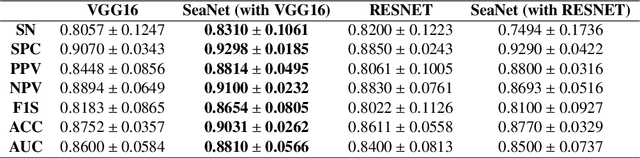
Glaucoma is one of the leading causes of blindness worldwide and Optical Coherence Tomography (OCT) is the quintessential imaging technique for its detection. Unlike most of the state-of-the-art studies focused on glaucoma detection, in this paper, we propose, for the first time, a novel framework for glaucoma grading using raw circumpapillary B-scans. In particular, we set out a new OCT-based hybrid network which combines hand-driven and deep learning algorithms. An OCT-specific descriptor is proposed to extract hand-crafted features related to the retinal nerve fibre layer (RNFL). In parallel, an innovative CNN is developed using skip-connections to include tailored residual and attention modules to refine the automatic features of the latent space. The proposed architecture is used as a backbone to conduct a novel few-shot learning based on static and dynamic prototypical networks. The k-shot paradigm is redefined giving rise to a supervised end-to-end system which provides substantial improvements discriminating between healthy, early and advanced glaucoma samples. The training and evaluation processes of the dynamic prototypical network are addressed from two fused databases acquired via Heidelberg Spectralis system. Validation and testing results reach a categorical accuracy of 0.9459 and 0.8788 for glaucoma grading, respectively. Besides, the high performance reported by the proposed model for glaucoma detection deserves a special mention. The findings from the class activation maps are directly in line with the clinicians' opinion since the heatmaps pointed out the RNFL as the most relevant structure for glaucoma diagnosis.
An Attention-based Weakly Supervised framework for Spitzoid Melanocytic Lesion Diagnosis in WSI
Apr 20, 2021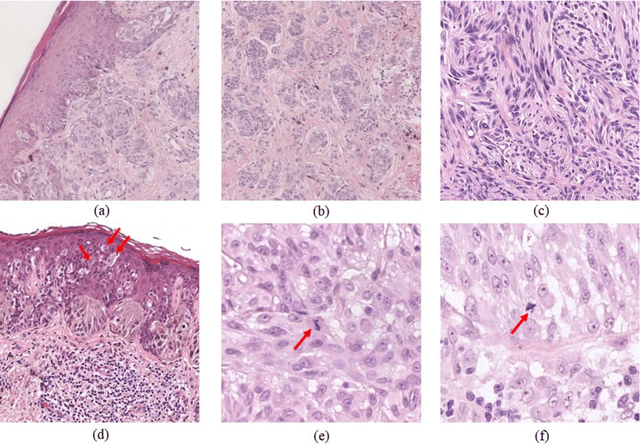

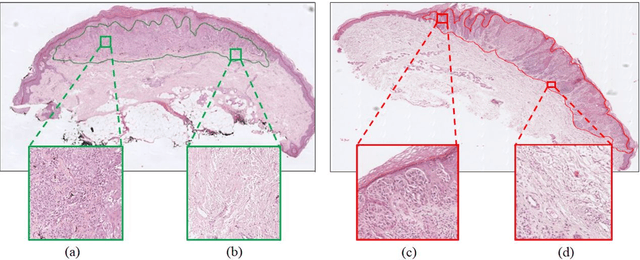
Melanoma is an aggressive neoplasm responsible for the majority of deaths from skin cancer. Specifically, spitzoid melanocytic tumors are one of the most challenging melanocytic lesions due to their ambiguous morphological features. The gold standard for its diagnosis and prognosis is the analysis of skin biopsies. In this process, dermatopathologists visualize skin histology slides under a microscope, in a high time-consuming and subjective task. In the last years, computer-aided diagnosis (CAD) systems have emerged as a promising tool that could support pathologists in daily clinical practice. Nevertheless, no automatic CAD systems have yet been proposed for the analysis of spitzoid lesions. Regarding common melanoma, no proposed system allows both the selection of the tumoral region and the prediction of the diagnosis as benign or malignant. Motivated by this, we propose a novel end-to-end weakly-supervised deep learning model, based on inductive transfer learning with an improved convolutional neural network (CNN) to refine the embedding features of the latent space. The framework is composed of a source model in charge of finding the tumor patch-level patterns, and a target model focuses on the specific diagnosis of a biopsy. The latter retrains the backbone of the source model through a multiple instance learning workflow to obtain the biopsy-level scoring. To evaluate the performance of the proposed methods, we perform extensive experiments on a private skin database with spitzoid lesions. Test results reach an accuracy of 0.9231 and 0.80 for the source and the target models, respectively. Besides, the heat map findings are directly in line with the clinicians' medical decision and even highlight, in some cases, patterns of interest that were overlooked by the pathologist due to the huge workload.