 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Bilingual and Trilingual Wav2Vec Models for Automatic Speech Recognition in Multilingual Oral History Archives
Jul 24, 2024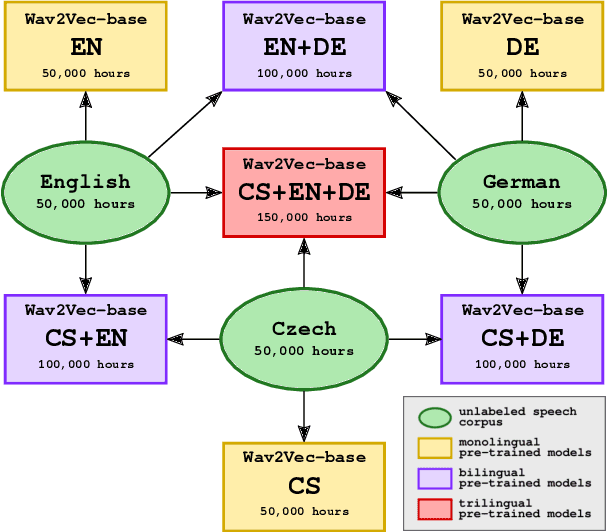
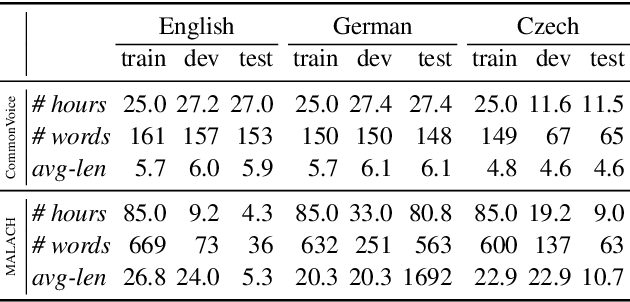
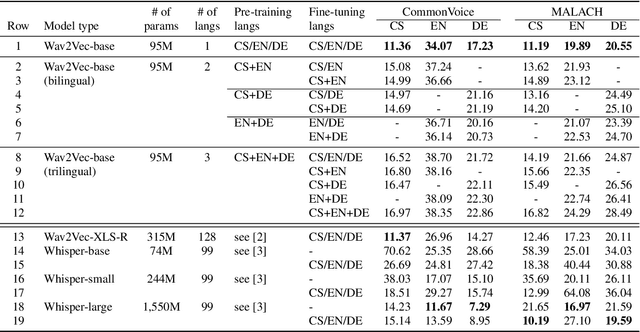
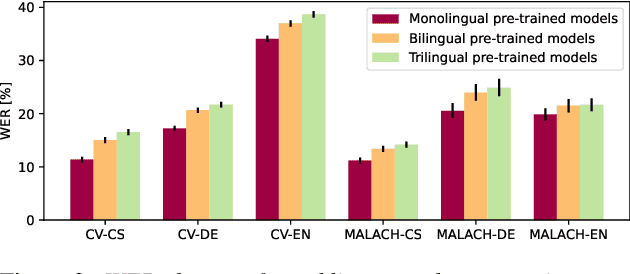
In this paper, we are comparing monolingual Wav2Vec 2.0 models with various multilingual models to see whether we could improve speech recognition performance on a unique oral history archive containing a lot of mixed-language sentences. Our main goal is to push forward research on this unique dataset, which is an extremely valuable part of our cultural heritage. Our results suggest that monolingual speech recognition models are, in most cases, superior to multilingual models, even when processing the oral history archive full of mixed-language sentences from non-native speakers. We also performed the same experiments on the public CommonVoice dataset to verify our results. We are contributing to the research community by releasing our pre-trained models to the public.
Speech Technology Services for Oral History Research
Apr 26, 2024


Oral history is about oral sources of witnesses and commentors on historical events. Speech technology is an important instrument to process such recordings in order to obtain transcription and further enhancements to structure the oral account In this contribution we address the transcription portal and the webservices associated with speech processing at BAS, speech solutions developed at LINDAT, how to do it yourself with Whisper, remaining challenges, and future developments.