 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Bilingual and Trilingual Wav2Vec Models for Automatic Speech Recognition in Multilingual Oral History Archives
Jul 24, 2024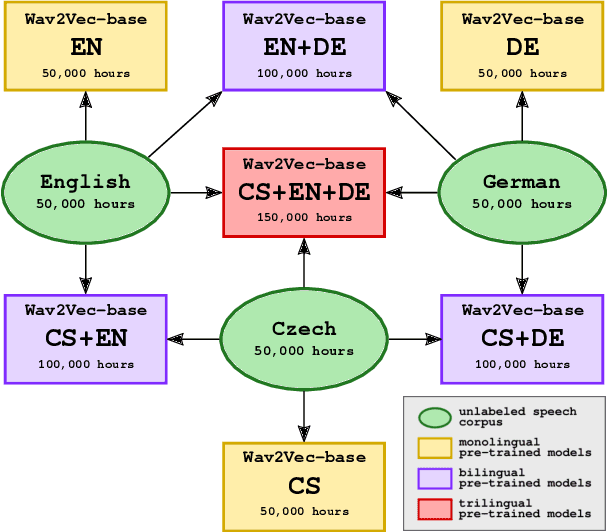
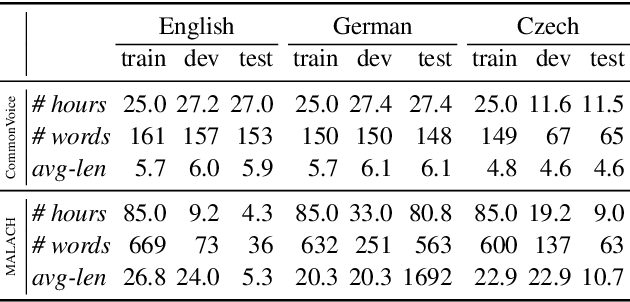
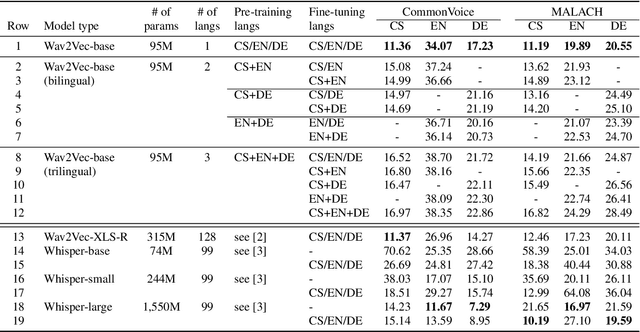
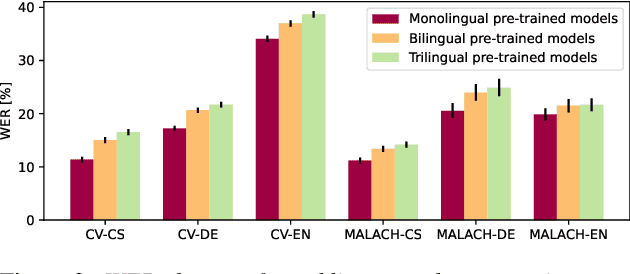
In this paper, we are comparing monolingual Wav2Vec 2.0 models with various multilingual models to see whether we could improve speech recognition performance on a unique oral history archive containing a lot of mixed-language sentences. Our main goal is to push forward research on this unique dataset, which is an extremely valuable part of our cultural heritage. Our results suggest that monolingual speech recognition models are, in most cases, superior to multilingual models, even when processing the oral history archive full of mixed-language sentences from non-native speakers. We also performed the same experiments on the public CommonVoice dataset to verify our results. We are contributing to the research community by releasing our pre-trained models to the public.
Transfer Learning of Transformer-based Speech Recognition Models from Czech to Slovak
Jun 07, 2023In this paper, we are comparing several methods of training the Slovak speech recognition models based on the Transformers architecture. Specifically, we are exploring the approach of transfer learning from the existing Czech pre-trained Wav2Vec 2.0 model into Slovak. We are demonstrating the benefits of the proposed approach on three Slovak datasets. Our Slovak models scored the best results when initializing the weights from the Czech model at the beginning of the pre-training phase. Our results show that the knowledge stored in the Cezch pre-trained model can be successfully reused to solve tasks in Slovak while outperforming even much larger public multilingual models.
Transformer-based Automatic Speech Recognition of Formal and Colloquial Czech in MALACH Project
Jun 15, 2022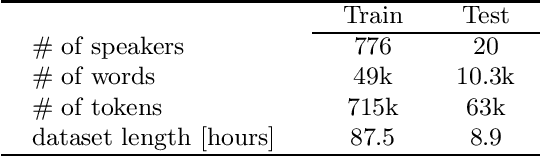
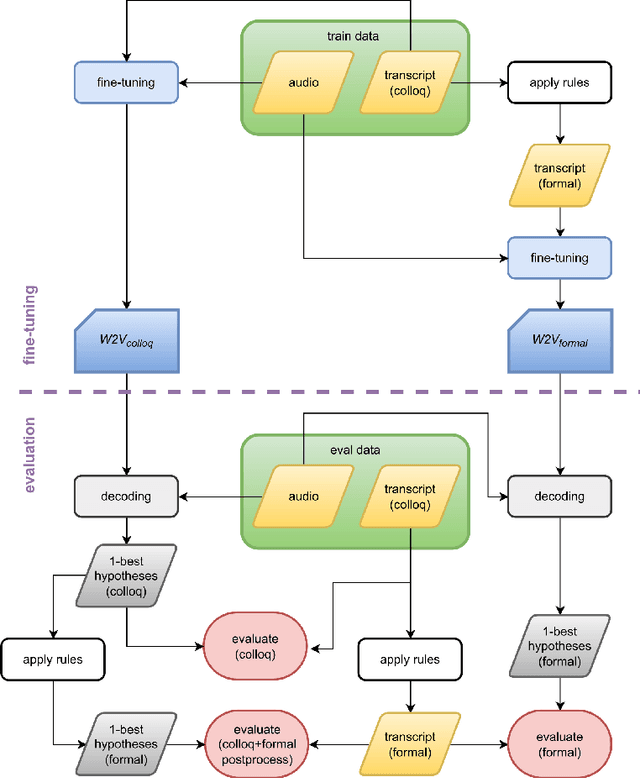

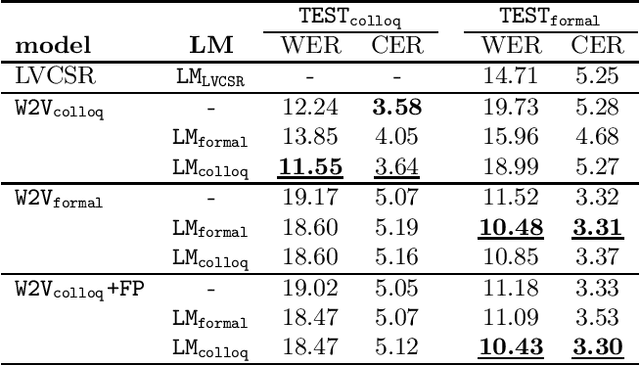
Czech is a very specific language due to its large differences between the formal and the colloquial form of speech. While the formal (written) form is used mainly in official documents, literature, and public speeches, the colloquial (spoken) form is used widely among people in casual speeches. This gap introduces serious problems for ASR systems, especially when training or evaluating ASR models on datasets containing a lot of colloquial speech, such as the MALACH project. In this paper, we are addressing this problem in the light of a new paradigm in end-to-end ASR systems -- recently introduced self-supervised audio Transformers. Specifically, we are investigating the influence of colloquial speech on the performance of Wav2Vec 2.0 models and their ability to transcribe colloquial speech directly into formal transcripts. We are presenting results with both formal and colloquial forms in the training transcripts, language models, and evaluation transcripts.
Exploring Capabilities of Monolingual Audio Transformers using Large Datasets in Automatic Speech Recognition of Czech
Jun 15, 2022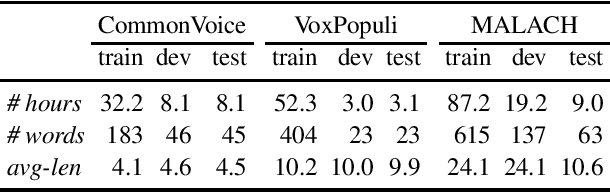



In this paper, we present our progress in pretraining Czech monolingual audio transformers from a large dataset containing more than 80 thousand hours of unlabeled speech, and subsequently fine-tuning the model on automatic speech recognition tasks using a combination of in-domain data and almost 6 thousand hours of out-of-domain transcribed speech. We are presenting a large palette of experiments with various fine-tuning setups evaluated on two public datasets (CommonVoice and VoxPopuli) and one extremely challenging dataset from the MALACH project. Our results show that monolingual Wav2Vec 2.0 models are robust ASR systems, which can take advantage of large labeled and unlabeled datasets and successfully compete with state-of-the-art LVCSR systems. Moreover, Wav2Vec models proved to be good zero-shot learners when no training data are available for the target ASR task.