 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Bilingual and Trilingual Wav2Vec Models for Automatic Speech Recognition in Multilingual Oral History Archives
Jul 24, 2024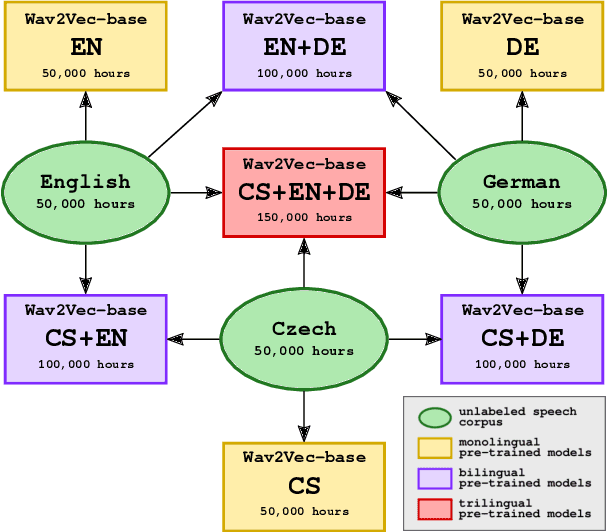
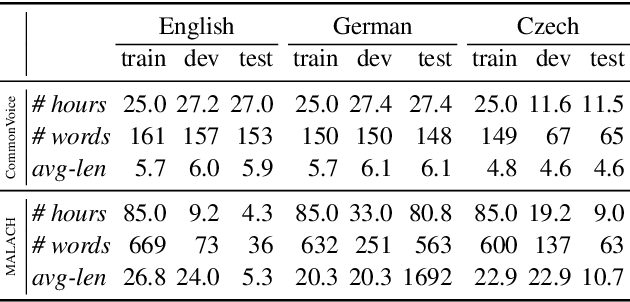
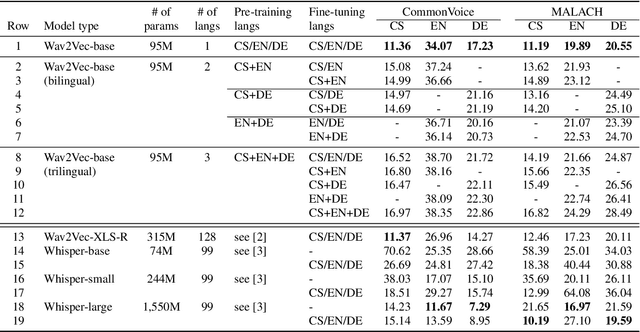
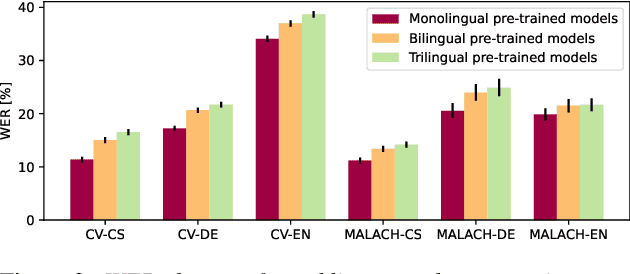
In this paper, we are comparing monolingual Wav2Vec 2.0 models with various multilingual models to see whether we could improve speech recognition performance on a unique oral history archive containing a lot of mixed-language sentences. Our main goal is to push forward research on this unique dataset, which is an extremely valuable part of our cultural heritage. Our results suggest that monolingual speech recognition models are, in most cases, superior to multilingual models, even when processing the oral history archive full of mixed-language sentences from non-native speakers. We also performed the same experiments on the public CommonVoice dataset to verify our results. We are contributing to the research community by releasing our pre-trained models to the public.
Transfer Learning of Transformer-based Speech Recognition Models from Czech to Slovak
Jun 07, 2023In this paper, we are comparing several methods of training the Slovak speech recognition models based on the Transformers architecture. Specifically, we are exploring the approach of transfer learning from the existing Czech pre-trained Wav2Vec 2.0 model into Slovak. We are demonstrating the benefits of the proposed approach on three Slovak datasets. Our Slovak models scored the best results when initializing the weights from the Czech model at the beginning of the pre-training phase. Our results show that the knowledge stored in the Cezch pre-trained model can be successfully reused to solve tasks in Slovak while outperforming even much larger public multilingual models.
Transformer-based Automatic Speech Recognition of Formal and Colloquial Czech in MALACH Project
Jun 15, 2022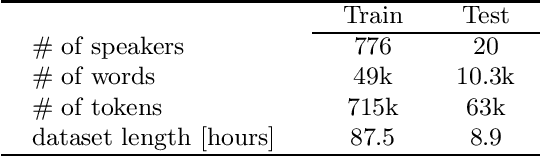
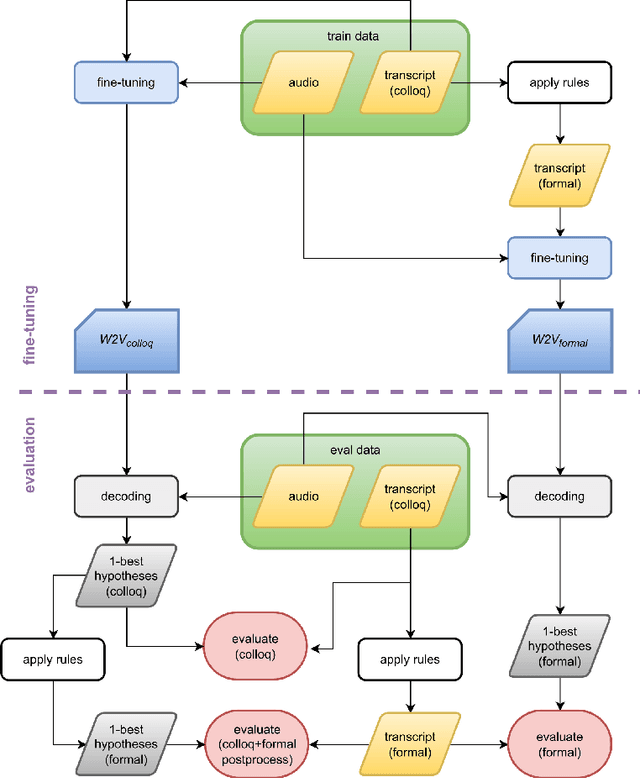

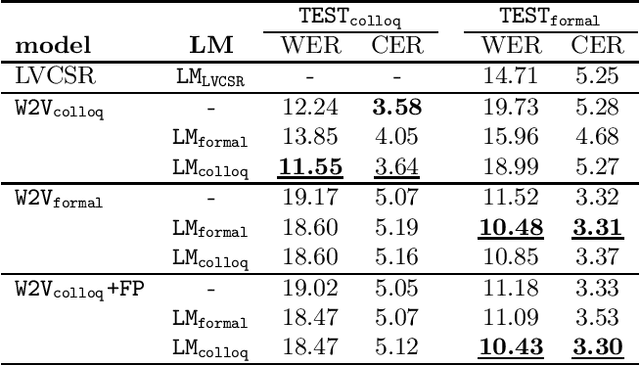
Czech is a very specific language due to its large differences between the formal and the colloquial form of speech. While the formal (written) form is used mainly in official documents, literature, and public speeches, the colloquial (spoken) form is used widely among people in casual speeches. This gap introduces serious problems for ASR systems, especially when training or evaluating ASR models on datasets containing a lot of colloquial speech, such as the MALACH project. In this paper, we are addressing this problem in the light of a new paradigm in end-to-end ASR systems -- recently introduced self-supervised audio Transformers. Specifically, we are investigating the influence of colloquial speech on the performance of Wav2Vec 2.0 models and their ability to transcribe colloquial speech directly into formal transcripts. We are presenting results with both formal and colloquial forms in the training transcripts, language models, and evaluation transcripts.
A Comparison of Adaptation Techniques and Recurrent Neural Network Architectures
Jul 12, 2018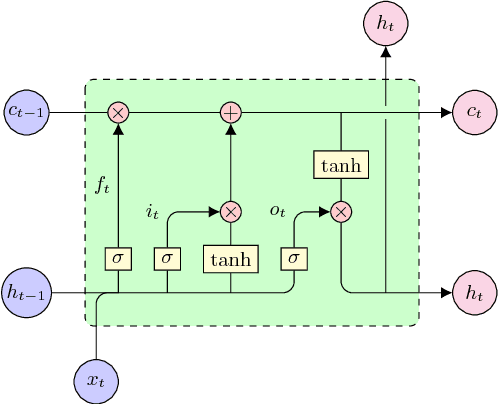
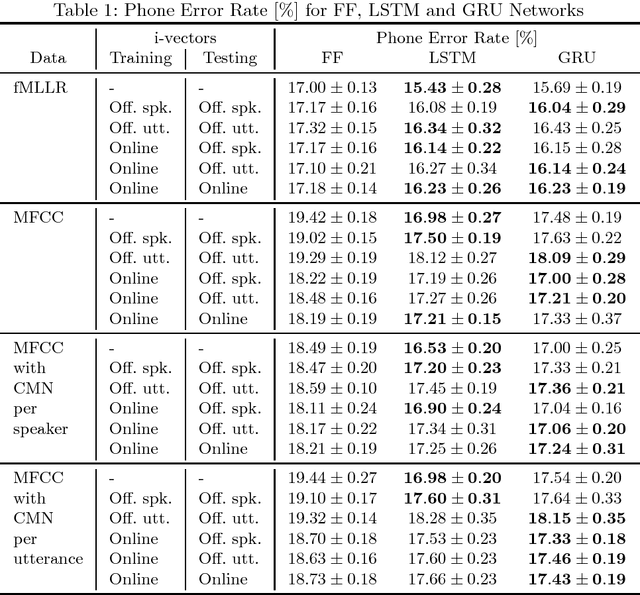

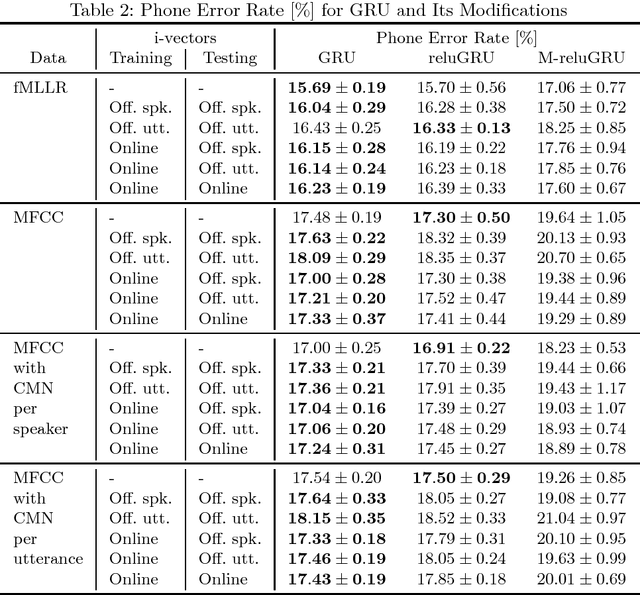
Recently, recurrent neural networks have become state-of-the-art in acoustic modeling for automatic speech recognition. The long short-term memory (LSTM) units are the most popular ones. However, alternative units like gated recurrent unit (GRU) and its modifications outperformed LSTM in some publications. In this paper, we compared five neural network (NN) architectures with various adaptation and feature normalization techniques. We have evaluated feature-space maximum likelihood linear regression, five variants of i-vector adaptation and two variants of cepstral mean normalization. The most adaptation and normalization techniques were developed for feed-forward NNs and, according to results in this paper, not all of them worked also with RNNs. For experiments, we have chosen a well known and available TIMIT phone recognition task. The phone recognition is much more sensitive to the quality of AM than large vocabulary task with a complex language model. Also, we published the open-source scripts to easily replicate the results and to help continue the development.
Recurrent DNNs and its Ensembles on the TIMIT Phone Recognition Task
Jun 19, 2018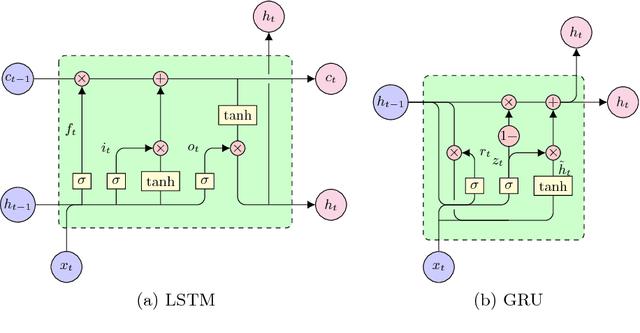
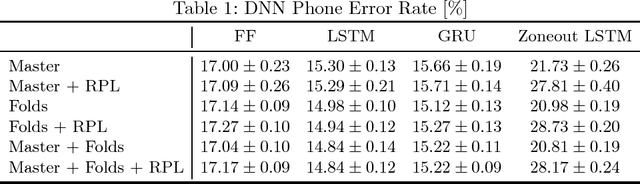
In this paper, we have investigated recurrent deep neural networks (DNNs) in combination with regularization techniques as dropout, zoneout, and regularization post-layer. As a benchmark, we chose the TIMIT phone recognition task due to its popularity and broad availability in the community. It also simulates a low-resource scenario that is helpful in minor languages. Also, we prefer the phone recognition task because it is much more sensitive to an acoustic model quality than a large vocabulary continuous speech recognition task. In recent years, recurrent DNNs pushed the error rates in automatic speech recognition down. But, there was no clear winner in proposed architectures. The dropout was used as the regularization technique in most cases, but combination with other regularization techniques together with model ensembles was omitted. However, just an ensemble of recurrent DNNs performed best and achieved an average phone error rate from 10 experiments 14.84 % (minimum 14.69 %) on core test set that is slightly lower then the best-published PER to date, according to our knowledge. Finally, in contrast of the most papers, we published the open-source scripts to easily replicate the results and to help continue the development.